12.2 Model-Based RL:从 Model-Free 到 Model-Based
在具身智能中,真实世界不是一个可以无限 reset() 的 Gym 环境。机械臂夹错一次可能会撞到桌面,四足机器人摔一次可能要人工扶起,自动驾驶更不可能靠真实事故来探索边界条件。因此,具身 RL 最核心的问题之一是:能不能少在真实世界试错,多在“脑内世界”里推演?
这就是 Model-Based RL(MBRL,基于模型的强化学习) 的出发点。它让智能体先学习一个环境模型,再用这个模型做规划、生成想象轨迹,或者辅助策略更新。相比 Model-Free 方法,MBRL 的目标不是只学“这个状态下该做什么”,而是进一步学“我这么做以后,世界会怎样变化”。
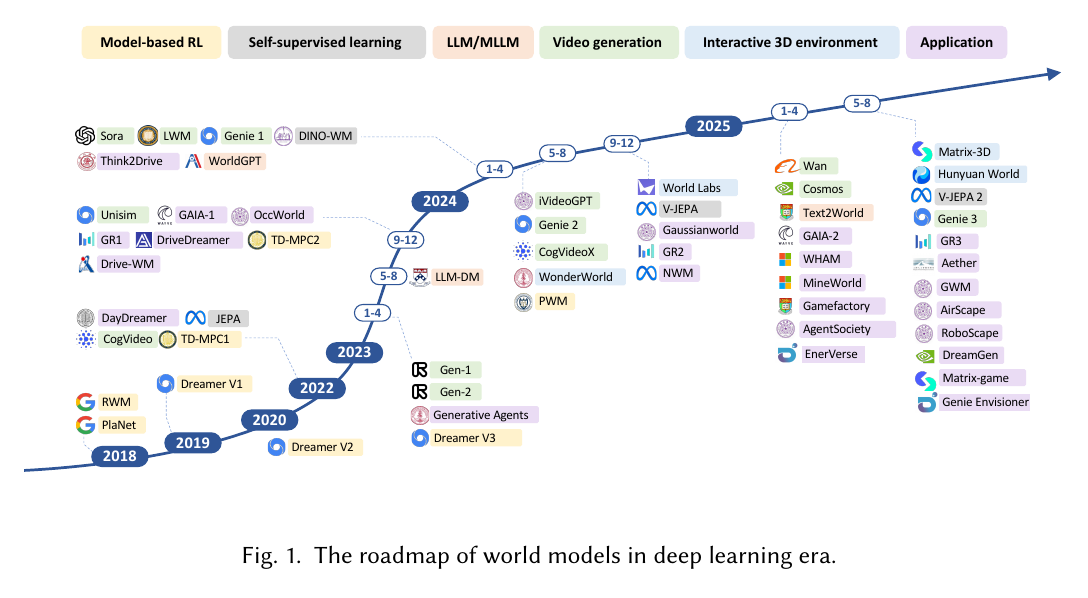
从综述看:世界模型不止一种
近两年的综述文章提醒我们,“世界模型”已经不是一个只属于强化学习的小概念。Ding 等人在综述中把世界模型概括成两类核心功能:一类是 understanding the world,也就是构建内部表征来理解世界机制;另一类是 predicting future dynamics,也就是预测未来状态来支持仿真、规划和决策[1]。本节讨论的 MBRL 主要落在第二类,但会频繁借用第一类的表征学习能力。
如果从具身智能角度看,世界模型还可以沿着三条轴来划分[2]:
| 划分维度 | 典型问题 | 对 MBRL 的意义 |
|---|---|---|
| 功能 | 是为某个控制任务服务,还是通用仿真 | 决定模型要不要直接预测 reward/value |
| 时间建模 | 一步步自回归 rollout,还是并行预测 | 决定是否容易出现长期误差累积 |
| 空间表征 | 低维状态、token、BEV/voxel、3D 表示 | 决定模型能否处理视觉、接触和几何约束 |
| 决策耦合程度 | 只生成未来,还是直接参与规划 | 决定它更像视频模型、仿真器,还是控制器 |
自动驾驶世界模型综述也给了一个更工程化的划分:世界模型可以用于生成未来物理世界、用于智能体行为规划,也可以把预测和规划放进同一个交互闭环[3]。这和具身机器人非常接近:机器人既要“看见可能的未来”,也要“选择能安全到达的未来”。
因此,这篇文章会采用一个收敛的定义:MBRL 里的世界模型,是一个能把当前状态、动作和历史压缩成可预测表征,并支持未来 rollout、规划搜索或策略训练的模型。 它可以是低维动力学模型,可以是 Dreamer 那样的潜空间模型,可以是 MuZero 那种只服务于搜索的隐式模型,也可以和视频生成、JEPA 表征、自动驾驶占据预测这些更广义的世界模型互相借力。
Model-Free vs Model-Based
到目前为止,本书大部分算法——从 DQN、PPO、SAC 到 DPO、GRPO——都属于 Model-Free RL。智能体不显式学习环境动力学,只通过真实或仿真交互来优化价值函数或策略。
先用人话看一遍
先把公式藏在脑后,只记这三句话:
- Model-Free:不学习“世界怎么变”,直接从真实交互里学“我该怎么做”。
- Model-Based:先学习一个“世界怎么变”的近似模型,再拿它来规划或生成想象经验。
- 关键差别:不是有没有环境转移,而是智能体有没有把这个转移规律学成一个可调用的模型。
如果只想抓主线,可以先读这一段和下面的表格;公式等跑完最小实践后再回头看会顺很多。
数学上,Model-Free 并不是“不存在环境转移”,而是 不去显式学习这个转移模型。先把符号对齐:
| 符号 | 可以先怎么理解 |
|---|---|
| $s_t$ | 第 步的状态,比如机器人关节角、速度、相机表征 |
| $a_t$ | 第 步的动作,比如力矩、速度指令、夹爪开合 |
| $r_t$ | 第 步拿到的奖励 |
| $\pi_\theta$ | 策略,也就是“看到状态以后怎么选动作”的模型 |
| $p$ | 真实环境的转移规律 |
| $\hat{p}_\phi$ | 智能体学出来的世界模型, 是它的参数 |
| $\gamma$ | 折扣因子,越远的奖励权重越小 |
真实环境里始终存在一个转移规律:
这行公式只是在说:如果当前状态是 ,智能体做了动作 ,真实环境会产生下一个状态 。Model-Free 方法也会经历这个转移,只是它不把这个规律学成一个可调用的模型。
一次交互轨迹可以写成:
把它读成一句话就是:智能体先看到 ,策略 采样动作 ,真实环境 再给出下一个状态 和奖励 。这里的 就是一整段经验录像。
Model-Free 直接优化“平均能拿多少分”:
这个公式可以按三层读。里面的 是一条轨迹的总回报; 让越远的奖励权重越小;外面的期望表示环境和策略都有随机性,所以我们看很多条轨迹的平均分。训练 Model-Free 策略,就是让 变大。
如果走策略梯度路线,例如 REINFORCE、A2C、PPO,核心更新是:
这行公式的普通话版本是:如果某个动作让结果比平均更好,就提高策略以后选它的概率;如果比平均更差,就降低它的概率。 表示“策略在 下选中 的 log 概率”, 表示这个动作比参考水平好多少。
如果走价值函数路线,例如 DQN、SAC、TD3,核心是先造一个 TD 目标:
这里 是给 critic 的临时答案:当前奖励 ,加上下一状态还能拿到的价值。如果 episode 已经结束,,后面那项会被 消掉。
critic 的训练 loss 是:
它的意思很朴素:当前 critic 预测的是 ,临时答案是 ,训练时让两者尽量接近。这里最关键的是数据来源: 来自真实环境或仿真器记录下来的 replay buffer,不是神经网络世界模型生成出来的。
MBRL 则多了一层“世界模型”。它不只优化策略或价值函数,还要显式学习一个环境近似模型:
没有帽子的 表示真实环境规律;带帽子的 表示“我用数据学出来的近似版本”。它可以预测下一状态、奖励、终止概率,或者在更现代的做法中,预测潜空间里的未来表征。
有了世界模型以后,智能体可以先在模型里试动作序列,再选模型预测最好的那一条:
这个公式里, 表示”找出得分最高的候选动作序列”; 是往前看的步数; 和 上面的帽子表示这些状态和奖励来自世界模型预测。MPC 通常不会一次执行完整序列,而是只执行第一个动作 ,看到新的真实状态后再重新规划。
也可以用模型 rollout 生成想象经验,再更新策略或价值函数:
所以两者最关键的数学差异是:Model-Free 的学习信号来自真实采样的 next_state;Model-Based 先学习一个 world_model,再用模型预测出来的 imagined state 和 imagined reward 做规划或训练。
一张表总结
| 维度 | Model-Free RL | Model-Based RL |
|---|---|---|
| 核心思路 | 直接学习策略或价值函数 | 先学习世界模型,再用模型规划或训练策略 |
| 样本效率 | 通常较低,需要大量交互 | 通常更高,可以复用模型生成想象经验 |
| 主要风险 | 试错成本高、探索慢 | 模型误差会被规划过程放大 |
| 代表算法 | DQN, PPO, SAC, DPO, GRPO | Dyna, PETS, PlaNet, MuZero, Dreamer |
| 适合场景 | 交互便宜、仿真充足、目标清晰 | 交互昂贵、需要预测未来、需要安全试错 |
| “脑内模拟” | 无显式模拟 | 有,智能体可以在模型中推演未来 |
用一个直观类比:Model-Free 像一个只靠实战积累经验的棋手;Model-Based 像一个能在脑中推演几步棋的棋手。前者每一步都从真实反馈中学,后者会先想象几条可能路线,再决定怎么行动。
公式看晕时
先回到 先用人话看一遍,或者直接跳到 最小 MBRL 实践。把代码跑通以后,再回来看上面的公式,会更像是在给代码命名,而不是凭空背符号。
从数学看:世界模型到底学什么?
最基础的 MBRL 会把真实交互收集成一个数据集:
这行公式只是把 replay buffer 写得更正式一点。每条数据都包含五个东西:当前状态 、动作 、奖励 、下一状态 ,以及 episode 是否终止的标记 。
世界模型要学的,就是“给定当前状态和动作,预测接下来会发生什么”:
这里的输入是 ,输出是下一状态、奖励和是否结束。换成代码,就是 world_model(state, action) -> next_state, reward, done。不同算法的输出形式不同,但核心问题都是这一句:如果我现在这么做,世界下一步会怎样?
如果状态维度较低,例如 MuJoCo 里的关节角、速度和接触信息,一个常见做法是预测状态差分:
为什么预测差分?因为很多物理系统里,下一状态通常不会凭空跳到很远,而是在当前状态附近变化。模型学“变化量”往往比直接学完整的 更容易。比如当前位置是 2.0,下一步是 2.1,模型只要学会“增加 0.1”。
确定性模型可以用均方误差训练:
这个 loss 有两项。第一项让模型预测的状态变化 接近真实变化 ;第二项让模型预测的奖励 接近真实奖励 。 是一个权重,用来控制“奖励预测错误”在总 loss 里有多重要。
最小实践:确定性世界模型 + 随机 shooting MPC
所以入门时不需要一上来就做 PETS。最小 MBRL 实践可以先做一个 确定性 one-step dynamics model,再用最朴素的随机 shooting 做 MPC。这个版本虽然简单,但已经包含 MBRL 的完整闭环:真实交互收集数据、训练世界模型、在模型里试很多动作序列、只把最好的第一步动作拿到真实环境执行。
我们可以用一个不依赖 Gym 的一维点质量环境:
状态只有两个数:位置 和速度 。动作 可以理解成向左或向右推的力度,范围限制在 ,避免动作无限大。
这两行就是这个小世界的“真实物理”。下一步速度由旧速度和当前动作共同决定, 表示速度会保留但有一点衰减, 表示动作会改变速度。位置则用新速度往前更新。
奖励让小车尽量回到 ,同时不要速度太大、动作太猛:
这里前面的负号很重要。括号里越大,说明位置偏得越远、速度越大、动作越猛;加上负号以后,越接近 0、越平稳、动作越小,reward 就越高。
世界模型只需要预测三件事:
也就是说,模型看到当前位置、速度和动作以后,预测“位置会变多少、速度会变多少、这一步奖励是多少”。再用当前状态加上预测差分,就能得到模型想象出来的下一状态。
规划时随机采样 条动作序列,在模型里滚动 步:
这个公式可以按流程读。先随机生成 条候选动作序列;第 条序列在模型里滚动 步,得到一串预测奖励 ;把这些奖励加起来,选总分最高的那条序列。最后只执行 ,拿到真实新状态后重新规划。这就是最小版的 Model Predictive Control。
完整脚本在 minimal_mbrl_point_mass.py,可以直接运行:
python docs/chapter12_future_trends/embodied-intelligence/model-based-rl/snippets/minimal_mbrl_point_mass.py典型结果会看到随机策略把系统越推越远,而 MBRL 的 MPC 能把状态拉回原点附近:
one_step_model_mse=0.013716
random_policy_return=-2246.07, final_state=[8.50, -0.25]
mbrl_mpc_return=-18.76, final_state=[0.17, 0.07]核心代码如下:
# 1. 真实环境只用来收集数据和执行最终动作
state = env_reset()
action = torch.empty(1).uniform_(-1.0, 1.0)
next_state, reward = env_step(state, action)
# 2. 世界模型学习 next_state - state 和 reward
target = torch.cat([next_state - state, reward.unsqueeze(-1)], dim=-1)
pred = model(state, action)
model_loss = ((pred - target) ** 2).mean()
# 3. MPC 在模型里试很多动作序列
action_sequences = torch.empty(num_samples, horizon, 1).uniform_(-1.0, 1.0)
scores = score_action_sequences(model, state, action_sequences)
real_action = action_sequences[scores.argmax(), 0]
# 4. 只把第一步动作拿去真实环境执行,然后重新观测、重新规划
next_state, reward = env_step(state, real_action)这段练习的重点不是性能,而是把概念跑通:Model-Free 直接学 policy(state) -> action 或 Q(state, action);最小 MBRL 先学 model(state, action) -> next_state, reward,再把这个模型当作临时模拟器来选动作。
那为什么正文还要引用 PETS?因为上面的最小版本默认“模型预测就是一个确定值”。但机器人里的接触、摩擦、传感器噪声和遮挡往往不是确定的;数据少的时候,模型还会“不知道自己不知道”。PETS[4] 的价值不在于它是入门必需,而在于它把 概率动力学模型、模型集成、不确定性传播和 MPC 放进同一个清晰框架里,是理解现代 MBRL 风险控制的好例子。
PETS 的关键贡献之一,是用 概率动力学模型集成 表达不确定性:
这和前面的确定性模型不同。确定性模型只给一个答案:“我认为状态会这样变”。PETS 里的概率模型给的是一个分布:“我认为最可能的变化是 ,但还有 这么大的不确定性”。下标 表示模型集成里的第 个成员。
训练目标通常写成高斯负对数似然:
这行 loss 也可以分成两部分看。第一项像“带权重的平方误差”:真实目标 离预测均值 越远,惩罚越大;如果模型自己预测的方差 很大,说明它承认自己不确定,这个误差惩罚会被放缓。第二项 会惩罚模型把方差无限调大。于是模型不能靠一句“我很不确定”逃避所有错误,必须在预测准确和诚实表达不确定之间取得平衡。
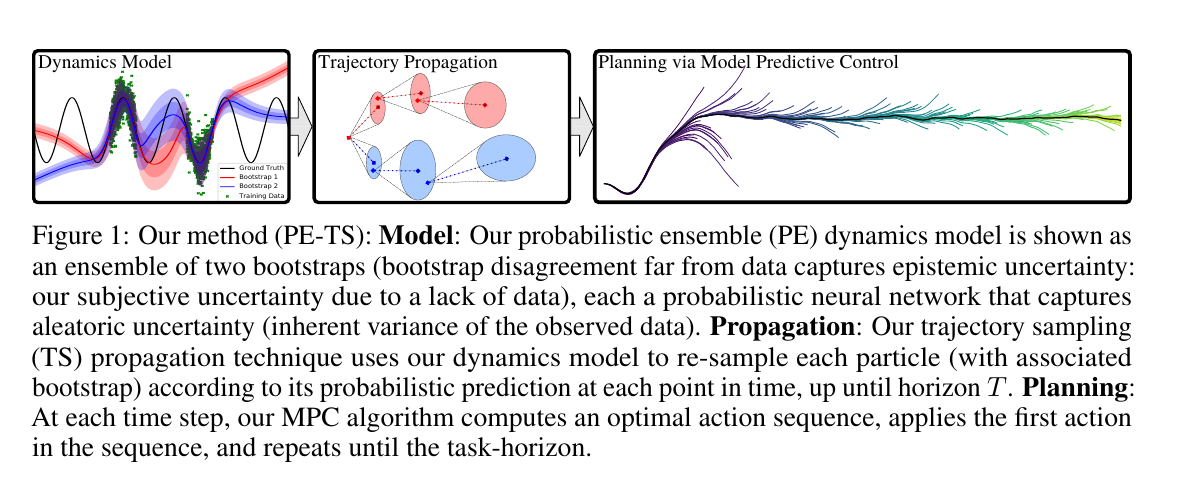
这里有两个很重要的细节。
第一,模型输出方差 可以描述 aleatoric uncertainty,也就是环境本身的随机性;不同模型成员之间的预测分歧可以描述 epistemic uncertainty,也就是数据不足导致的“不知道自己知不知道”。对具身机器人来说,第二种不确定性特别关键:如果几个模型对某个动作后果分歧很大,说明这片状态-动作空间还不可靠,规划时就应该保守。
第二,世界模型越往远处 rollout,误差越会累积。粗略地说,如果一步模型误差是 ,那么 步预测误差会随 增长:
这个公式不用当成严格定理来背。它想表达的是:一步只错一点,滚很多步以后也可能错很多。第 1 步预测错了,下一步又拿这个错误状态继续预测,错误就会沿着 rollout 传下去。这就是为什么很多成功的 MBRL 系统都不迷信长距离想象。PETS 用 MPC 每一步重新规划,MBPO[5] 只把模型用于短 rollout,Dreamer 则在压缩后的潜空间里想象未来,都是在降低 model bias 被放大的风险。
进阶代码:训练一个概率动力学模型
下面是一个最小化版本的 PyTorch 动力学模型。实际系统还会做输入归一化、模型集成、early stopping、奖励头和终止头,这里先保留最核心的数学对应关系。
import torch
import torch.nn as nn
class ProbabilisticDynamics(nn.Module):
def __init__(self, state_dim: int, action_dim: int, hidden_dim: int = 256):
super().__init__()
out_dim = state_dim + 1 # delta_state + reward
self.net = nn.Sequential(
nn.Linear(state_dim + action_dim, hidden_dim),
nn.SiLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.SiLU(),
)
self.mu = nn.Linear(hidden_dim, out_dim)
self.logvar = nn.Linear(hidden_dim, out_dim)
def forward(self, state: torch.Tensor, action: torch.Tensor):
h = self.net(torch.cat([state, action], dim=-1))
mu = self.mu(h)
logvar = self.logvar(h).clamp(-10.0, 2.0)
return mu, logvar
def gaussian_nll(mu: torch.Tensor, logvar: torch.Tensor, target: torch.Tensor):
inv_var = torch.exp(-logvar)
return 0.5 * ((target - mu) ** 2 * inv_var + logvar).mean()
def train_step(model, optimizer, batch):
state, action, reward, next_state = batch
target = torch.cat([next_state - state, reward.unsqueeze(-1)], dim=-1)
mu, logvar = model(state, action)
loss = gaussian_nll(mu, logvar, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
return loss.item()这段代码对应上面的 :模型不只预测均值 ,还预测每个维度的不确定性 logvar。在规划时,可以从这个高斯分布采样多个未来,也可以把不确定性加入惩罚项,让机器人避开模型没有把握的动作。
进阶代码:用 CEM 做 MPC 规划
有了模型以后,最直接的控制方式是 MPC:采样一批动作序列,用模型评估未来回报,留下精英序列更新分布,最后只执行第一步动作。下面的 CEM(Cross-Entropy Method)就是 PETS、MPC 类方法里常见的规划骨架。
@torch.no_grad()
def rollout_model(model, state, actions, discount=0.99):
# actions: [num_samples, horizon, action_dim]
num_samples, horizon, _ = actions.shape
state = state.expand(num_samples, -1)
returns = torch.zeros(num_samples, device=state.device)
gamma = 1.0
for t in range(horizon):
mu, logvar = model(state, actions[:, t])
pred = mu + torch.randn_like(mu) * torch.exp(0.5 * logvar)
delta_state, reward = pred[:, :-1], pred[:, -1]
state = state + delta_state
returns = returns + gamma * reward
gamma *= discount
return returns
@torch.no_grad()
def cem_plan(model, state, action_dim, horizon=15, iters=5, samples=512, elites=64):
mean = torch.zeros(horizon, action_dim, device=state.device)
std = torch.ones_like(mean)
for _ in range(iters):
actions = mean + std * torch.randn(samples, horizon, action_dim, device=state.device)
actions = actions.clamp(-1.0, 1.0)
scores = rollout_model(model, state, actions)
elite_actions = actions[scores.topk(elites).indices]
mean = elite_actions.mean(dim=0)
std = elite_actions.std(dim=0).clamp_min(1e-3)
return mean[0].clamp(-1.0, 1.0)注意这个规划器每次只返回 mean[0],也就是当前动作。执行完之后,智能体会拿到新的真实观测,再重新规划下一步。这种 receding horizon 的闭环,比一次性相信模型预测未来几十步稳得多。
MBRL 的三种用法
MBRL 并不是单一算法,而是一组把“模型”放进 RL 闭环的范式。
1. 用模型生成数据:Dyna 思路
Sutton 在 1991 年提出的 Dyna 架构[6] 可以看作 MBRL 的经典起点:智能体从真实环境中学一个模型,然后用模型生成额外经验,像真实经验一样更新价值函数。
这很像今天大模型训练里的“合成数据”:真实数据贵,模型生成的数据便宜。但问题也一样——生成数据如果有偏差,训练会把偏差放大。
# Dyna 风格的核心循环(伪代码)
for step in range(num_steps):
s, a, r, next_s = env.step(policy(s))
replay.add(s, a, r, next_s)
world_model.fit(replay)
for _ in range(planning_steps):
imagined_s, imagined_a = replay.sample_state_action()
imagined_next_s, imagined_r = world_model.predict(imagined_s, imagined_a)
value_fn.update(imagined_s, imagined_a, imagined_r, imagined_next_s)MBPO 可以看作现代版 Dyna:真实环境数据先进入 replay buffer,世界模型从 replay buffer 中学习,再从真实状态出发 rollout 少数几步,把短模型轨迹加入策略学习[5:1]。它的经验教训非常朴素:模型可以帮忙,但不要让模型幻想太久。
2. 用模型做规划:MPC、MCTS 与 MuZero
另一条路线是不一定直接用模型训练策略,而是在每一步决策时用模型向前搜索。
在连续控制中,常见做法是 MPC(Model Predictive Control,模型预测控制):每一步都用模型预测未来 步,选择累计奖励最高的动作序列,只执行第一步,然后重新观测、重新规划。这种“边走边重算”的方式特别适合机器人,因为真实世界总会偏离预测。
在棋类和 Atari 中,AlphaZero[7] 与 MuZero[8] 则使用树搜索。AlphaZero 依赖已知规则做 MCTS,MuZero 更进一步:它不需要真实规则,而是在学到的潜空间模型中做搜索。
3. 在潜空间里做梦:PlaNet、Dreamer 与 TD-MPC
像素级世界太复杂。机器人摄像头一帧图像可能有几十万维,直接预测未来像素既昂贵又容易关注无关细节。因此,现代 MBRL 往往先把观测压缩到潜空间,再在潜空间中预测未来。
PlaNet[9] 开始系统展示“从像素学习潜空间动力学,再用规划控制”的路线;Dreamer 系列[10][11] 则把想象轨迹用于 actor-critic 训练,让策略主要在 latent imagination 中学习。TD-MPC2[12] 继续把潜空间模型预测控制扩展到更大规模的连续控制任务。
直觉上,潜空间 MBRL 不要求模型重建每一个像素,而是只保留“对控制有用”的信息:机器人姿态、物体相对位置、速度趋势、接触状态等。
三大里程碑
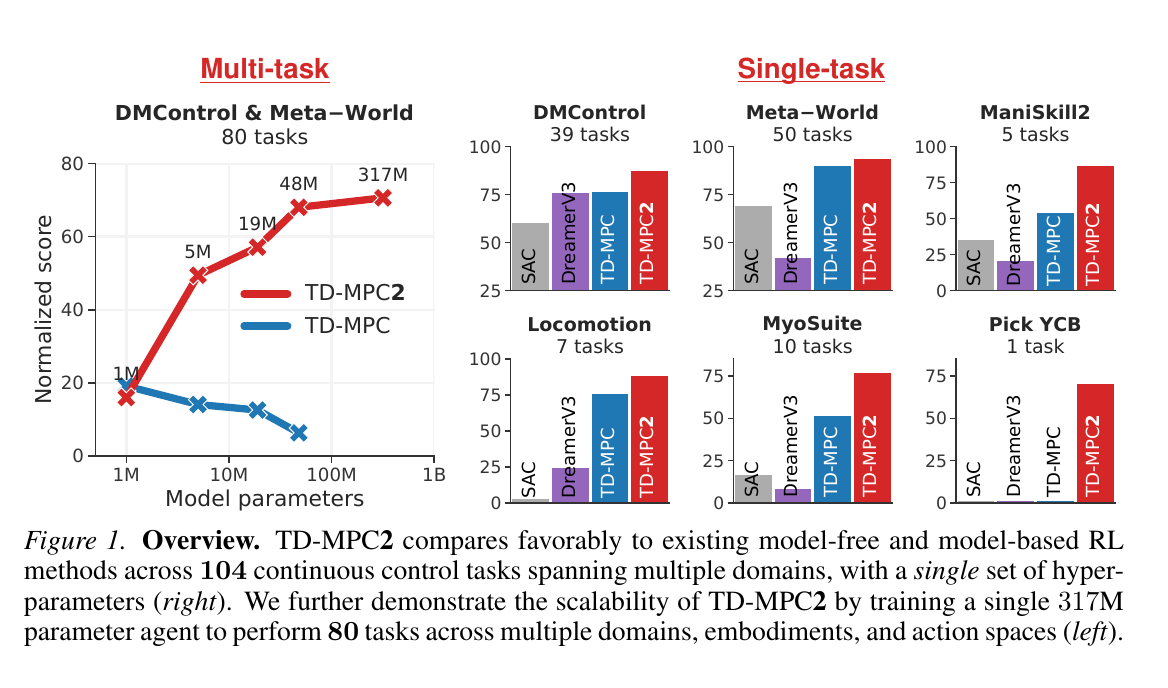
AlphaZero:已知规则中的搜索
AlphaZero 不是从人类棋谱中模仿,而是通过自我博弈学习。它用神经网络评估局面和先验动作,再用 MCTS 做深度搜索[7:1]。这里的“模型”不是学出来的神经网络动力学,而是棋类游戏的已知规则。
这个范式告诉我们:当环境模型足够准确时,规划可以显著提升决策质量。问题是,物理世界不像棋盘规则那么干净。
MuZero:不知道规则也能规划
MuZero 的突破在于:它不需要知道环境真实规则,却能学习一个适合规划的隐式模型[8:1]。这个模型不追求还原完整世界,只要能支持价值预测、奖励预测和策略搜索即可。
这对具身智能很有启发:机器人也许不需要学会“完整物理学”,只需要学到足够支持任务决策的动力学表征。
MuZero 的模型可以拆成三部分:
这行公式可以拆成三个小模型:
| 模块 | 输入 | 输出 | 作用 |
|---|---|---|---|
| $h_\theta$ | 历史观测 $o_{1:t}$ | 初始潜状态 $s_0$ | 把真实观测压缩成可规划状态 |
| $g_\theta$ | 潜状态 和动作 $a_k$ | 下一潜状态 、奖励 $r_{k+1}$ | 在脑内往前走一步 |
| $f_\theta$ | 潜状态 $s_k$ | 策略先验 、价值 $v_k$ | 告诉搜索哪些动作值得试、当前局面有多好 |
所以 MuZero 学的不是“下一帧像素长什么样”,而是“为了搜索,我需要知道的下一步潜状态、奖励、价值和动作先验”。训练损失也围绕这三件事展开:
这里 是展开步数。对每一步 ,loss 都检查三类预测:奖励预测 要接近真实或训练目标 ;价值预测 要接近目标价值 ;策略先验 要接近 MCTS 搜索得到的策略 。换句话说,MuZero 的模型只要对规划有用,不需要忠实重建整个世界。
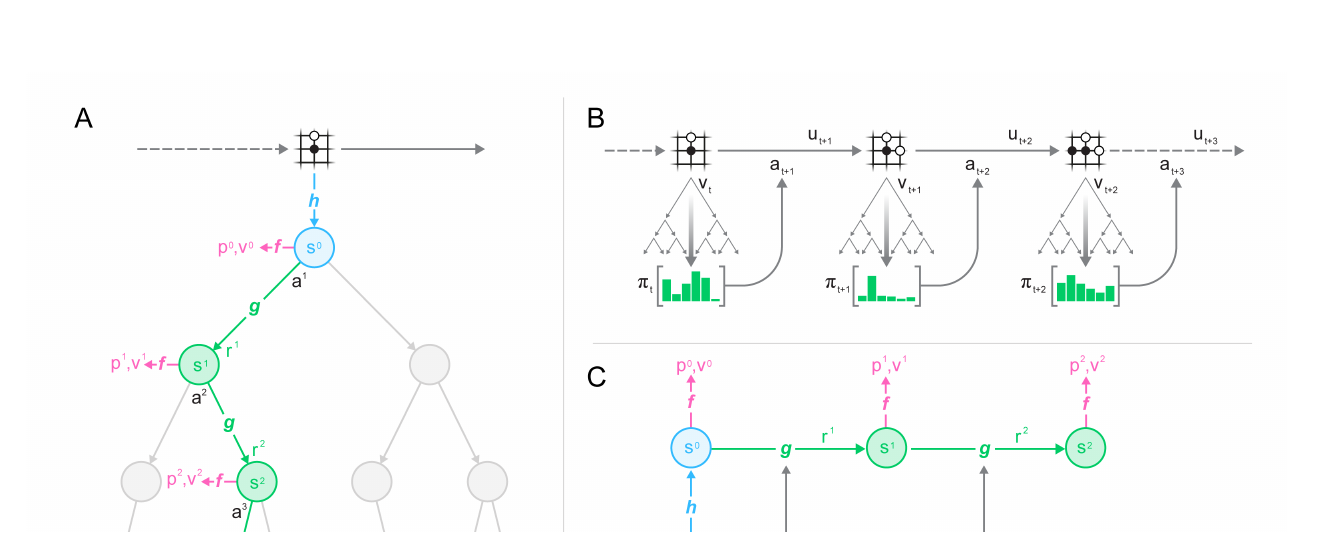
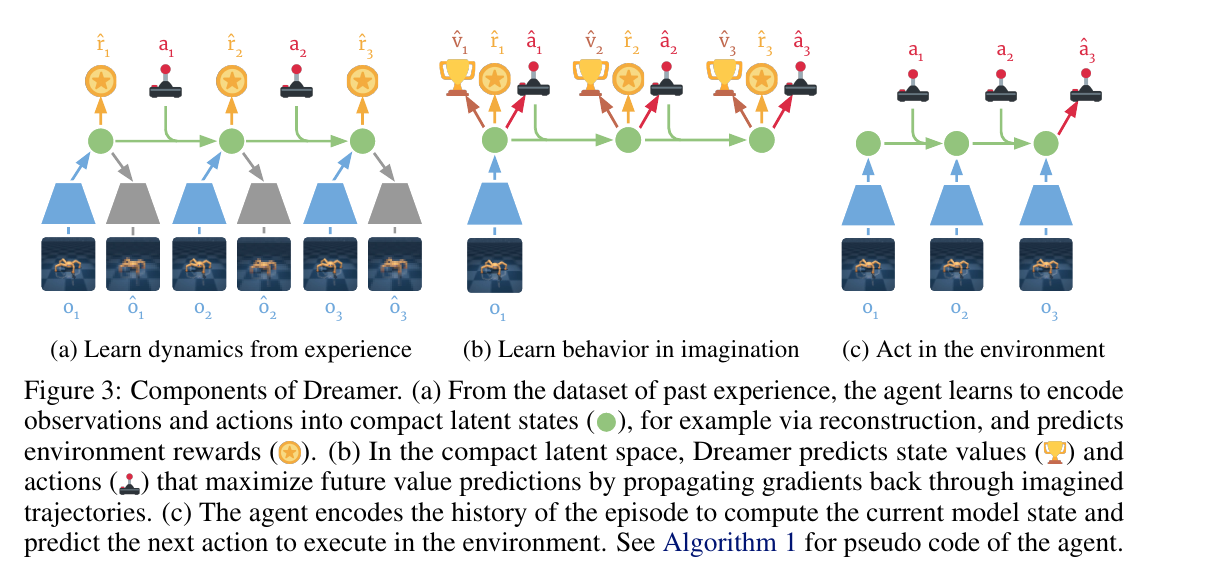
Dreamer:在想象中训练控制策略
Dreamer 系列把世界模型、潜空间表示和 actor-critic 训练结合起来[10:1][11:1]。智能体先从真实交互中学习 latent dynamics,然后在潜空间中 rollout 多条想象轨迹,用这些轨迹训练策略。
DreamerV3 的重要性在于统一性:同一套超参数和算法在视觉控制、连续控制、Atari、Minecraft 等不同领域取得了很强表现[11:2]。这让 MBRL 从“样本效率技巧”逐渐走向“通用智能体训练框架”。
Dreamer 的 RSSM(Recurrent State-Space Model)把潜状态分成确定性记忆 和随机变量 :
可以把 理解成“到目前为止的记忆”,把 理解成“当前这一步还有哪些不确定因素”。 根据上一时刻的记忆、随机状态和动作更新; 则结合当前观测 ,把真实看到的信息写进潜状态。
世界模型同时预测观测、奖励和继续概率:
这个 world model loss 有四部分:
| 项 | 在训练什么 |
|---|---|
| $-\log p_\phi(o_t\mid h_t,z_t)$ | 潜状态能不能解释当前观测 |
| $-\log p_\phi(r_t\mid h_t,z_t)$ | 潜状态能不能预测奖励 |
| $-\log p_\phi(c_t\mid h_t,z_t)$ | 潜状态能不能预测 episode 是否继续 |
| $\mathrm{KL}(q_\phi|p_\phi)$ | 让带观测的后验状态和只靠模型预测的先验状态不要差太远 |
前面三项是在问“这个潜状态够不够有用”;KL 项是在防止模型只在看到真实观测时才会工作,而在想象 rollout 时崩掉。
训练好世界模型后,actor 不必每一步都访问真实环境,而是在模型里最大化想象回报:
这个公式和前面的 RL 目标很像,只是数据来源变了。真实环境里的奖励是 ,Dreamer 想象轨迹里的奖励是 ;真实环境的转移来自物理世界,Dreamer 的转移来自学到的潜空间世界模型 。actor 参数是 ,训练目标就是让想象出来的平均回报变大。
| 算法 / 系列 | 世界模型类型 | 规划或训练方式 | 典型场景 |
|---|---|---|---|
| Dyna | 表格或函数近似动力学模型 | 用模型生成经验更新价值函数 | 经典 RL、教学范式 |
| PETS | 概率动力学模型集成 | MPC + 轨迹采样 | 低样本连续控制 |
| AlphaZero | 已知环境规则 | MCTS + 神经网络评估 | 围棋、国际象棋、将棋 |
| MuZero | 学到的隐式潜空间模型 | latent MCTS | 棋类、Atari |
| Dreamer | 潜空间 RSSM 世界模型 | latent imagination 训练 | 视觉控制、机器人、游戏 |
| TD-MPC2 | 任务条件潜空间动力学模型 | latent MPC + 策略学习 | 大规模连续控制、多任务 |
为什么具身智能特别需要 MBRL?
具身智能与 MBRL 天然贴合,原因不是“MBRL 更高级”,而是物理世界太贵、太慢、太危险。
- 真实交互昂贵:机器人采一条真实轨迹需要时间,失败还可能损坏硬件。MBRL 可以把一部分探索移到模型中。
- 安全约束更强:在模型里先排除危险动作,比让真机试错更稳妥。
- 任务需要预测未来:抓取、行走、避障都依赖短期动力学预测。只看当前状态,往往看不出动作后果。
- Sim-to-Real 需要不确定性:概率模型和模型集成可以估计“我有多不确定”,这对迁移到真实世界尤其重要。
MBRL 不是免费午餐
MBRL 的核心风险是 model bias:世界模型如果错了,规划会利用这个错误,策略也会在错误里越学越偏。PETS 使用概率模型集成来表达不确定性[4:1],Dreamer 选择在潜空间中学习紧凑动力学[10:2],本质上都是在控制模型误差的影响。
为什么大模型 RL 里较少提 MBRL?
本书第 8 章到第 10 章讨论了 DPO、PPO、GRPO 和 Agentic RL,但很少单独强调 MBRL。这不是因为 MBRL 不重要,而是因为 语言模型本身已经像一个语言世界模型。
当 LLM 做数学推理或多步工具调用时,它在 token 空间中预测后续文本、调用结果和中间状态。思维链可以看成一种内部规划,搜索和自我修正也可以看成“在语言空间里试走几步”。所以,LLM 领域更常说 test-time search、self-play、process reward,而不是传统机器人语境下的 dynamics model。
但物理世界不同。机器人不能只靠文本知识理解摩擦、接触、延迟和力矩。它需要从真实或仿真交互中学习“动作如何改变世界”。这就是为什么 MBRL 在具身智能中重新变得关键。
与视频世界模型的关系
近年的视频生成模型让一个问题重新变得具体:能不能把视频模型当作机器人的世界模型?
思路很诱人:给定当前画面和动作,模型生成未来几秒的视频;机器人在这些候选未来里选择最安全、最接近目标的一条。OpenAI 在 Sora 技术报告中也把大规模视频生成模型描述为理解和模拟物理世界的一条路径[13]。
但把视频生成直接用于控制还面临几个硬问题:
- 动作条件不足:视频模型知道“画面会怎样”,不一定知道“机器人施加某个力矩后会怎样”。
- 物理一致性不足:生成视频可能看起来合理,却违反接触、质量守恒或关节约束。
- 闭环控制困难:机器人控制需要几十到上千 Hz 的反馈,视频生成模型通常太慢。
- 奖励对齐不清晰:好看的未来视频不等于可执行、可安全到达的未来状态。
所以更现实的方向不是“直接用视频模型控制机器人”,而是把视频模型作为表征学习、数据生成、短期预测或仿真增强的一部分,再和 RL、MPC、机器人控制器结合。
论文阅读:几篇代表作到底解决了什么?
先读综述,再读算法论文。 如果想快速建立地图,可以先读三类综述:Ding 等人的总综述适合把“世界理解”和“未来预测”两条主线分开[1:1];Li 等人的 embodied AI 综述适合看功能、时间建模、空间表示三轴 taxonomy[2:1];Feng 等人的自动驾驶综述适合理解世界模型如何把感知、预测和规划合在一个工程闭环里[3:1]。下面这些算法论文,可以看成这个大地图里的关键节点。
PETS:解决“小样本控制”问题。 PETS 的标题里有一句 “in a handful of trials”,重点不是提出一个更大的神经网络,而是把概率动力学、模型集成和轨迹采样组合起来[4:2]。在数据很少的时候,模型不确定性比模型均值更重要;规划器要知道哪些未来可信、哪些未来只是模型瞎猜。
MBPO:解决“什么时候该相信模型”问题。 MBPO 的核心不是无限生成模型数据,而是证明并实验证明短模型 rollout 更可靠[5:2]。从真实状态出发想象 1 到 5 步,常常比让模型自己滚很久更稳。这一点对机器人尤其重要,因为接触误差一旦偏离,后续预测会迅速失真。
PlaNet 与 Dreamer:解决“像素太难预测”问题。 PlaNet 证明了可以从像素学习潜空间动力学并用于规划[9:1];Dreamer 进一步把想象轨迹用于 actor-critic 训练[10:3]。它们的共同思想是:控制不需要完整还原未来画面,只需要学到足以预测奖励和动作后果的 latent state。
MuZero:解决“模型不必像环境”问题。 MuZero 的模型服务于搜索,而不是服务于画面重建[8:2]。只要潜空间动力学能预测奖励、价值和策略先验,就能支持 MCTS。这一点和具身智能中的任务导向世界模型很接近:机器人也许不需要生成每个像素,只需要知道“这个动作会不会把杯子推倒”。
TD-MPC2:解决“连续控制如何规模化”问题。 TD-MPC2 把 latent model predictive control 扩展到更多任务和更大模型,并强调 decoder-free 的任务相关潜表示[12:1]。这条路线对具身智能很实用:与其让模型花大量容量重建视觉细节,不如把容量集中在价值、奖励和可控动力学上。
思考题:MBRL 会不会完全取代 Model-Free RL?
短期内不会。MBRL 的样本效率更高,但工程复杂度也更高,而且模型误差会带来额外风险。Model-Free 方法如 PPO、SAC 依然是具身 RL 的主力,特别是在 Isaac Lab 这类大规模并行仿真中,海量采样能直接弥补样本效率不足。
更可能的路线是融合:用 Model-Free 方法保证稳定优化,用世界模型提高样本效率、做安全过滤、生成想象轨迹或辅助规划。现代 Dreamer、TD-MPC2、MuZero 都不是“纯模型”系统,而是把模型、策略、价值函数和搜索结合起来。
与前面章节的联系
| 前面章节的概念 | 在 MBRL 中的对应 |
|---|---|
| MDP 转移概率(第 3 章) | 世界模型预测下一状态、奖励与终止概率 |
| DQN 与价值函数(第 4 章) | Dyna 用模型生成经验来更新价值函数 |
| 策略梯度与 Actor-Critic(第 5-6 章) | Dreamer 在想象轨迹上训练 actor 和 critic |
| PPO 的稳定训练(第 7 章) | 具身 RL 常用 PPO 先在仿真中获得强基线 |
| 具身智能(本节主文) | MBRL 解决真实交互昂贵、需要预测未来的问题 |
| 离线 RL(第 12.5 节) | 离线数据可用于预训练世界模型,再进行规划或策略优化 |
常见问题 QA
Q1:世界模型模拟的环境会学错吗?
会,而且这正是 MBRL 最核心的难点。世界模型不是物理世界本身,而是从有限数据中学出来的近似:
左边是学出来的世界模型,右边是真实环境。这里的 不是“完全相等”,而是“希望尽量接近”。现实里数据有限、传感器有噪声、接触动力学复杂,所以世界模型几乎一定会有误差。
只要 ,模型 rollout 就会有偏差。偏差通常有三类:
- 一步预测误差:模型对 、、终止概率的预测不准。
- 误差累积:模型预测出的 又被当作下一步输入,错误会沿着 rollout 放大。
- 模型被利用:规划器会主动寻找模型“过度乐观”的动作序列,这叫 model exploitation。
数学上,如果用总变差距离粗略表示一步模型误差:
这里 可以先理解成“两个概率分布有多不一样”。 取所有状态动作里的最大差异,相当于问:世界模型最坏的一步会错多少。
那么长期价值误差不会只按 线性出现,而会被折扣因子和规划长度放大。常见直觉形式是:
这行公式的重点不在常数,而在 这个分母。 越接近 1,智能体越重视长期未来,分母越小,误差放大的风险越大。也就是说,规划越长、越相信未来回报,模型错一点造成的价值偏差就可能越大。
这不是要背的定理,而是要记住一个工程事实:一步看起来很小的模型误差,在长期规划里可能变成很大的价值偏差。 MBPO 的论文标题就叫 “When to Trust Your Model”,它的核心结论是:模型生成数据很方便,但模型数据有偏差,所以要使用从真实状态分支出的短 rollout[5:3]。PETS 则用概率模型集成表达不确定性,避免规划器盲目信任单个模型[4:3]。
代码上,常见做法是在模型不确定时惩罚回报,或者直接提前停止想象:
@torch.no_grad()
def conservative_model_step(ensemble, state, action, beta=2.0, stop_threshold=0.5):
preds = torch.stack([model.sample(state, action) for model in ensemble])
mean_pred = preds.mean(dim=0)
uncertainty = preds.var(dim=0).mean(dim=-1)
delta_state, reward = mean_pred[:, :-1], mean_pred[:, -1]
reward = reward - beta * uncertainty
should_stop = uncertainty > stop_threshold
next_state = state + delta_state
return next_state, reward, should_stop所以答案不是“世界模型会不会错”,而是“错了以后系统能不能知道自己不确定,并把不确定性传给规划器”。成功的 MBRL 工程通常都在做这件事:短 rollout、模型集成、不确定性惩罚、真实数据回灌、每一步重新规划。
Q2:世界模型的计算开销会不会很大?
会增加开销,但要看你在用什么换什么。Model-Free 方法的主成本是环境交互和策略/价值网络更新;MBRL 额外多了两块成本:
这不是严格公式,而是工程账本。Model-Free 通常主要花钱在环境采样和策略更新;MBRL 还要额外训练世界模型,并且可能在每一步决策前做规划或想象 rollout。
如果每次决策都用 CEM/MPC 规划,计算量大约是:
这个式子可以直接按乘法读:CEM 做 轮;每轮评估 条候选动作序列;每条序列往前看 步;如果有 个模型成员,每一步还要跑多个模型; 是一次模型前向的成本。这个开销在实时机器人上不能忽略。
但 MBRL 换来的通常是 真实交互次数减少。PETS 在一些连续控制 benchmark 上用远少于 SAC/PPO 的环境样本达到接近表现[4:4];Dreamer 通过潜空间想象训练,在视觉控制任务上同时改善数据效率、计算时间和最终表现[10:4];TD-MPC2 则进一步强调 decoder-free 的潜空间世界模型,把规划放到紧凑 latent 中做[12:2]。
工程上可以这么判断:
| 场景 | 更适合的选择 |
|---|---|
| 仿真极便宜,可大规模并行采样 | PPO、SAC 等 Model-Free 强基线 |
| 真机交互昂贵或有安全风险 | MBRL、MPC、安全过滤、离线预训练 |
| 视觉输入维度高 | 潜空间 MBRL,如 Dreamer、TD-MPC |
| 实时控制频率很高 | 小模型、短 horizon、策略蒸馏 |
一个常见部署方式是:训练时用世界模型提高样本效率,部署时不一定每步都做昂贵规划,而是把规划结果蒸馏成一个快策略:
# 训练时:MPC 给出高质量动作
expert_action = cem_plan(world_model, state, action_dim)
# 蒸馏时:训练一个快策略模仿 MPC
policy_action = actor(state)
distill_loss = ((policy_action - expert_action) ** 2).mean()这也是为什么不能只问“世界模型贵不贵”,还要问“真实世界采样有多贵”。如果真实交互很便宜,Model-Free 可能更划算;如果真实交互要真机、人工、安全审批,世界模型的 GPU 开销反而便宜。
Q3:LeCun 说的世界模型,和 MBRL 里的世界模型有什么区别?
LeCun 的“世界模型”更像一个通用智能体架构里的核心模块,而不是某一个 RL 算法。LeCun 在 2022 年的 position paper 中提出:智能体需要可配置的预测式世界模型、内在代价函数、层次化的 JEPA/H-JEPA 表示,用来自监督学习、推理和规划[14]。
MBRL 里的世界模型通常写成:
它服务于控制:给定状态和动作,预测下一状态、奖励和终止。PETS、MBPO、Dreamer、MuZero 都属于这个大范畴,但它们的预测对象不同:PETS 预测低维状态差分,Dreamer 预测潜状态和奖励,MuZero 只预测对搜索有用的奖励、价值和策略先验。
LeCun/J(EPA) 路线更强调 在表示空间预测,而不是生成像素或直接预测奖励。I-JEPA 从图像上下文块预测目标块的表征,不依赖手工数据增强,也不要求像素级重建[15];V-JEPA 把这个思想扩展到视频,训练目标是预测视频特征,而不是用文本、负样本或像素重建监督[16]。
可以把几类“世界模型”放在一起看:
| 路线 | 预测什么 | 主要目标 |
|---|---|---|
| 经典 MBRL | 下一状态、奖励、终止概率 | 控制、规划、样本效率 |
| 视频生成世界模型 | 未来像素或视频片段 | 生成、仿真增强、表征学习 |
| LeCun/J(EPA) 路线 | 抽象表征、未来 embedding | 自监督表征、常识、层次规划 |
| MuZero/Dreamer 类 | 潜状态、奖励、价值或策略相关信息 | 只学对决策有用的模型 |
JEPA 的核心形式可以写成:
这行公式可以这样读:先用目标编码器 把目标区域 编成表示 ;再用上下文编码器 看可见区域 ,经过预测器 猜出目标表示 ;loss 让猜出来的表示靠近真实目标表示。 表示 stop-gradient,意思是目标那边只当作答案,不让梯度把答案本身也改掉。
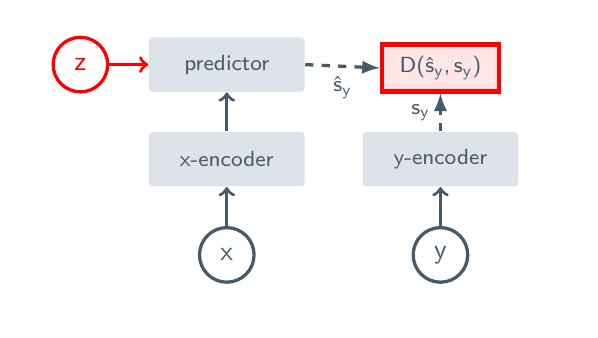
这里 是可见上下文, 是被遮住或未来的目标, 可以包含位置、时间或动作条件, 表示 stop-gradient, 是避免表示塌缩的正则项。和像素生成相比,它不要求模型把每个纹理细节复原出来;和传统 MBRL 相比,它也不一定直接输出奖励。2026 年的 LeWorldModel 进一步把 JEPA 从原始像素训练成可用于控制的端到端世界模型,这是这条路线向具身控制靠近的一个新例子[17]。
一句话总结:MBRL 的世界模型偏“控制工程”,LeCun 的世界模型偏“通用智能架构”;前者问动作后世界怎么变,后者问智能体如何学到可预测、可规划的抽象世界表征。
Q4:Model-Based 和 Model-Free 在数学上到底差在哪?
两者都在优化同一个 RL 目标:
也就是说,无论 Model-Free 还是 Model-Based,最终都希望策略拿到更高的长期回报。区别不在“目标是不是 reward 最大化”,而在 更新这个目标时,下一状态和未来回报从哪里来。
区别在于是否显式学习 。
Model-Free 不建模环境转移。它直接用真实或仿真采样到的 更新策略或价值函数。例如 Q-learning / SAC 风格的 critic 目标是:
这里的 来自真实 replay buffer,不来自模型预测。critic 相当于拿真实发生过的一步转移来构造答案 。
Model-Based 先学习一个模型:
这个 loss 的意思是:世界模型要给真实发生过的下一状态、奖励和终止标记更高概率。前面的负号来自最大似然训练:我们想最大化真实数据的概率,但优化器通常最小化 loss,所以写成负 log likelihood。
然后用这个模型规划:
这里的 和 都是模型想象出来的。规划器不需要真的把每条动作序列拿到环境里试,而是先在世界模型里估分。
或者用想象轨迹训练策略:
这个 和真实 RL 目标长得很像,但它的轨迹来自 ,不是来自真实环境 。所以数学差别不是“目标不同”,而是 梯度和数据从哪里来。Model-Free 的学习信号主要来自真实采样;Model-Based 多了一个可微或可采样的世界模型,学习信号可以从模型 rollout 中来。
Q5:Model-Based 和 Model-Free 在代码上怎么对比?
先看 Model-Free。这里没有 world_model,next_state 是 replay buffer 里真实出现过的下一状态:
# Model-Free: SAC / DDPG 风格的 critic 更新
state, action, reward, next_state, done = replay.sample()
with torch.no_grad():
next_action = actor(next_state)
target_q = target_critic(next_state, next_action)
y = reward + gamma * (1.0 - done) * target_q
q = critic(state, action)
critic_loss = ((q - y) ** 2).mean()
critic_loss.backward()
critic_optimizer.step()再看 Model-Based。代码里会多出一个模型训练步骤,以及一个用模型预测未来的规划或想象步骤:
# Model-Based: 先训练世界模型
state, action, reward, next_state, done = replay.sample()
target = torch.cat([next_state - state, reward, done], dim=-1)
mu, logvar = world_model(state, action)
model_loss = gaussian_nll(mu, logvar, target)
model_loss.backward()
model_optimizer.step()
# 再用世界模型生成 imagined transition
imagined_state = state
imagined_return = 0.0
discount = 1.0
for h in range(horizon):
imagined_action = actor(imagined_state)
pred = world_model.sample(imagined_state, imagined_action)
delta_state, imagined_reward, imagined_done = split_prediction(pred)
imagined_return += discount * imagined_reward
discount *= gamma * (1.0 - imagined_done)
imagined_state = imagined_state + delta_state
actor_loss = -imagined_return.mean()
actor_loss.backward()
actor_optimizer.step()这段对比说明了最本质的工程差异:
- Model-Free 的
next_state是数据集给的。 - Model-Based 的
imagined_state是模型滚出来的。 - Model-Free 代码更短、更稳、更依赖采样。
- Model-Based 代码更复杂、更省真实交互,但必须处理模型误差。
Q6:世界模型能不能替代真实仿真器?
短期内不能完全替代。物理仿真器(如 MuJoCo、Isaac Sim)是人写的近似物理引擎,世界模型是从数据里学出来的统计近似。前者有明确的几何、关节、碰撞、积分器;后者有更强的数据适应性,但也更容易在分布外状态犯错。
更实际的关系是互补:
- 仿真器生成数据:用大规模仿真轨迹预训练世界模型。
- 世界模型做快速近似:在 latent 中做短期规划,比高保真仿真便宜。
- 真机数据修正模型:用真实交互做 residual dynamics 或 domain adaptation。
- 安全过滤:世界模型先筛掉明显危险的动作,再交给低层控制器。
MuZero 的经验也说明:模型不一定要还原完整环境,只要能预测对规划有用的信息,就可以支持强搜索[8:3]。这对机器人很重要,因为“完整模拟世界”太难,但“预测杯子会不会被推倒、脚会不会打滑、夹爪会不会碰撞”更接近可解问题。
Q7:什么时候应该优先用 MBRL,什么时候继续用 Model-Free?
可以用一个简单判断:
优先考虑 MBRL:真实交互贵、失败代价高、需要短期预测、希望复用离线数据、任务对安全约束敏感、状态有明显动力学结构。机器人抓取、腿式 locomotion、自动驾驶边界场景、实验室真机控制,都属于这一类。
优先考虑 Model-Free:仿真环境很便宜、奖励清晰、并行采样容易、工程上需要一个稳定 baseline。PPO 在 Isaac Lab 这类并行仿真里仍然非常强,因为它可以用海量模拟步数抵消样本效率劣势。
最常见的现代路线是混合:先用 Model-Free 方法拿到稳定策略,再用世界模型提高样本效率、做安全过滤、生成短想象轨迹,或者在部署时用 MPC 修正策略动作。Dreamer、TD-MPC2、MuZero 这些代表算法,本质上都不是“纯模型”或“纯策略”,而是把模型、策略、价值函数和规划揉在一起。
Q8:为什么这里用 PETS?入门实践要不要直接做 PETS?
这里引用 PETS,是因为它的论文把 MBRL 的几个关键部件放在同一个可解释框架里:动力学模型、模型不确定性、trajectory propagation 和 MPC[4:5]。它特别适合回答“模型会不会学错、规划器为什么不能盲信模型”这类问题。
但入门实践不应该直接从 PETS 开始。更好的顺序是:
- 先做确定性世界模型:。
- 再做随机 shooting MPC:采样动作序列,用模型预测回报,执行第一步。
- 确认闭环有效后,再把单模型换成概率模型或模型集成。
数学上,最小版只学一个点估计:
PETS 则把预测变成分布,并用多个模型成员表示 epistemic uncertainty:
代码上,最小版是一个网络加 MSE loss;PETS 是多个概率网络加 Gaussian NLL,再在规划时对未来轨迹做采样传播。前者适合学习 MBRL 的骨架,后者适合处理真实机器人里更常见的数据少、噪声大、接触不确定的问题。
小结
Model-Free RL 学的是“怎么做”,Model-Based RL 还要学“这么做以后世界会怎样”。在交互便宜的数字环境中,Model-Free 往往足够直接;在机器人、自动驾驶、复杂操作这些物理任务中,世界模型能显著降低试错成本,并为规划、安全约束和泛化提供支点。
MBRL 的难点也很清楚:模型不可能完美,模型误差会被规划放大。真正有效的系统通常不是在 Model-Free 和 Model-Based 之间二选一,而是把世界模型、策略学习、搜索规划和真实反馈放进同一个闭环。
下一步可以回到具身智能主文,把这里的世界模型视角和 Sim-to-Real、域随机化、VLA 模型联系起来看。
参考文献:
Ding, J. et al. (2025). Understanding World or Predicting Future? A Comprehensive Survey of World Models. ACM Computing Surveys. https://arxiv.org/abs/2411.14499 ↩︎ ↩︎
Li, X. et al. (2025). A Comprehensive Survey on World Models for Embodied AI. https://arxiv.org/abs/2510.16732 ↩︎ ↩︎
Feng, T. et al. (2025). A Survey of World Models for Autonomous Driving. https://arxiv.org/abs/2501.11260 ↩︎ ↩︎
Chua, K. et al. (2018). Deep Reinforcement Learning in a Handful of Trials using Probabilistic Dynamics Models. NeurIPS. https://arxiv.org/abs/1805.12114 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Janner, M. et al. (2019). When to Trust Your Model: Model-Based Policy Optimization. NeurIPS. https://arxiv.org/abs/1906.08253 ↩︎ ↩︎ ↩︎ ↩︎
Sutton, R. S. (1991). Dyna, an Integrated Architecture for Learning, Planning, and Reacting. SIGART Bulletin. https://www.incompleteideas.net/papers/sutton-91dyna.pdf ↩︎
Silver, D. et al. (2017). Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm. https://arxiv.org/abs/1712.01815 ↩︎ ↩︎
Schrittwieser, J. et al. (2020). Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model. Nature. https://arxiv.org/abs/1911.08265 ↩︎ ↩︎ ↩︎ ↩︎
Hafner, D. et al. (2019). Learning Latent Dynamics for Planning from Pixels. ICML. https://arxiv.org/abs/1811.04551 ↩︎ ↩︎
Hafner, D. et al. (2020). Dream to Control: Learning Behaviors by Latent Imagination. ICLR. https://arxiv.org/abs/1912.01603 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Hafner, D. et al. (2023). Mastering Diverse Domains through World Models. https://arxiv.org/abs/2301.04104 ↩︎ ↩︎ ↩︎
Hansen, N. et al. (2024). TD-MPC2: Scalable, Robust World Models for Continuous Control. ICLR. https://arxiv.org/abs/2310.16828 ↩︎ ↩︎ ↩︎
Brooks, T. et al. (2024). Video generation models as world simulators. OpenAI. https://openai.com/index/video-generation-models-as-world-simulators/ ↩︎
LeCun, Y. (2022). A Path Towards Autonomous Machine Intelligence. OpenReview. https://openreview.net/forum?id=BZ5a1r-kVsf ↩︎
Assran, M. et al. (2023). Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture. CVPR. https://arxiv.org/abs/2301.08243 ↩︎
Bardes, A. et al. (2024). Revisiting Feature Prediction for Learning Visual Representations from Video. https://arxiv.org/abs/2404.08471 ↩︎
Maes, J. et al. (2026). LeWorldModel: A Unified End-to-End World Model for Autonomous Driving. https://arxiv.org/abs/2603.19312 ↩︎