A.2 RL 训练系统底座 与 Rollout、Buffer 与分布式
前面章节更多关注算法:策略梯度怎么写,PPO/GRPO 怎么更新,reward 从哪里来。进入工业训练以后,问题会多一层:训练样本不是躺在磁盘里的固定数据,而是训练过程中被当前策略不断生产出来的。
监督学习的数据集像固定题库,训练程序只需要一批一批把题目读出来。RL(强化学习)不同。模型每训练一段时间,策略都会变化;策略一变,后面采到的数据也会变化。
例如在 LLM RL(大语言模型的强化学习)里,语言模型先对一个数学题生成多条回答,规则、verifier 或 judge 再给这些回答打分。又比如在 CartPole 里,策略先输出一个 action,环境再返回新的 observation 和 reward。两种任务表面很不一样,但背后的系统问题是同一个:
谁在生产训练样本?样本以什么单位流动?训练端能不能及时消费?旧策略生成的数据还能不能继续用?
这就是 RL 采样基础设施要解决的问题。
本节把原来的“采样基础设施”“异步训练架构”“分布式并行策略”合并到同一条主线里:首先建立“生产者、缓冲区、消费者、权重回流”的数据流水线;然后进入 LLM RL,按推理/rollout 层、训练/编排层依次讨论 vLLM/SGLang 与 OpenRLHF、veRL、slime;再以非 LLM RL 作对照,说明 Gymnasium、IMPALA、Sample Factory、Isaac Gym 所处的层级;最后讨论异步训练和多卡并行如何把这条流水线真正跑起来。这里讨论的是所有后续 RL 工程都会复用的训练系统底座;当模型开始执行工具、读写文件、运行代码或进行多轮环境交互时,新增的沙箱、轨迹存储和工具调度问题放到 B.2 Agentic RL 基础设施。
先讲训练底座
B.1 关心的是:样本如何被生产、排队、消费,权重如何回流,模型如何切到多张 GPU 上。它默认采样端主要是文本生成引擎、仿真环境或 Actor worker。
| 本页展开 | 本页只点到为止 |
|---|---|
| LLM rollout engine 的 token 生成、KV cache、长尾输出 | Agent 执行代码、读写文件、访问网络的沙箱隔离 |
| OpenRLHF、veRL、slime 这类训练编排框架 | 多轮工具调用轨迹、对话树和环境快照存储 |
| rollout/training 异步、buffer、policy version、staleness | 单条 Agent 轨迹内部的工具等待和批内流水线调度 |
| FSDP、ZeRO、TP、PP、EP 等分布式训练和显存优化 | Web/代码/多模态 Agent 的环境接口与可复现性 |
一个简单判断是:如果任务还是“模型生成 completion,然后 verifier 或 reward 给分”,主要看 B.1;如果模型的 action 会离开 GPU,去调用工具、改文件、跑测试、查网页或跨多轮维护环境状态,就进入 B.2。
RL 训练的数据流水线
RL 训练最基本的数据流如下:
生产者产生样本 → 缓冲区暂存样本 → 消费者训练模型 → 新权重回到生产者在 LLM RL 中,生产者通常是 vLLM/SGLang 这样的 rollout engine;消费者通常是 OpenRLHF、veRL、slime 等训练框架里的 trainer。在非 LLM RL 中,生产者通常是环境、仿真器或 Actor;消费者通常是 Learner。后面的系统图都围绕这条“生产、暂存、消费、回流”的流水线展开。
先把流水线里的几个名字对齐:
| 术语 | 含义 |
|---|---|
| policy / 策略 | 当前正在训练的模型或规则。它决定下一步 action,或决定语言模型下一段回答怎么生成。 |
| environment / 环境 | 接收 action 并返回 observation、reward 的外部系统,例如游戏、机器人仿真器或任务环境。 |
| observation / action / reward | observation 是环境状态,action 是策略采取的动作,reward 是环境给出的分数。 |
| transition | 一步交互记录,通常包含当前状态、动作、奖励和下一状态。 |
| episode | 从一次 reset 到任务结束的一整段交互。 |
| trajectory / rollout | 一串连续样本。非 LLM RL 中通常是一段环境轨迹;LLM RL 中通常是 prompt 到 completion 的生成过程。 |
| token / completion | token 是语言模型一次生成的最小文本单位,completion 是模型对 prompt 生成的完整回答。 |
| Actor / rollout worker | 负责生产样本的 worker。它不断与环境交互,或调用模型生成回答。 |
| Learner / Trainer | 负责消费样本并更新模型参数的 worker。 |
| Buffer / Queue | 暂存样本的地方。队列越深,吞吐可能越高,但样本也可能越旧。 |
| weight sync / 权重同步 | Trainer 更新模型后,把新权重传回采样端。 |
| on-policy / off-policy | on-policy 表示样本来自当前策略;off-policy 表示样本来自旧策略。 |
| KV cache | LLM 生成时保存的中间计算结果,用来避免重复计算前面的 token。 |
LLM RL 与非 LLM RL
RL 采样基础设施按训练对象分为两类:LLM RL 与 非 LLM RL。两类系统的数据来源、数据单位和主要瓶颈不同。
| 大类 | 数据来源 | 数据单位 | 主要瓶颈 |
|---|---|---|---|
| LLM RL | 语言模型生成 completion,reward/verifier/judge 打分 | token、completion、rollout batch | 逐 token 生成、KV cache、长尾输出、权重同步、旧策略样本 |
| 非 LLM RL | 环境或仿真器返回 observation / reward | transition、episode、trajectory | 环境 step、仿真吞吐、Actor/Learner 同步 |
每一类系统都包含两个职责层:推理/采样层 负责产生可训练样本,训练/编排层 负责消费样本、更新参数,并把新权重同步回采样端。LLM RL 的第一瓶颈通常在回答生成,因此推理/rollout 层排在前面;训练/编排层随后负责把 rollout、reward、buffer 和 weight sync 串起来。
| 大类 | 推理/采样工具 | 训练/编排工具 |
|---|---|---|
| LLM RL | vLLM、SGLang | OpenRLHF、veRL、slime |
| 非 LLM RL | Gymnasium VectorEnv、IMPALA Actor、Sample Factory rollout worker、Isaac Gym 仿真环境 | IMPALA Learner、Sample Factory Learner |
LLM RL 的推理层围绕 rollout engine 展开,vLLM 和 SGLang 负责高吞吐生成 token;训练/编排层围绕后训练框架展开,OpenRLHF、veRL 和 slime 负责编排 rollout、reward、buffer、trainer 与权重同步。非 LLM RL 的采样层围绕环境接口、Actor、rollout worker 和仿真器展开,训练/编排层通常由 Learner 消费 trajectory 并更新策略。
为什么采样端决定 RL 系统上限
监督学习的训练循环是静态的:
数据集 → DataLoader → 前向 → 反向 → 更新RL 的训练循环是动态的:
策略采样 → 环境/生成器产生反馈 → 收集轨迹 → 计算奖励 → 更新策略 → 用新策略重新采样DataLoader 在这里相当于把样本送进训练循环的“搬运工”。监督学习中的 DataLoader 主要从磁盘读取已有样本;RL 中的 DataLoader 本身就是一个在线系统。它不仅要读数据,还要运行策略、推进环境、生成文本、计算奖励、记录轨迹、处理 episode 结束,再把这些数据交给 learner。
因此 RL 系统吞吐由三类速率共同决定:
- 采样端产出数据的速度:
steps/s、tokens/s、samples/s - 训练端消化数据的速度:batch size、反向传播、并行策略
- 反馈端返回奖励的速度:规则判题、Reward Model(奖励模型)、LLM-as-Judge(用大模型打分)、代码执行、环境 step
任一环节成为瓶颈,都会限制整条训练链路的吞吐。在两类任务中,瓶颈位置如下。
| 大类 | 推理/采样层瓶颈 | 训练/编排层瓶颈 | 样本新鲜度问题 |
|---|---|---|---|
| LLM RL | 逐 token decode、KV cache、长尾 completion、批量生成调度 | reward/verifier、PPO/GRPO 训练、buffer、weight sync | rollout batch 可能由旧 actor 生成,异步队列越深越容易 off-policy |
| 非 LLM RL | 环境 step()、物理仿真、Actor 数量、CPU/GPU 数据搬运 | Learner 反向传播、Actor/Learner 同步、参数广播 | Actor 使用旧策略采样,trajectory 可能产生 policy lag(策略滞后) |
一、LLM RL 与 先解决推理,再解决训练编排
LLM RL 的训练数据来自当前语言模型对 prompt 的生成。模型输出 completion(完整回答)后,再由规则、Reward Model、LLM-as-Judge 或 verifier(验证器)给出奖励。此时“采样基础设施”的核心不再是环境 step,而是文本 rollout、奖励计算、权重同步和策略版本管理。
LLM RL 基础设施由两类系统组成:
| 子类 | 职责 | 代表 |
|---|---|---|
| 推理/rollout 工具 | 高吞吐生成 token,管理 KV cache、batch 调度、长尾输出、权重加载 | vLLM、SGLang |
| 训练/编排工具 | 编排 rollout、reward、training、buffer、weight sync 和并行策略 | OpenRLHF、veRL、slime |
1.1 推理/rollout 层 与 训练循环中的推理引擎
在 LLM RL 中,rollout engine 是面向训练的“批量生成器”。它并非一般意义上的在线推理服务。在线服务面向用户请求;RL 后训练中的 rollout engine 面向训练循环。它不仅要生成文本,还要执行采样策略、记录策略版本、配合奖励计算、接收新权重,并将可训练数据交给后续 buffer 和 trainer。
一个 LLM RL step 的基本数据流如下:
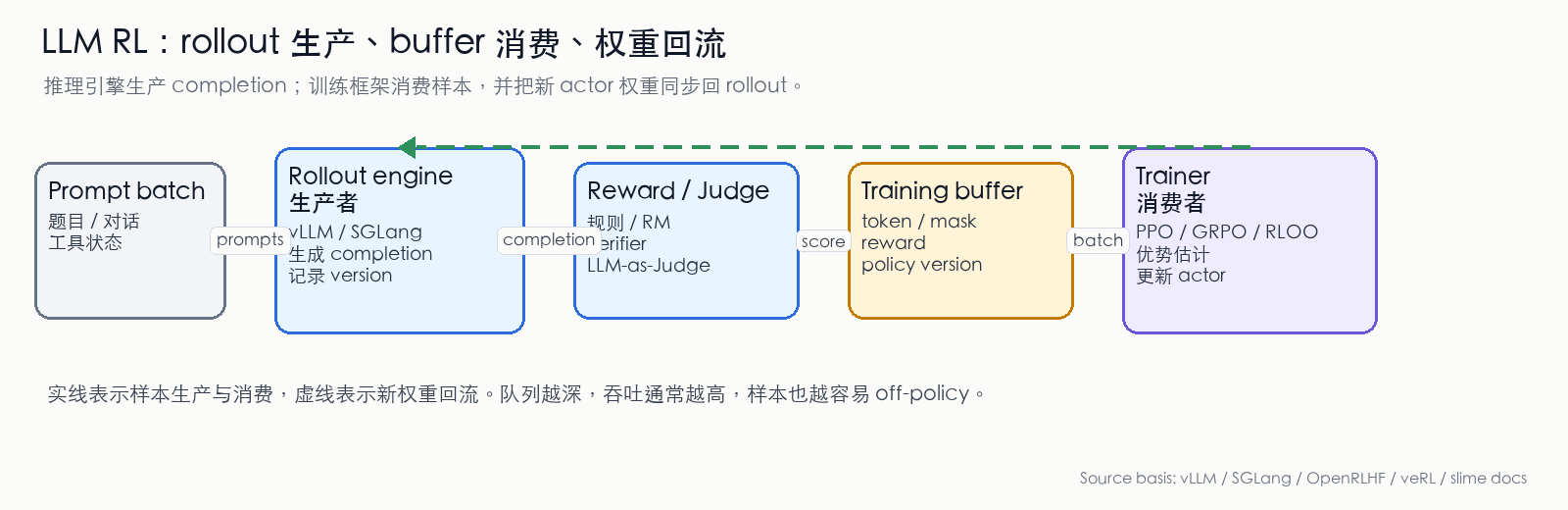
图 1:LLM RL 的生产/消费流水线。Rollout engine 生产 completion,reward/verifier/judge 生产分数,training buffer 把 token、mask、reward 和 policy version 组织成 batch,trainer 消费 batch 并把新 actor 权重同步回 rollout engine。实线表示样本流,虚线表示权重回流。(依据 vLLM、SGLang、OpenRLHF、veRL、slime 文档整理 [1][2][3][4][5])
rollout engine 至少要产出这些信息:
- token ids:回答被切成 token 后的编号,训练 loss 需要逐 token 对齐
- attention mask / response mask:标记哪些位置是 prompt、response、padding 或截断位置
- finish reason:记录回答是正常结束、长度截断、遇到 stop token,还是被工具调用中断
- sampling metadata:记录 temperature、top-p、top-k、seed,以及每个 prompt 采样多少条回答
- policy version:记录这批样本由哪个版本的 actor 生成
- 可选的 logprob:记录模型当时给每个 token 的概率。有些系统直接从推理端取 old logprob,有些系统在训练端重新计算,以减少推理/训练 kernel 差异带来的不一致
由此可见,在线推理服务交付的是答案;LLM RL 的 rollout engine 交付的是可训练的轨迹样本。
1.2 推理/rollout 层 与 在线服务范式的局限
LLM serving 指面向用户的在线聊天或 API 服务。LLM serving 和 LLM RL rollout 都依赖推理引擎,但优化目标不同:
| 维度 | 在线 serving | RL rollout engine |
|---|---|---|
| 第一目标 | 用户延迟和 SLA | 单位时间产出可训练样本 |
| 请求形态 | 用户请求随机到达 | trainer 批量下发 prompt,常常每个 prompt 生成多条回答 |
| 输出长度 | 受产品交互约束 | 常有长推理、长代码、长 CoT、长尾样本 |
| 状态管理 | 通常固定权重服务 | 权重会周期性更新,需要版本管理 |
| 正确性要求 | 文本结果正确即可 | token、mask、logprob、版本号都要和训练对齐 |
| 调度问题 | p50/p99 latency,即大多数请求和最慢一批请求的延迟 | tokens/s、samples/s、长尾拖批、GPU 利用率 |
GRPO 中常见的 num_generations=8 或 16 会让同一个 prompt 生成多条回答。数学题、代码题、长推理题的回答长度差异很大:短样本很快结束,长样本仍在 decode。一个 batch 的训练数据通常要等待最慢的 completion 返回;少数特别长的回答就是“长尾”,它们会直接拖慢训练。
1.3 推理/rollout 层 与 Prefill、decode、KV cache 与长尾输出
LLM 生成可以拆成两段:
- Prefill:处理 prompt,计算初始 KV cache。它更偏计算密集,prompt 长时成本高。
- Decode:逐 token 生成 response。它更偏 memory bandwidth 和调度,输出越长越容易被长尾拖慢。
直观地说,prefill 像先把题目读完并记下中间结果;decode 像根据这些中间结果一个 token 一个 token 写答案。
RL rollout 会放大这两个问题:
- 共享前缀较多。同一批 prompt 可能共享 system prompt、few-shot 示例、题面模板,甚至同一个题目会采样多条回答。Prefix cache 命中率直接影响 prefill 成本。
- 输出长度分布重尾。多数回答可能几百 token,少数回答会生成几千 token。batch 内最长样本决定何时能交付完整 rollout batch。
- KV cache 占用随并发和上下文增长。KV cache 是生成时保存的中间结果,大小和模型层数、head 数、序列长度、并发请求数相关。显存不足时,吞吐会突然下降,甚至触发抢占或重算。
- 权重会更新。serving 可以长期固定一个 checkpoint,RL rollout 侧却需要频繁接收 trainer 的新权重。更新太慢会导致 rollout GPU 空等;更新太快则可能使正在生成的样本跨策略版本。
vLLM 的 PagedAttention 把 KV cache 按 block 管理,避免为每条请求预留连续的大块显存,从而提升动态批处理时的显存利用率和吞吐 [6][7]。
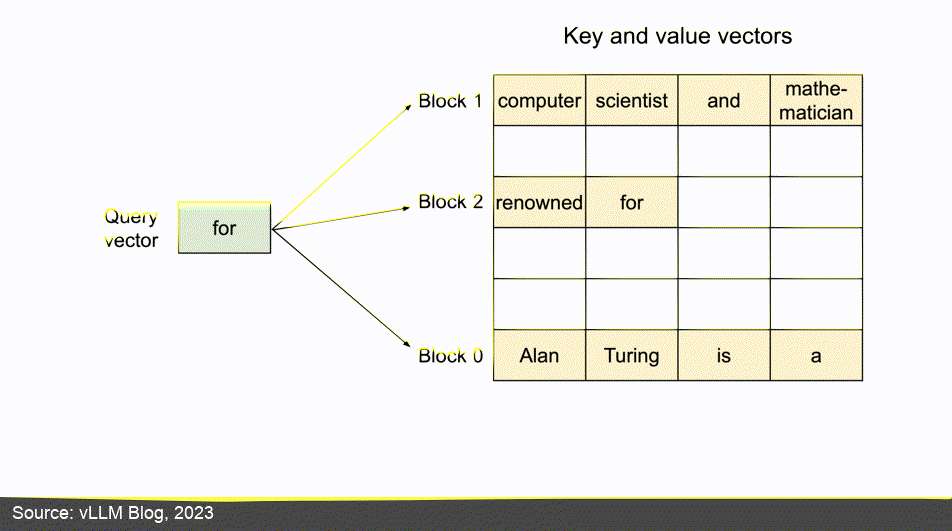
图 2:vLLM 官方博客中的 PagedAttention 动图。对 LLM RL 来说,rollout 吞吐很大程度取决于 KV cache 管理、连续批处理和长输出调度。(来源:vLLM 官方博客 [7:1])
SGLang 也把这类问题作为核心能力来做:RadixAttention 用于复用共享前缀,router/gateway 负责把请求分配到多个推理实例,PD disaggregation 把 prefill 和 decode 拆到不同执行资源上,RL 系统接口则直接关注权重更新、pause generation、deterministic inference 等训练场景需求 [2:1][8][9]。
1.4 推理/rollout 层 与 核心职责
在 LLM RL 系统中,rollout engine 通常承担五类职责。
第一,批量生成。 该组件需要把大量 prompt 组织成高吞吐请求,同时支持每个 prompt 生成多条回答。关键不在于是否能调用 generate,而在于如何组织 prefill、decode、padding、stop condition 和 batch 调度。
第二,KV cache 管理。 PagedAttention、prefix caching、RadixAttention、chunked prefill、KV eviction 等能力都会直接影响 tokens/s 和显存占用。对 RL 来说,prompt 模板和多样本采样会带来许多可复用前缀,因此 cache 命中率并非边缘优化。
第三,长尾控制。 RL rollout 通常并非单条请求结束即可返回,而是需要形成可用于训练的 batch。少数超长回答会拖慢整批数据交付。工程上常用最大长度、early stop、分桶调度、partial batch return、异步队列来降低长尾影响。
第四,权重生命周期。 Trainer 更新 actor 后,rollout engine 要接收新权重。这个过程可能涉及张量并行格式、FSDP/Megatron 分片格式、LoRA adapter、GPU 间通信、sleep/wake、pause/resume generation。vLLM 文档专门把 RLHF 场景和 sleep mode、权重同步放在一起讨论 [1:1][10]。
第五,版本和一致性。 rollout 侧生成样本时用的是旧策略还是新策略,必须被记录下来。严格 on-policy 时,旧数据要丢弃;异步训练时,旧数据可以保留,但要通过 staleness(样本有多旧)、importance sampling(重要性采样)、KL 或截断权重控制风险。后文的“异步训练架构”会继续展开这个问题。
1.5 推理/rollout 层 与 vLLM 与 SGLang
vLLM 和 SGLang 都可以作为 LLM RL 的 rollout engine,但工程侧重点不同:
| 系统 | 更突出的能力 | 在 RL rollout 中的意义 |
|---|---|---|
| vLLM | PagedAttention、continuous batching、并行采样、prefix caching、sleep mode、RLHF 集成 | 作为通用高吞吐 rollout engine,容易接入 OpenRLHF、veRL 等框架 |
| SGLang | RadixAttention、structured generation、router/gateway、PD disaggregation、RL 系统接口 | 适合长上下文、多轮交互、MoE、SGLang-native 后训练系统 |
OpenRLHF 常见组合是 Ray + vLLM + DeepSpeed;veRL 同时支持 vLLM、SGLang、HF Transformers 等 rollout 后端;slime 则把 SGLang 作为原生 rollout 层。在这一分层中,vLLM/SGLang 位于生成引擎层,TRL/OpenRLHF/veRL/slime 位于训练编排层。
1.6 训练/编排层 与 TRL 的单机研究原型
TRL(Transformer Reinforcement Learning)是 HuggingFace 生态内的 RL 训练库 [11]。前面各章的 DPO(第 2 章)和 GRPO(第 7 章)实验都用 TRL 完成。它的定位和前面三个框架不同:TRL 不是分布式编排系统——它不做 Ray 调度,不做 rollout engine 与 trainer 的进程分离,也不做跨 GPU 的 weight sync。它把 DPO/PPO/GRPO/REINFORCE++ 的训练循环封装成 DPOTrainer、GRPOTrainer 等 Trainer 类,在单机或少量 GPU 上运行 [11:1]。
这意味着 TRL 的内部数据流比 OpenRLHF/veRL/slime 简单得多:
模型生成 completion → reward/verifier 打分 → Trainer 计算 loss → 反向传播更新参数没有独立的 rollout workers,没有跨进程的 buffer queue,没有 weight sync。生成和训练在同一个 Python 进程内完成。优点是上手成本低——前面章节的实验已经展示了这一点。代价是吞吐上限受单机约束,且无法解耦生成与训练的调度。
TRL 适合两类场景:(1) 算法研究和快速验证——修改 reward 函数、尝试新的 loss 设计、验证数据质量;(2) 小规模生产——单卡或少量 GPU 上的 SFT/DPO/GRPO 训练。当训练规模需要跨多机、rollout 和训练需要分离调度时,就进入 OpenRLHF/veRL/slime 的范畴。
ms-swift(ModelScope Swift)的定位与 TRL 类似,但面向国产模型生态 [12]。它把 SFT/DPO/GRPO/RLHF 的全流程打包成一个 CLI 工具,模型和数据集直接从 ModelScope Hub 加载,训练结果也可以一键部署到 ModelScope 推理服务。适合不想自己组装训练流水线、希望开箱即用的场景。
| 框架 | 生态 | 分布式能力 | 适用规模 | 典型用途 |
|---|---|---|---|---|
| TRL | HuggingFace | 单机 / accelerate | 单卡 ~ 少量卡 | 算法研究、快速验证、教学实验 |
| ms-swift | ModelScope | 单机 / 少量卡 | 单卡 ~ 少量卡 | 开箱即用全流程、国产模型适配 |
| OpenRLHF | Ray + vLLM | Ray 集群 | 多机多卡 | 中等规模 PPO/GRPO 生产训练 |
| veRL | 可组合后端 | FSDP / Megatron | 多机多卡 | 可定制训练流、替换 rollout 后端 |
| slime | Megatron | Megatron + SGLang | 大规模集群 | 大规模 MoE、长尾 rollout 优化 |
| Miles | Megatron | Megatron + SGLang | 大规模集群 | 企业级长周期 MoE 后训练 |
1.7 训练/编排层 与 OpenRLHF、veRL、slime
OpenRLHF、veRL、slime 位于同一系统层级。它们通常会调用 vLLM 或 SGLang 做 rollout,但自身并不是单纯的推理引擎。它们更像流水线总控,负责把生成、打分、训练、样本缓存和权重同步串起来:
- Rollout workers:批量生成回答,接 vLLM、SGLang 或其他推理后端
- Reward/Judge workers:给回答打分,来源可以是规则、奖励模型、LLM-as-Judge 或代码执行
- Training workers:根据 PPO/GRPO/RLOO/REINFORCE++ 等算法计算 loss,完成反向传播和参数更新
- Buffer/Queue:缓存样本,记录策略版本,控制旧数据比例
- Weight sync:把 trainer 的新权重同步到 rollout 侧
PPO/GRPO 在算法公式里主要表现为 loss、优势估计和约束项;在真实系统中,后训练框架的差异主要体现在四个平面:
| 平面 | 要解决的问题 |
|---|---|
| Rollout plane | 用哪个推理引擎,如何生成、截断、重试、并发、处理长尾 |
| Reward plane | 奖励来自规则、RM、Judge 还是 verifier,打分是否会成为新瓶颈 |
| Training plane | 用 DeepSpeed、FSDP、Megatron-LM 还是自研训练栈,这些组件负责大模型训练 |
| Data / Weight plane | 样本如何入队、是否流式、权重如何同步、旧样本如何处理 |
HybridFlow 论文里的框架对比表按这些维度比较 DeepSpeed-Chat、OpenRLHF、NeMo-Aligner 和 HybridFlow:parallelism(并行策略)、actor weights(actor 权重保存方式)、model placement(模型放在哪些 GPU 上)和 execution pattern(执行顺序)[13]。
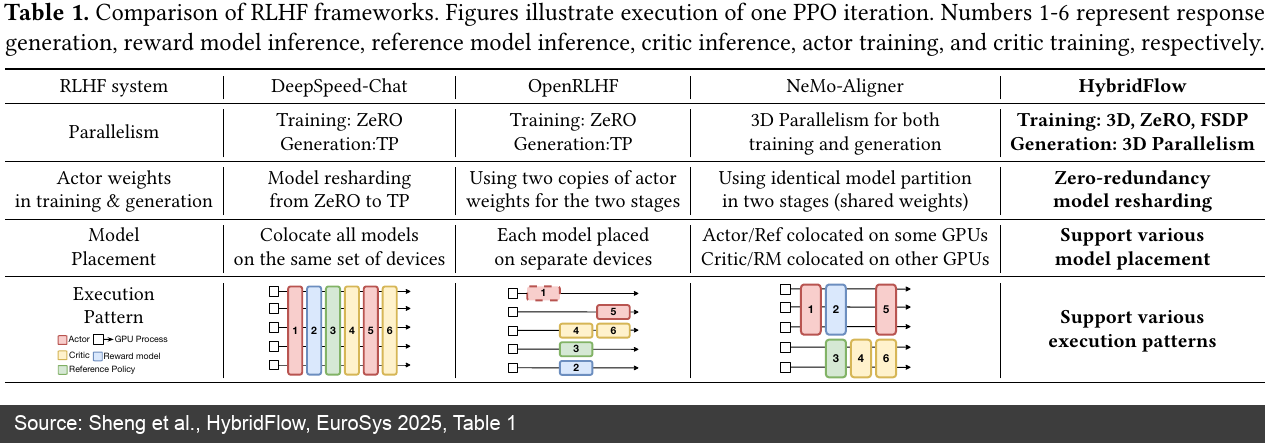
图 3:HybridFlow 论文对 RLHF 框架执行模式的比较。OpenRLHF 用分离设备和两份 actor weights 换取生成/训练并行;HybridFlow 进一步强调 zero-redundancy model resharding 和 flexible placement。(来源:HybridFlow 论文 [13:1])
1.8 训练/编排层 与 OpenRLHF 的 Ray + vLLM + DeepSpeed
OpenRLHF 的技术报告和 README 把它描述为 Ray + vLLM 分布式架构:Ray 负责把不同 worker 调度到不同机器或 GPU 上,vLLM 做 rollout 推理,DeepSpeed 做 Actor/Critic/Reward/Reference 等模型训练和推理,Transformers 负责模型格式和状态对接,底层通过 NCCL / CUDA IPC 做高速通信 [14][3:1]。
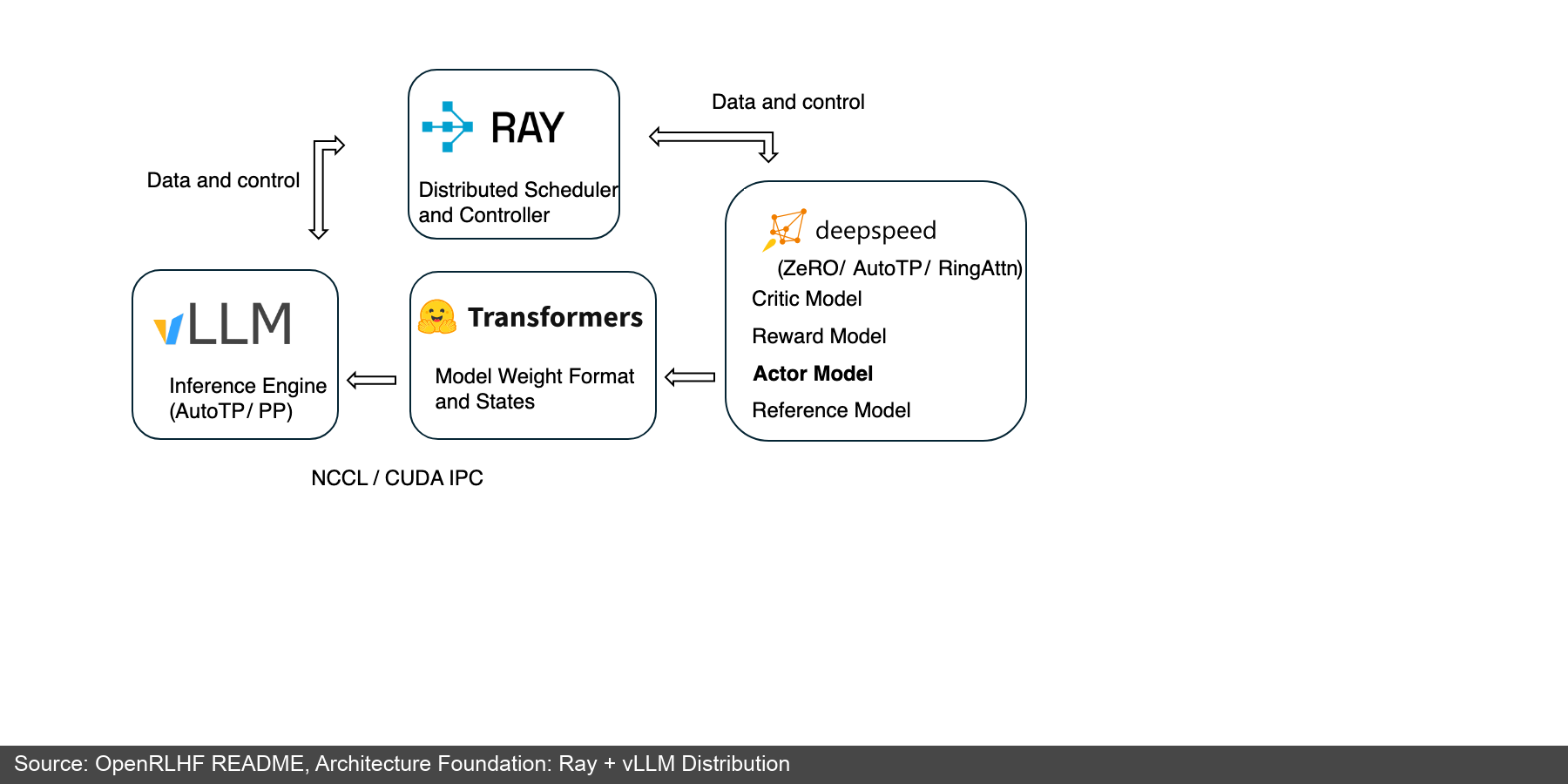
图 4:OpenRLHF README 中的 Ray + vLLM 架构图。它体现了 LLM RL 的常见拆法:调度层、推理引擎、训练引擎、模型权重格式、GPU 间通信。(来源:OpenRLHF README [3:2])
图 4 体现的关键边界包括:
- Ray 负责把 Actor、Critic、Reward、Reference、vLLM engine 等组件调度到不同 GPU 上
- vLLM 负责高吞吐生成,是 rollout 侧核心
- DeepSpeed 负责训练侧的显存优化和分布式反向传播
- Transformers 作为权重格式和模型状态的桥
- NCCL / CUDA IPC 负责权重同步和 GPU 间传输
OpenRLHF 的实用价值在于它把几种常见部署方式做成了显式参数。表中的 colocated 表示“生成和训练共用同一组 GPU”,async 表示“生成和训练并发运行”。
| 模式 | 典型参数 | 工程含义 | 风险 |
|---|---|---|---|
| Hybrid Engine / colocated | --train.colocate_all、--vllm.enable_sleep | 同一组 GPU 在生成和训练之间切换,尽量省卡 | 严格串行,吞吐受 rollout 长尾影响 |
| Async Training | --train.async_enable、--train.async_queue_size | rollout 和 training 并发执行,队列越大吞吐越高 | 队列越深,样本越 off-policy |
| Async + Partial Rollout | --train.partial_rollout_enable | 利用 vLLM pause/resume,让权重同步不完全阻塞生成 | in-flight 样本可能混合新旧权重 |
这三个模式对应工业训练中的核心矛盾:省 GPU、严格 on-policy、高吞吐三者很难同时满足。OpenRLHF 倾向于把这些选择暴露给用户。研究阶段可以用 colocated 保证稳定性;吞吐优化阶段再打开 async;如果能接受更复杂的 off-policy 修正,再尝试 partial rollout 和重要性采样校正 [15]。
1.9 训练/编排层 与 veRL 的 HybridFlow 执行流
veRL 是 HybridFlow 论文的开源实现。它强调 single-controller(单控制器)编排、可组合的 model engine / rollout engine,以及用队列把 rollout 和 training 解耦 [13:2][4:1]。
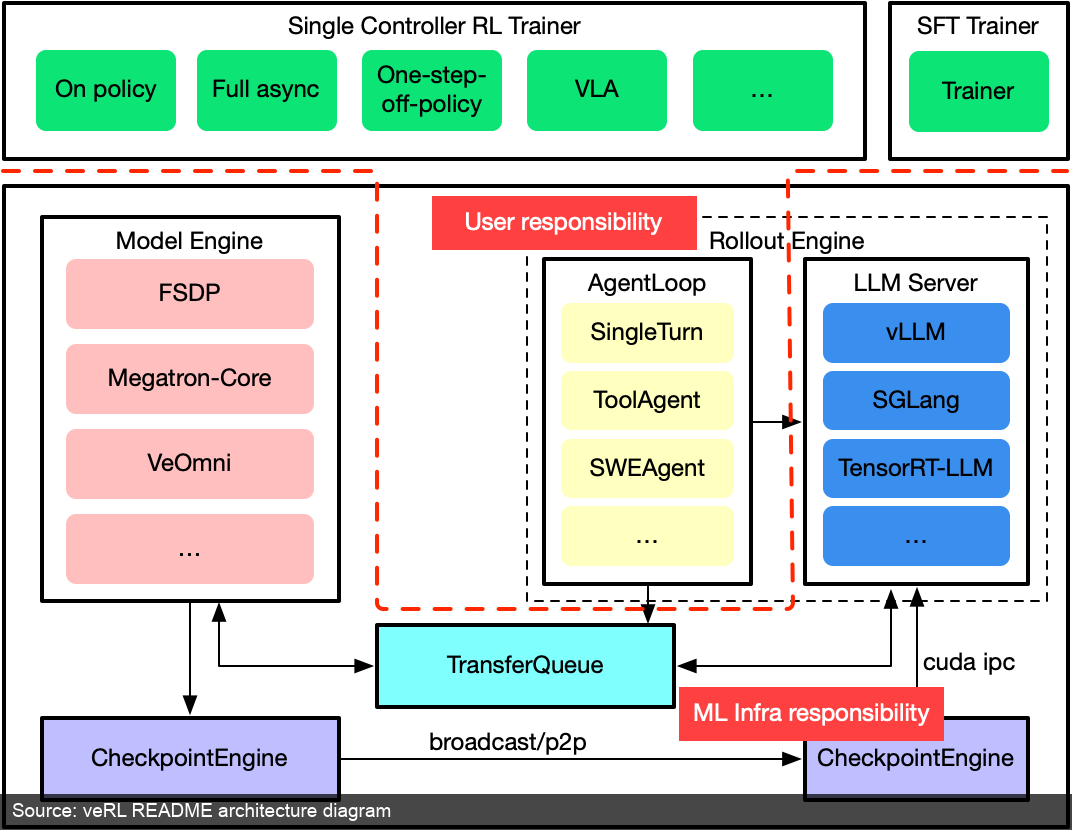
图 5:veRL README 中的架构图。图中的 TransferQueue、Rollout Engine、Model Engine 和 CheckpointEngine 对应了 LLM RL 系统里的数据流、推理流、训练流和权重同步。(来源:veRL README [4:2])
图 5 展示了 veRL 对 LLM RL 执行流的拆分方式。Rollout engine 可能接 vLLM、SGLang 或 TensorRT-LLM;Model engine 可能接 FSDP、Megatron-Core 或其他训练后端;TransferQueue 负责把生成样本流式送到训练侧;CheckpointEngine 则负责保存和广播新权重。
veRL 的重点是把 RL 训练抽象成一组可组合 worker。README 中强调 hybrid-controller programming model、flexible device mapping,以及与 FSDP/FSDP2、Megatron-LM、vLLM、SGLang、HF Transformers 等已有 LLM infra 的模块化集成 [4:3]。这些名字可以先理解为两类组件:训练后端负责把大模型切到多张 GPU 上训练,rollout 后端负责高吞吐生成文本。这意味着:
- 训练侧可以根据模型规模选择 FSDP 或 Megatron 风格的切分
- 推理侧可以根据场景选择 vLLM、SGLang 或 HF Transformers
- rollout、reference logprob、actor update、critic update 等步骤可以在统一控制器下组合
- 异步、off-policy、多模态/机器人等实验性方向可以继续接入同一套执行流
相较于 OpenRLHF 更偏向“Ray + vLLM + DeepSpeed 的工程化 RLHF 框架”,veRL 更强调对 RL 训练流的抽象和后端可组合性。它适用于需要修改训练流程、替换 rollout engine、插入自定义 reward、支持 VLM/multi-turn/tool calling,或研究新算法的场景。
1.10 训练/编排层 与 slime 的 Megatron + SGLang + Data Buffer
slime 的定位更偏向大规模 RL scaling。它的 README 把核心能力概括为两点:用 Megatron + SGLang 支持高性能训练,以及通过自定义数据生成接口和 server-based engine 支持灵活 rollout [5:1]。其中 Megatron 主要服务训练侧,SGLang 主要服务 rollout 侧。
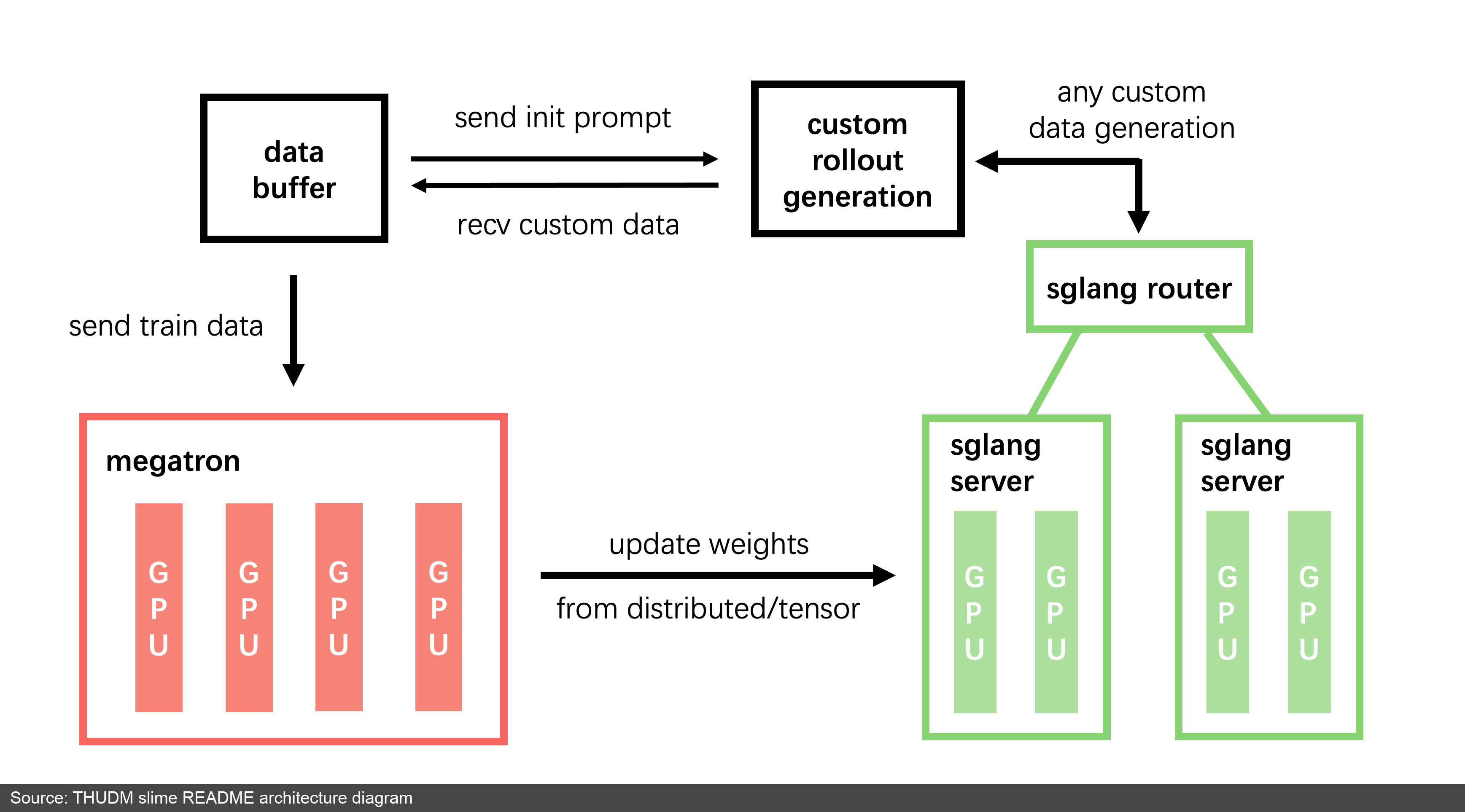
图 6:slime README 中的架构图。训练侧是 Megatron,推理侧是 SGLang server/router,中间用 data buffer 管理 prompt、rollout 数据和自定义生成逻辑。(来源:slime README [5:2])
slime 的系统结构相对明确:
- training (Megatron):从 Data Buffer 读取训练数据,完成训练后把新参数同步到 rollout 模块
- rollout (SGLang + router):生成新数据,包含 reward/verifier 输出,并写回 Data Buffer
- data buffer:管理 prompt 初始化、自定义数据和 rollout 生成方法
与 OpenRLHF / veRL 相比,slime 更明确地把 SGLang 作为原生推理层,而非一般可替换插件。slime 文档强调:内部以 server 模式启动 SGLang,SGLang 参数可以通过 --sglang-* 直接传递,并提供 --debug-rollout-only 用于单独调试 rollout 性能 [16]。训练侧同样支持 Megatron 参数透传,覆盖 TP/PP/EP/CP 等模型并行策略,并提供 --debug-train-only 调试训练部分 [16:1]。
slime README 里列出的下游项目也能说明它的定位:APRIL 专门优化 rollout 长尾;TritonForge、RLVE、P1 等则把 slime 用到代码生成、可验证环境和物理推理等任务上 [5:3]。这些项目复用的仍是本页讨论的底座:rollout engine、training backend、data buffer、权重同步和并行训练。至于 Agentic RL 框架如何在这层底座之上增加沙箱、多轮轨迹和工具调度,放到 B.2 再展开。
slime 的 release note 还讨论了典型系统工程问题:RL 推理延迟不能仅通过增加 GPU 解决,因为训练仍然要等待最长样本 decode 完成;过大的 inference batch 又会带来 off-policy 问题 [17]。因此,slime 关注 KV cache 空间、MoE fp8 rollout、DeepEP、Megatron offload、NCCL group 重建等底层优化。这些问题已经超越单机 PPO loop 的范畴,属于工业 RL 训练系统的基础设施问题。
Miles(radixark/miles)是 slime 的企业级分支,由 LMSYS 团队维护 [18]。它继承了 slime 的 Megatron + SGLang 架构,定位是大规模 MoE 后训练场景下的稳定可控 RL。slime 专注于算法和系统性能的极限优化,Miles 在此基础上增加了长周期训练的容错、运维监控和生产级可靠性,面向需要数天甚至数周持续运行的工业训练任务 [19]。
1.11 LLM RL 小结
LLM RL 的系统边界围绕“文本 rollout”展开。数据来自当前语言模型,奖励来自规则、模型或 verifier,训练系统还必须管理权重同步与策略版本。
| 类别 | 系统 | 定位 | 数据单位 | 主要瓶颈 |
|---|---|---|---|---|
| 推理/rollout 工具 | vLLM | 通用 LLM rollout engine | token / completion | KV cache、continuous batching、长尾 decode、sleep/weight sync |
| 推理/rollout 工具 | SGLang | 面向复杂生成与 RL 系统的 rollout engine | token / completion / structured output | RadixAttention、router、PD disaggregation、权重更新 |
| 训练/编排工具 | OpenRLHF | Ray + vLLM + DeepSpeed 后训练框架 | rollout batch | PPO/GRPO/RLOO 训练编排、colocated/async 取舍 |
| 训练/编排工具 | veRL | 可组合后端的 RL 训练流框架 | sample stream / rollout batch | rollout、model engine、TransferQueue、checkpoint 组合 |
| 训练/编排工具 | Seer | 极致同步:在线上下文学习消除长尾 | rollout batch | divided rollout、context-aware scheduling、speculative decode |
| 训练/编排工具 | slime | SGLang-native + Megatron 后训练框架 | data buffer / rollout batch | 大规模 rollout、Megatron 并行、MoE fp8 rollout 与 DeepEP |
| 训练/编排工具 | Miles | slime 企业分支,大规模 MoE 后训练 | data buffer / rollout batch | 长周期训练容错、运维监控、生产级可靠性 |
| 训练/编排工具 | ms-swift | ModelScope 生态一体化训练框架 | rollout batch | SFT/DPO/GRPO/RLHF 全流程、开箱即用、国内模型 hub 集成 |
| 训练/编排工具 | TRL | 单机研究原型,HuggingFace 生态 | rollout batch | DPO/PPO/GRPO Trainer 封装、快速验证、不涉及分布式编排 |
二、非 LLM RL 与 环境交互与仿真吞吐
非 LLM RL 指传统控制、游戏、机器人仿真等任务。训练数据来自环境:策略输出 action,环境返回下一步 observation、reward,以及 terminated/truncated 等“任务是否结束”的标记。此时采样基础设施的核心目标是提高环境交互吞吐,并减少 CPU 环境、GPU 策略网络和 learner 之间的等待。
非 LLM RL 的推理/采样层负责推进环境并产生 trajectory,训练/编排层负责消费 trajectory 并更新策略。Gymnasium 与 Isaac Gym 属于采样层的典型系统,IMPALA 和 Sample Factory 则体现了推理/采样层与训练/编排层的解耦方式。
2.1 推理/采样层 与 Gymnasium VectorEnv
Gymnasium 首先是一个环境接口,不是分布式训练框架。它定义了 reset()、step(action)、observation、reward、terminated/truncated 等基本交互方式。CartPole、LunarLander、Atari、MuJoCo 等算法实验通常从这一接口开始。
单个环境速度有限时,GPU 大部分时间会等待 CPU 执行 env.step()。因此,Gymnasium 提供同步和异步向量环境,把多个环境实例包装成一个批量环境 [20]。
from gymnasium.vector import SyncVectorEnv, AsyncVectorEnv
envs = SyncVectorEnv([lambda: gym.make("CartPole-v1") for _ in range(8)])
obs, info = envs.reset() # shape: (8, obs_dim)
actions = policy(obs) # 一次推理得到 8 个动作
obs, rewards, terms, truncs, infos = envs.step(actions)代码中的 obs 是 observation 的缩写,terms 和 truncs 表示哪些环境已经结束。向量环境把 8 个环境合成一个批量,让策略网络一次处理 8 个 observation。
| 方式 | 原理 | 适用场景 |
|---|---|---|
SyncVectorEnv | 主进程中顺序 step | 轻量环境,如 CartPole、部分 Atari 实验 |
AsyncVectorEnv | 多进程并行 step | step 本身较重的环境,如物理仿真 |
这一阶段的工程重点是正确处理 batch 形状、episode reset、终止条件和日志统计。所有组件通常仍在单机内运行。
2.2 推理/采样层与训练/编排层 与 IMPALA
当任务扩展到 Atari、DeepMind Lab、ViZDoom、MuJoCo 或机器人仿真时,瓶颈从“单环境太慢”转变为“大量环境如何持续产生轨迹”。此时仅增加 learner 侧 GPU 通常无法提升整体吞吐,因为 learner 仍然缺少足够的新数据。
分布式 RL 系统通常把角色拆成 Actor 和 Learner:Actor 负责与环境交互并生成 trajectory,Learner 负责消费轨迹并更新参数。
IMPALA 是这一路线的代表。大量 Actor 并行生成 trajectory,把数据发送给中心 Learner;Actor 不再把梯度发回参数服务器,而是发送完整轨迹,让 Learner 在 GPU 上连续消费 batch。由于 Actor 采样时可能使用稍旧的策略,IMPALA 用 V-trace 做 off-policy 修正;V-trace 是一种“旧样本校正”方法,用来降低策略滞后带来的偏差 [21]。这奠定了许多后续系统的基本形状:采样和训练解耦,吞吐优先,再用算法处理数据过期。
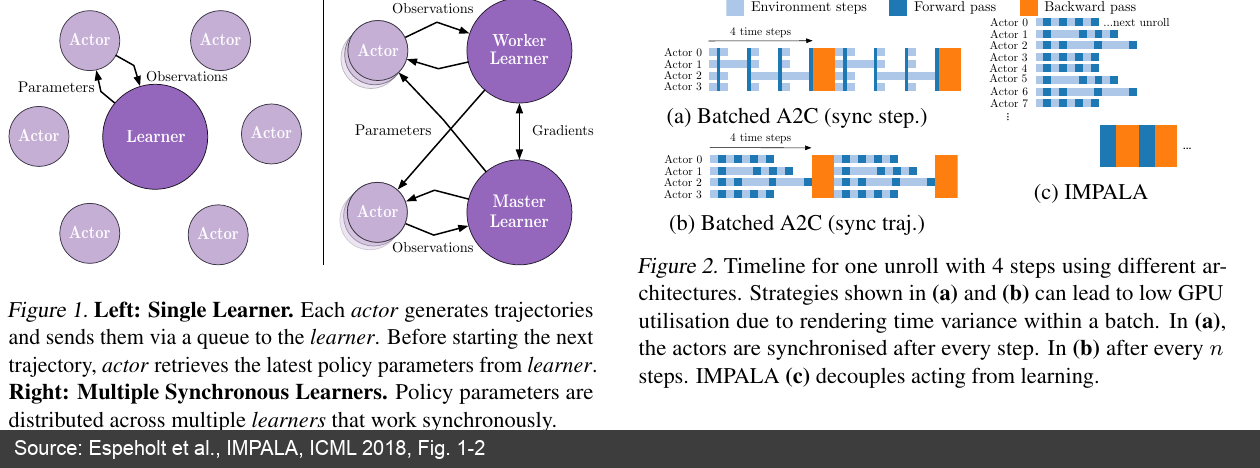
图 7:IMPALA 论文中的 Actor-Learner 架构和时间线。左边说明 Actor 只负责生成轨迹并从 Learner 拉取参数;右边说明 IMPALA 不再等待所有 Actor 同步完成,而是让 acting 和 learning 解耦。(来源:IMPALA 论文 [21:1])
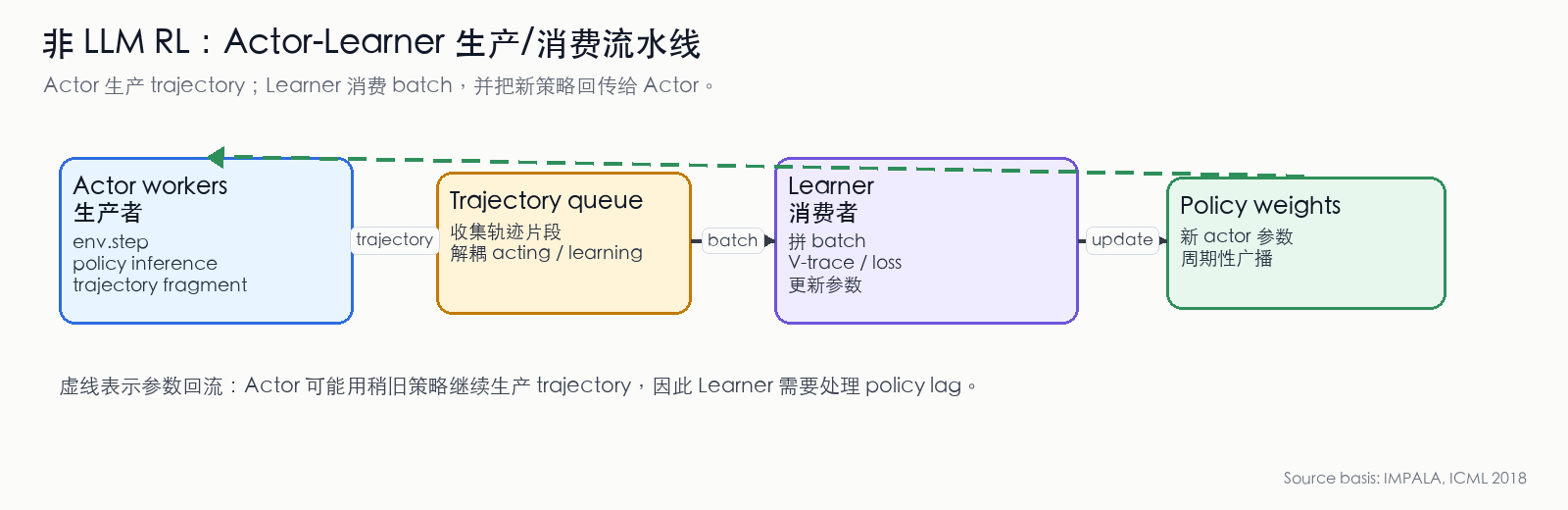
图 8:IMPALA Actor-Learner 架构的生产/消费视角。Actor 是 trajectory 生产者,Learner 是 batch 消费者;虚线表示新策略权重回流到 Actor。这个回流不一定与采样严格同步,因此会产生 policy lag。(依据 IMPALA 论文 [21:2] 整理)
2.3 推理/采样层与训练/编排层 与 Sample Factory
Sample Factory 把 Actor-Learner 解耦推向单机高吞吐实现:异步 Actor-Learner、共享内存、批量推理和更少的 Python 开销,使 Atari/3D 控制任务可以达到 100K+ fps(每秒十万帧以上)量级 [22]。它并非仅仅增加环境数量,而是把工作拆成专门组件:
- Rollout worker:CPU 侧只跑环境,自己不持有策略副本,因此可以大量并行
- Policy worker:GPU 侧做批量 action generation,把 observation 合并成更大的 forward batch
- Learner:消费完整轨迹做反向传播,并把新参数写入共享 GPU 内存
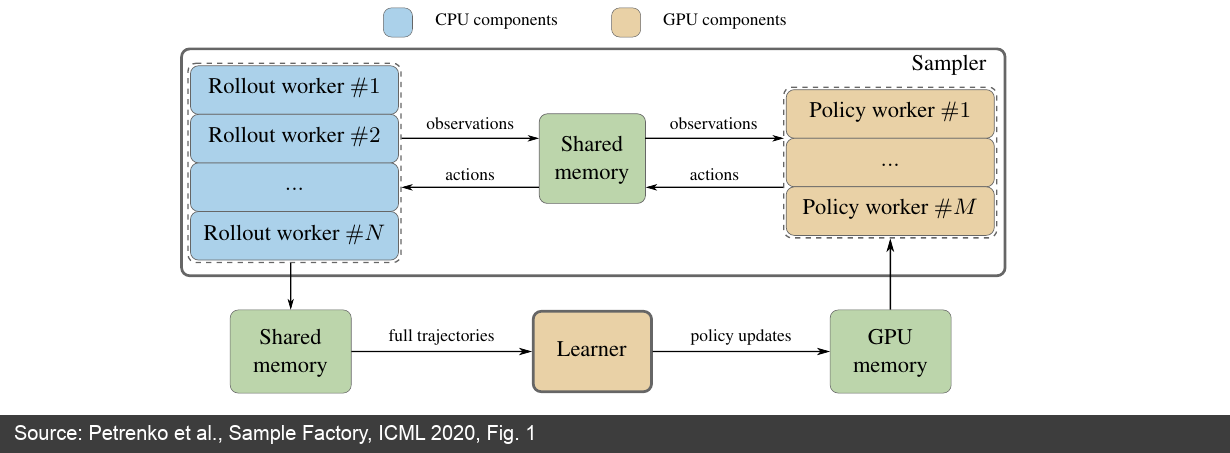
图 9:Sample Factory 论文中的系统架构。它把环境模拟、策略前向、反向训练拆成独立组件,用 FIFO queue 和共享内存降低通信成本。(来源:Sample Factory 论文 [22:1])
该架构的重点在于数据流:observation 从 rollout worker 经 shared memory 到 policy worker,action 再回到 rollout worker;完整 trajectory 进入 learner;更新后的参数进入 GPU 内存,再被 policy worker 取走。
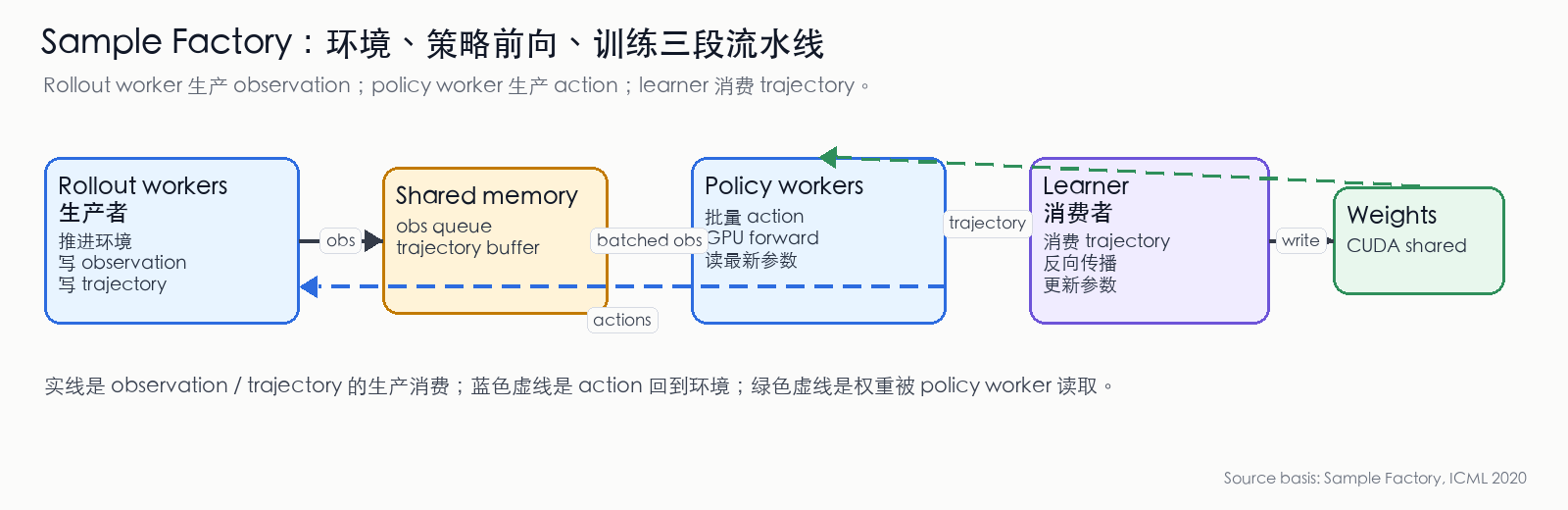
图 10:Sample Factory 的生产/消费流水线。Rollout workers 生产 observation 和 trajectory;policy workers 消费 observation 并生产 action;Learner 消费 trajectory 并更新共享权重。共享内存让三段流水线减少 Python 进程间拷贝。(依据 Sample Factory 论文 [22:2] 整理)
2.4 推理/采样层 与 Isaac Gym GPU 仿真
机器人和物理控制任务还会遇到另一个瓶颈:物理仿真本身较重,且传统 CPU 物理引擎需要频繁把状态搬到 GPU 上进行策略推理。
NVIDIA Isaac Gym 把物理仿真直接搬到 GPU 上,数万个环境并行,核心收益是减少 CPU 物理引擎和 GPU 策略网络之间的逐步数据搬运 [23]。
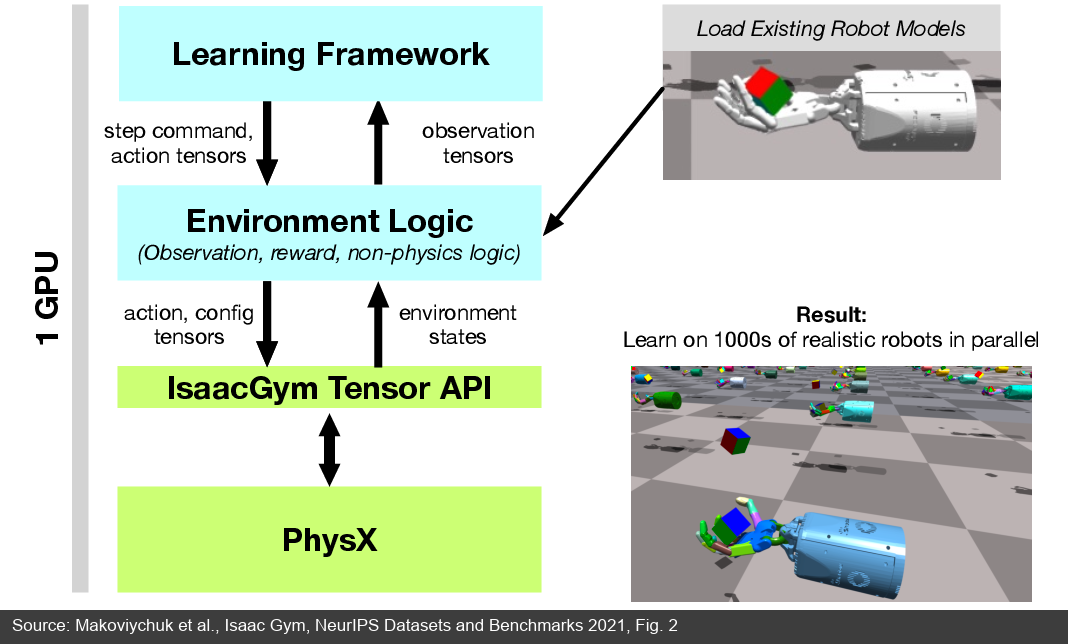
图 11:Isaac Gym 论文中的 GPU pipeline。Learning Framework、Environment Logic、IsaacGym Tensor API 和 PhysX 都围绕 GPU tensor 交换状态、动作和配置,避免每一步都跨 CPU/GPU 拷贝。(来源:Isaac Gym 论文 [23:1])
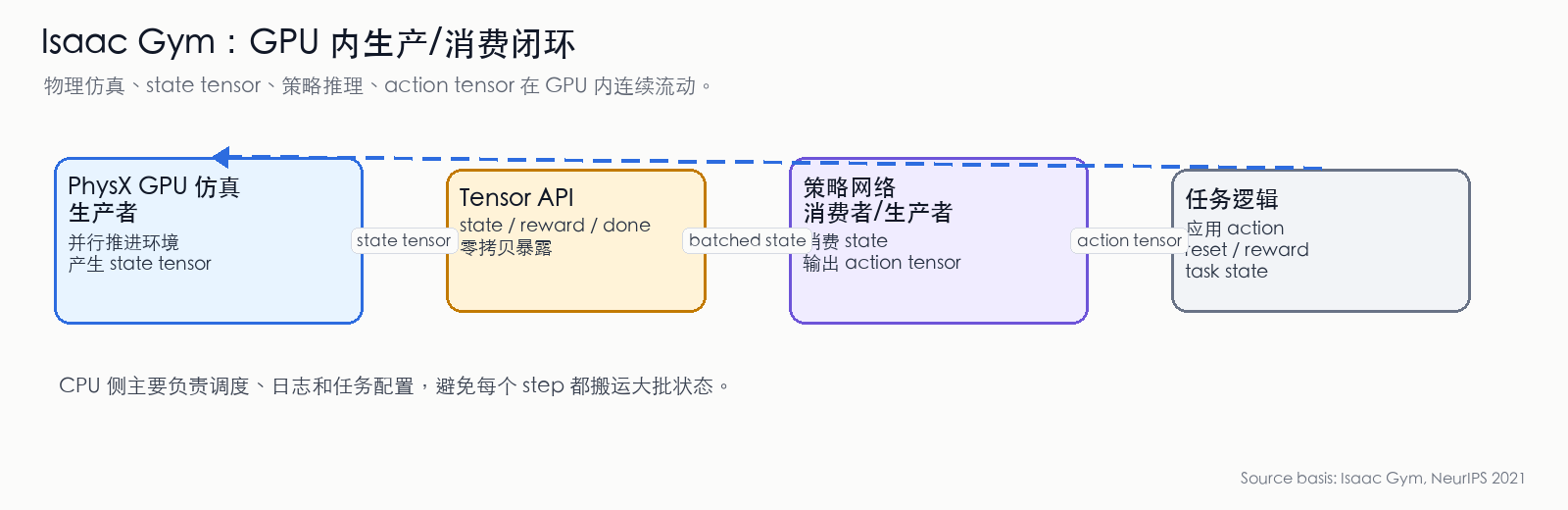
图 12:Isaac Gym 的 GPU 内生产/消费闭环。PhysX 在 GPU 上生产 state tensor,策略网络直接消费 state tensor 并生产 action tensor,任务逻辑再把 action 写回下一轮物理仿真。核心收益是避免每个 step 的 CPU/GPU 往返搬运。(依据 Isaac Gym 论文 [23:2] 整理)
传统方式: CPU 物理引擎 × 64 环境 → GPU 策略推理
Isaac Gym: GPU 物理仿真 × 4096 环境 + GPU 策略推理| 对比 | CPU 并行 (MuJoCo × 64) | GPU 并行 (Isaac Gym × 4096) |
|---|---|---|
| 采样速度 | ~10K fps | ~1M fps |
| 数据传输 | CPU→GPU 每步 | 零拷贝 |
| 适用场景 | 少关节机器人 | 人形机器人、灵巧手 |
2.5 非 LLM RL 小结
非 LLM RL 的系统边界围绕“环境交互”展开。数据来自外部环境或仿真器,主要数据单位是 transition、episode 和 trajectory。
| 类别 | 系统 | 定位 | 数据单位 | 主要瓶颈 |
|---|---|---|---|---|
| 推理/采样工具 | Gymnasium VectorEnv | 环境接口/单机批量环境 | transition / episode | Python env.step() |
| 推理/采样工具 | IMPALA Actor | 分布式环境交互组件 | trajectory | Actor 数量、网络传输、policy lag |
| 训练/编排工具 | IMPALA Learner | 集中训练组件 | trajectory batch | Learner 吞吐、参数广播、V-trace 修正 |
| 推理/采样工具 | Sample Factory rollout worker / policy worker | 单机高吞吐采样组件 | trajectory buffer | CPU rollout、GPU policy worker、共享内存 |
| 训练/编排工具 | Sample Factory Learner | 单机异步训练组件 | trajectory batch | learner 与采样端互等、参数同步 |
| 推理/采样工具 | Isaac Gym | GPU 物理仿真平台 | GPU tensor state | CPU/GPU 数据搬运和物理仿真吞吐 |
三、异步训练架构 与 让生成和训练重叠
LLM RL 训练有一个核心矛盾:生成很慢,训练相对很快,两者串行会让 GPU 大量空等。以 GRPO 为例,一个训练 step 往往先让模型生成几百条回答,再计算 loss 和更新参数。生成阶段训练 GPU 在等,训练阶段 rollout GPU 在等。输出越长,等待越明显。
一个典型 GRPO step 可以理解成这样:
① 生成 rollout batch ← 推理慢,训练端等待
② 计算 reward / advantage
③ 反向传播并更新 actor ← 训练快,推理端等待
④ 把新权重同步回 rollout工程上常见三种部署方式:
| 模式 | 资源组织 | 是否重叠 | 适用场景 |
|---|---|---|---|
| 同步模式 | 一组 GPU,生成和训练串行 | 否 | 学习、小实验、严格 on-policy 原型 |
| 共置模式 | 一组 GPU,rollout 和 training 轮替占用 | 否,但切换更快 | GPU 预算有限的中等规模训练 |
| 分离模式 | rollout GPU 和 training GPU 分开,中间用 buffer | 是 | 大规模生产训练 |
同步模式最容易理解:先生成,再训练,再生成。它的好处是简单,坏处是吞吐很差。共置模式让同一组 GPU 在推理格式和训练格式之间切换,例如从 FSDP 分片格式转换到 vLLM 张量并行格式,再切回训练格式。它节省 GPU,但生成和训练仍然不能真正同时跑。
分离模式才是大规模 RL 训练的标配:rollout GPU 持续生成样本,把 token、mask、reward、policy version 写入 buffer;training GPU 持续从 buffer 取样本训练;权重更新后再同步给 rollout engine。
Rollout GPU: [生成 b0] [生成 b1] [生成 b2] [生成 b3] ...
↓ ↓ ↓
Buffer: [b0] [b1] [b2]
↓ ↓ ↓
Training GPU: [训练 b0] [训练 b1] [训练 b2] ...
↑ ↑
weight sync weight sync分离模式带来两个新问题:新权重怎么同步给推理端,以及旧策略生成的数据还能不能继续用。
权重同步
Trainer 更新 actor 后,rollout engine 必须拿到新权重。不同系统采用不同传输方式:
| 方式 | 传输内容 | 特点 |
|---|---|---|
| NCCL 全量广播 | 全部参数 | 通用,常见于多 GPU 集群 |
| 打包传输 | 全部参数 | 减少小张量传输开销 |
| GPU 显存直传 | 全部参数 | 依赖高带宽互联 |
| 只同步 LoRA adapter | adapter 参数 | 数据量小,适合 LoRA 后训练 |
| 写 checkpoint 再加载 | 文件 | 跨节点简单,但慢 |
如果训练的是 LoRA adapter,权重同步会轻很多:rollout 侧只需要接收 adapter,而不是完整基座模型。这也是 LoRA + 异步训练常被一起使用的原因。
权重到达时,rollout engine 还可能正在生成长回答。常见处理方式有四种:不中断生成、等当前请求完成后再切换、直接中断并重启请求、等整个 batch 完成后再切换。越激进,吞吐越高;越保守,一致性越好。
旧数据处理
异步队列越深,训练端拿到的数据越可能来自旧策略。严格 on-policy 训练会丢弃这些样本;吞吐优先的系统则允许少量滞后,并用工程和算法共同约束风险。
| 思路 | 做法 | 取舍 |
|---|---|---|
| 版本号过滤 | 每条样本记录 policy version,太旧就丢 | 简单可靠,但浪费样本 |
| 限制 buffer 深度 | 让队列最多保留少量 batch | 用系统约束 staleness |
| 重要性采样修正 | 根据新旧策略概率比给样本加权 | 不浪费数据,但实现更复杂 |
| 三者组合 | 队列兜底 + 版本过滤 + 截断修正 | 生产系统常见选择 |
实践中常用的安全边界是:先把 buffer 做浅,避免样本过旧;再记录 policy version;最后在算法层用 KL、clip 或 truncated importance sampling 抑制过大偏差。也就是说,异步训练不是简单地“越异步越好”,而是在吞吐、样本新鲜度和训练稳定性之间取平衡 [24]。
四、分布式并行与显存优化 与 把模型切到多张卡
RL 后训练比普通微调更吃显存。PPO 可能同时涉及 Actor、Critic、Reference、Reward Model;即使 GRPO 省掉 Critic,也仍然需要 actor、reference、rollout engine、reward/verifier 等组件一起工作。模型装不进一张卡时,需要把计算和状态切到多张 GPU 上。
四种并行策略
| 策略 | 切什么 | 通信特点 | 适用范围 |
|---|---|---|---|
| DP 数据并行 | 不同 GPU 处理不同 batch | 梯度 AllReduce | 单卡能装下模型时 |
| TP 张量并行 | 层内矩阵切分 | 每次 forward/backward 都通信 | 节点内多卡,依赖 NVLink |
| PP 流水线并行 | 按层切分模型 | 激活在相邻 stage 间传递 | 跨节点大模型 |
| EP 专家并行 | MoE 专家分布到不同 GPU | token 路由到专家 | MoE 模型 |
70B 密集模型常用 DP + TP + PP 的混合并行;MoE 模型还需要 EP。TP 更适合节点内高带宽互联,PP 更适合跨节点分层切分,DP 则负责扩大 batch 和同步梯度。
FSDP 与 ZeRO
上面几种并行回答的是“怎么算”,FSDP 和 ZeRO 回答的是“状态怎么省显存”。
FSDP(Fully Sharded Data Parallel) 把参数、梯度、优化器状态切到不同 GPU 上,计算时再临时聚合。它是 PyTorch 原生方案,通用性好。
DeepSpeed ZeRO 也按优化器状态、梯度、参数分阶段切分。ZeRO-3 可以把三类状态全部切开,显存压力最低,但通信开销也最大。
实践中,FSDP / ZeRO 常与 TP / PP 组合使用:前者省状态显存,后者切模型计算。
混合精度与 RL 特有挑战
| 精度 | 用途 | 建议 |
|---|---|---|
| BF16 | 训练 | 首选,稳定性通常好于 FP16 |
| FP16 | 训练 | 可用,但要注意溢出和 loss scaling |
| FP32 | 关键计算 | 稳定但慢、显存高 |
| FP8 | 前沿训练/推理 | 性能高,但稳定性和框架支持要验证 |
| INT8/INT4 | 推理 | 适合 serving / rollout 压缩,不宜直接当训练主精度 |
RL 训练的额外挑战在于 rollout 阶段和 training 阶段对资源的需求不同:rollout 是推理密集型,尤其受 KV cache、长尾输出和并发调度影响;training 是反向传播密集型,受模型并行、优化器状态和通信影响。分离式架构会让两类 GPU 各自优化,但也引入权重同步和样本过期问题;共置式架构省 GPU,但需要频繁在推理格式和训练格式之间切换。
常见显存优化手段包括:
| 技巧 | 原理 | 适用点 |
|---|---|---|
| Reference 模型共享 | Reference 不训练,可与 Actor 共享部分权重 | PPO / GRPO |
| LoRA Rollout | rollout 侧加载基座 + adapter | LoRA 后训练 |
| Gradient Checkpointing | 牺牲计算换激活显存 | 长序列训练 |
| 序列打包和负载均衡 | 减少 padding 与 rank 间等待 | 变长输出 |
MoE 和 PRM 会进一步放大系统复杂度。MoE 需要处理专家负载均衡、训练/推理路由一致性;PRM 可能引入额外的 step-level scoring GPU,把 reward 计算变成新的瓶颈 [25]。
选型原则
| 任务类型 | 首要问题 | 所属大类 | 推理/采样选择 | 训练/编排选择 |
|---|---|---|---|---|
| LLM RL 原型 | 生成回答的推理吞吐 | LLM RL | vLLM / SGLang | TRL / OpenRLHF / veRL |
| 7B-70B LLM PPO/GRPO/RLOO | rollout、reward、training、buffer、weight sync 如何编排 | LLM RL | vLLM / SGLang | OpenRLHF / veRL / slime |
| CartPole / LunarLander / 小型控制实验 | 环境接口和批量环境 | 非 LLM RL | Gymnasium VectorEnv | 单机 PPO/DQN 训练循环 |
| Atari / ViZDoom / DeepMind Lab 高吞吐训练 | 如何减少 CPU 环境、policy forward、learner 之间的互等 | 非 LLM RL | IMPALA Actor / Sample Factory rollout worker | IMPALA Learner / Sample Factory Learner |
| 机器人仿真、灵巧手、人形控制 | 物理仿真和策略网络之间如何减少拷贝 | 非 LLM RL | Isaac Gym | PPO/SAC 等 learner |
选型时首先判断任务是否属于 LLM RL。LLM RL 优先评估推理/rollout 吞吐,再评估 reward、training、buffer、weight sync 的编排方式;非 LLM RL 主要优化环境交互和仿真吞吐。在每个大类内部,再根据具体瓶颈选择对应系统。
如果你只记一个判断顺序:先判断任务属于 LLM RL 还是非 LLM RL;再找采样瓶颈在哪里;然后决定同步、共置还是分离;最后根据模型规模选择 FSDP、ZeRO、TP、PP、EP 等并行策略。若任务进入多轮交互、工具调用、代码执行、网页访问或多模态环境状态管理,就不要继续把问题理解成“更复杂的 rollout batch”,而应转到 B.2 Agentic RL 基础设施。
参考文献
vLLM Documentation, Reinforcement Learning from Human Feedback, 2026. ↩︎ ↩︎
SGLang Documentation, SGLang for RL Systems, 2026. ↩︎ ↩︎
OpenRLHF Project, Architecture Foundation: Ray + vLLM Distribution, README. ↩︎ ↩︎ ↩︎
veRL Project, README and architecture diagram, 2026. ↩︎ ↩︎ ↩︎ ↩︎
THUDM slime Project, slime: An LLM post-training framework for RL Scaling, README. ↩︎ ↩︎ ↩︎ ↩︎
Kwon W, Li Z, Zhuang S, et al. Efficient Memory Management for Large Language Model Serving with PagedAttention, 2023. (vLLM / PagedAttention) ↩︎
vLLM Team, vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention, 2023. ↩︎ ↩︎
SGLang Documentation, PD Disaggregation, 2026. ↩︎
SGLang Documentation, SGLang Router, 2026. ↩︎
vLLM Documentation, Sleep Mode, 2026. ↩︎
HuggingFace TRL Project, TRL: Transformer Reinforcement Learning, 2025. ↩︎ ↩︎
ModelScope Swift Project, ms-swift: ModelScope Framework for LLM/AIGC Training & Inference, 2025. ↩︎
Sheng G, Zhang C, Ye Z, et al. HybridFlow: A Flexible and Efficient RLHF Framework, 2024. veRL GitHub. ↩︎ ↩︎ ↩︎
OpenRLHF Team, OpenRLHF: An Easy-to-use, Scalable and High-performance RLHF Framework, 2024. GitHub. ↩︎
OpenRLHF Documentation, Async Training & Partial Rollout, 2026. ↩︎
slime Documentation, slime:为 RL Scaling 设计的 SGLang-Native 后训练框架, 2025. ↩︎ ↩︎
slime Documentation, v0.1.0: Redefining High-Performance RL Training Frameworks, 2025. ↩︎
LMSYS Blog, Introducing Miles, 2025. ↩︎
radixark Miles Project, Miles: Enterprise-ready RL Framework for LLM/VLM Post-Training, README, 2025. ↩︎
Gymnasium Documentation, Vector Environments (SyncVectorEnv / AsyncVectorEnv). ↩︎
Espeholt L, Soyer H, Munos R, et al. IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures, ICML 2018. ↩︎ ↩︎ ↩︎
Petrenko A, Huang Z, Kumar T, Sukhatme G S, Koltun V. Sample Factory: Egocentric 3D Control from Pixels at 100000 FPS with Asynchronous Reinforcement Learning, ICML 2020. ↩︎ ↩︎ ↩︎
Makoviychuk V, Wawrzyniak L, Guo Y, et al. Isaac Gym: High Performance GPU Based Physics Simulation For Robot Learning, NeurIPS 2021 (Datasets and Benchmarks). ↩︎ ↩︎ ↩︎
HuggingFace Blog, Async RL Training Landscape — 16 Open-Source Libraries Compared, 2026. ↩︎
DeepSeek-AI, DeepSeek-V3 Technical Report, 2024. ↩︎