4.5 动手:视觉游戏项目
前面几节已经把 DQN 的三个核心部件分开讨论过: Q 网络估计动作价值, 经验回放打散样本相关性, 目标网络稳定 TD Target。 4.3 已经把这些部件放进 LunarLander 中观察: 先看真实训练、评估回报和回放动画, 再看训练曲线、Q 值和消融实验。 到这里,低维状态任务已经完成了它的教学任务: 它让我们看清 DQN 如何在 8 个数字和 4 个离散动作之间学习动作价值。
本节要解决的是下一个问题: 如果状态不再是一组已经整理好的数字, 而是一帧帧游戏画面, DQN 还需要改变什么?
答案不是重写 TD Target。 从 LunarLander 到 Atari, 核心公式仍然是一步 TD 更新, 真正变化的是状态表示和训练条件: MLP 要换成 CNN, 单帧要变成帧堆叠, 短实验要变成带评估、checkpoint 和可视化回放的长实验。 最后,ViZDoom、宝可梦和 Minecraft 用于说明边界: 动作离散并不意味着朴素 DQN 一定适合。
本节导读
核心内容
- 用 LunarLander 作为参照,解释从低维状态迁移到像素输入时,真正新增的问题是表示学习和训练条件,而不是 TD Target 本身。
- 说明 CNN、帧堆叠、Atari wrapper、延迟学习和评估回调分别解决什么问题。
- 给出一个真实可训练的 Pong DQN 实验,并用曲线和多个 checkpoint GIF 展示策略从失败到会玩的变化。
- 给出一套选择 DQN 任务的判断标准:Atari、Classic Control、LunarLander、GridWorld、小型 2D 游戏和自定义离散动作任务。
- 在附录中用 ViZDoom、宝可梦和 Minecraft 作为边界案例,理解部分可观测、稀疏奖励和长时规划为什么会让朴素 DQN 变吃力。
核心公式
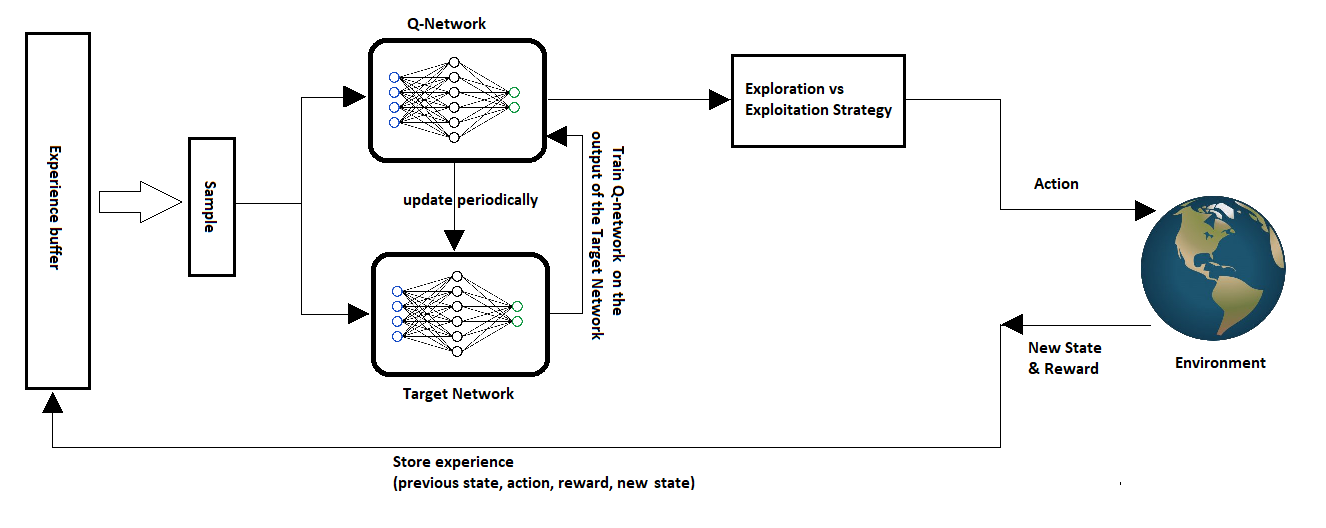
第一行构造目标值: 一条经验给当前动作提供了一个学习目标。 第二行计算误差: 当前 Q 网络给出的 与目标值之间相差多少。 经验回放决定这批样本从哪里来, 目标网络决定 使用哪套参数计算, 梯度下降则推动 向误差更小的方向移动。
4.5.1 从低维状态到屏幕像素
在 LunarLander 中,环境已经替我们整理好了状态:x、y、速度、角度、角速度和两条支架是否接触地面。Q 网络接收 8 个数字,输出 4 个动作价值。前面的 4.3 已经用这个任务看过训练曲线、评估回报和回放动画;那里关心的是 DQN 能不能在低维控制任务中稳定学到动作偏好。
视觉游戏把问题往前推了一步。Pong 中,智能体一开始并不知道“球在哪里”“球往哪里飞”“球拍离球有多远”。它看到的是屏幕像素。也就是说,网络不仅要估计动作价值,还要先从图像中抽取可用于决策的状态表示。
这个变化很关键。TD Target 仍然是
但 的含义已经变了:它不再是一行人为整理好的物理量,而是经过预处理的图像帧。于是,训练的中心问题也随之改变:不是重新发明 DQN,而是让 DQN 在像素输入、帧堆叠、卷积网络和更长训练时间下仍然保持稳定。
因此,本节后面的实验不再重复 LunarLander 的训练闭环,而是把它作为参照:低维状态用 MLP 估计动作价值;像素状态要先用 CNN 学表示,再输出动作价值。只要抓住这个差别,就能看清 Atari DQN 中每个工程设置的必要性。
4.5.2 从向量到像素
DQN 真正引起广泛关注,来自它在像素输入任务上的表现。
DeepMind 2015 年发表在 Nature 上的论文[1]展示了一个程序:只使用屏幕像素和游戏得分,就在 29 种 Atari 游戏中达到人类水平。这个结果的意义不只是网络变大,而是说明 Q-Learning 可以和表示学习结合——智能体不再需要人手提供球的位置、速度和距离,而是从图像中直接学习这些决策线索。
下面的架构图展示了 DQN 如何从原始像素出发,经过卷积网络输出每个动作的 Q 值:
LunarLander 的状态是 8 个数字,Q 网络只需要一个 MLP。Atari Pong 的状态则是一张屏幕:输入是像素,不是球和球拍的显式坐标。此时不需要改变 TD Target,DQN 的学习目标仍然是
改变的是 中的状态表示。
网络必须先从图像中学习有用特征,再输出动作价值。LunarLander 中的问题是:如何用 8 个数字估计动作价值。Atari 中的问题变成:如何先把屏幕变成可用于决策的表示。
这个区别最直接的体现是状态和网络的组合。
LunarLander 用 8 维向量配 MLP,关键困难是控制噪声和训练波动,可以作为课堂短训练。Atari Pong 用 4 帧堆叠的 84×84 图像配 CNN 加全连接层,关键困难是从像素中提取位置、速度和运动方向,训练成本通常需要数百万到千万级环境步。
其中最关键是状态表示。
单张图像只显示"球在哪里",无法显示"球往哪里走"。连续几帧放在一起,网络才能从位置变化中推断速度和方向。帧堆叠的作用,是把静态图片变成包含短期运动信息的状态。
Gymnasium 提供了常用预处理。下面的代码用于理解输入形状,但还不是完整训练实验——它回答的基础问题是:如何把游戏画面整理成 CNN 能处理的张量。
import gymnasium as gym
def make_atari_env(game_id="ALE/Pong-v5"):
env = gym.make(game_id)
env = gym.wrappers.AtariPreprocessing(
env,
grayscale_obs=True,
scale_obs=True,
frame_skip=4,
)
env = gym.wrappers.FrameStackObservation(env, stack_size=4)
return env
env = make_atari_env()
state, _ = env.reset()
print(state.shape) # (4, 84, 84)这段代码包含三步:灰度化减少颜色维度,缩放到 84×84 降低计算量,帧堆叠保留运动信息。处理后,输入从原始游戏画面变成适合 CNN 的张量。这一步还没有开始学习,只是把观测整理成可学习的形式。
像素状态表示
class CNNQNetwork(nn.Module):
def __init__(self, input_channels=4, num_actions=6):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(input_channels, 32, kernel_size=8, stride=4),
nn.ReLU(),
nn.Conv2d(32, 64, kernel_size=4, stride=2),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, stride=1),
nn.ReLU(),
)
self.fc = nn.Sequential(
nn.Linear(64 * 7 * 7, 512),
nn.ReLU(),
nn.Linear(512, num_actions),
)
def forward(self, x):
x = x / 255.0
x = self.conv(x)
x = x.view(x.size(0), -1)
return self.fc(x)这不是一套新算法。网络仍然输出每个动作的 Q 值,仍然使用经验回放和目标网络训练。变化发生在前半段:网络从读取 8 个数字,变成读取图像局部结构。卷积层学习边缘、形状和运动线索,全连接层再把这些线索合成动作价值。
MLP 与 CNN 的区别在于输入假设。MLP 假设每个输入维度已经是有意义的状态特征;CNN 则假设空间邻近的像素之间存在局部结构。对于 Pong,球、球拍和边界都由局部像素组成,卷积正适合提取这些模式。
和 LunarLander 相比,Atari 版本的训练条件也有明显变化。
像素有空间结构,MLP 展平后会浪费这种结构,因此需要 CNN。单帧无法判断运动方向,因此需要帧堆叠。图像状态更多样,回放池容量、学习起点和探索退火要按已验证配置共同选择。不同 Atari 游戏奖励尺度不同,需要奖励裁剪来统一训练信号。CNN 参数更多,训练时更容易出现不稳定更新,因此需要梯度裁剪。像素任务更难,目标网络需要保持更长时间的稳定性,因此同步频率更慢。
因此,从 LunarLander 到 Atari 的迁移不是简单替换 env_id。
TD 学习的骨架没有变;变复杂的是状态表示和训练条件。教学片段可以说明原理,但要把实验按完整的 Atari 流程跑起来,还需要补上环境预处理、评估和保存等实验环节。
4.5.3 Pong:一个完整的 Atari 实验
在继续看 Pong 之前, 需要先把"Atari"这个词说清楚。 如果读者没有接触过经典游戏基准, 很容易把 Atari 理解成某一个游戏。 但在深度强化学习语境里, Atari 通常不是指单个游戏, 而是指一组运行在 Atari 2600 模拟器上的经典游戏环境。
Atari 是什么
Atari 2600 是 1970 年代末到 1980 年代的一代家用游戏主机。 画面简单,动作是有限个按键组合,奖励直接来自游戏分数—— 这三个特征恰好对应强化学习的观测、动作和奖励。
把 Atari 变成深度 RL 标准基准的是 ALE(Arcade Learning Environment)。[2] ALE 把几十款 Atari 2600 游戏包装成统一接口: reset() 开始一局,step(action) 执行动作,返回图像观测、奖励和终止信息。 同一个 DQN 程序从 Pong 换到 Breakout 或 Space Invaders,只需要改一个环境 ID。
在本章里,Atari 的角色类似"像素版 CartPole",但难度高了一档: CartPole 把状态整理成 4 个数字交给你, Atari 只给画面——球在哪里、往哪飞、球拍离球多远,都得从 84×84 灰度帧里自己学。
ALE 里有几十款游戏,难度差异很大。 本节选 Pong 做主实验:两个球拍、一个球,先到 21 分获胜。 画面里物体少,动作只有上下,反馈极短——接住球或丢分几乎立刻发生。 简洁的画面和极短的反馈链,让 Pong 成为像素 DQN 最自然的起点。
其他 Atari 游戏在哪里
Pong 之外,ALE 还提供了 Breakout、Space Invaders、Seaquest 等几十款游戏, 安装 gymnasium[atari,accept-rom-license] 和 ale-py 后通过 Gymnasium 环境 ID 即可创建。[3] 训练脚本不变,还是 code/chapter04_dqn/dqn_atari_sb3.py,换游戏只需改 --env-id:
python code/chapter04_dqn/dqn_atari_sb3.py \
--env-id BreakoutNoFrameskip-v4 \
--total-timesteps 5000000 \
--learning-starts 100000 \
--optimize-memory-usage下面列出几款常见 Atari 游戏。 NoFrameskip-v4 名称更适合和 SB3 / RL-Zoo 的传统 DQN 配置对齐; ALE/...-v5 是 Gymnasium / ALE 新版命名。 本节代码同时兼容这两类名称, 但为了避免默认帧跳过和 sticky action 造成混淆, 主实验采用 PongNoFrameskip-v4。
下表中的动图由 ALE 环境直接渲染, 只用于帮助建立任务直觉, 不代表 DQN 已经训练成功。
| 画面 | 游戏 | 常用环境 ID | 新版环境 ID | 适合观察的问题 |
|---|---|---|---|---|
 | Pong | PongNoFrameskip-v4 | ALE/Pong-v5 | 球、球拍和短反馈链,最适合作为起点 |
 | Breakout | BreakoutNoFrameskip-v4 | ALE/Breakout-v5 | 击球、砖块消除和较清楚的像素结构 |
 | Space Invaders | SpaceInvadersNoFrameskip-v4 | ALE/SpaceInvaders-v5 | 横向移动、射击和敌人下压 |
 | Beam Rider | BeamRiderNoFrameskip-v4 | ALE/BeamRider-v5 | 横向躲避、射击和速度变化 |
 | Enduro | EnduroNoFrameskip-v4 | ALE/Enduro-v5 | 赛车、超车和连续视觉判断 |
 | Ms. Pac-Man | MsPacmanNoFrameskip-v4 | ALE/MsPacman-v5 | 迷宫、追逐和更强的部分可观测性 |
 | Qbert | QbertNoFrameskip-v4 | ALE/Qbert-v5 | 平台跳跃、空间位置和阶段性奖励 |
 | Seaquest | SeaquestNoFrameskip-v4 | ALE/Seaquest-v5 | 氧气、潜水员、敌人和更长的目标依赖 |
本地的 Atari 环境可以用以下命令列出:
python - <<'PY'
import gymnasium as gym
import ale_py
gym.register_envs(ale_py)
for env_id in sorted(gym.envs.registry):
if env_id.startswith("ALE/") or env_id.endswith("NoFrameskip-v4"):
print(env_id)
PY接下来回到 Pong 实验。CNN 和帧堆叠解决了状态表示,但要把训练跑稳,关键不在网络多深,而在环境预处理、探索、回放池、学习起点和评估是否统一组织好。CleanRL、Stable-Baselines3 和 RL-Zoo 的 Atari DQN 实现风格不同,但实验结构一致:先用 wrapper 标准化环境,再让 DQN 在足够长的交互中积累经验。[4] [5] [6] [7]

实验设置
Pong 的规则很直观:像素输入、离散动作、短反馈链。画面上方左右两个数字分别是对手和智能体的当前比分;智能体控制右侧绿色球拍,每赢一球得 +1,每输一球得 -1,一局打到 21 分结束。
回报和比分的区别。 一局结束后的累计回报等于"智能体得分 − 对手得分",它不是某一刻的比分,而是整局的净结果。例如 0:21 输掉的局,回报为 0 − 21 = −21;21:19 赢下的局,回报为 21 − 19 = +2。评估时取多局的平均值,得到"评估平均回报"——它反映的是策略整体赢多还是输多,而不是某一局的实时比分。
判断学得好不好,看的是评估平均回报落在哪个区间:-21 表示几乎每局都被打穿;0 附近说明已经能和对手拉锯;正回报才意味着策略整体开始稳定赢球。
这里有一个常见误解需要澄清:球拍会动,不等于学会 Pong。随机策略或刚起步的网络也可能让球拍移动,但这往往只是反复输出同一个动作,或者碰巧跟上了几帧。真正的判断标准,是在多局确定性评估中,平均回报持续脱离 -21,逐步接近并超过 0。
本节使用 PongNoFrameskip-v4 作为主实验环境。这样选不是因为 ALE/Pong-v5 不能训练,而是为了和 SB3 / RL-Zoo 已验证的 Pong DQN 链路保持一致,减少环境版本、默认帧跳过和 sticky action 带来的额外差异。算法入口是 code/chapter04_dqn/dqn_atari_sb3.py,基于 Stable-Baselines3 的 DQN("CnnPolicy", ...) 实现。它不再是前面那个手写 CNN 的教学片段,而是一套包含 Atari wrapper、经验回放、目标网络、评估回调和模型保存的完整训练脚本。
在这个实验里,左边的橙色球拍是对手,右边的绿色球拍是智能体控制的一侧。这个区分对人类读者很直观,但对 DQN 来说,输入并不是“左边是对手、右边是自己”这样的符号说明,而只是像素画面。经过 Atari wrapper 之后,图像会先缩放为 84×84 灰度图,再把连续 4 帧堆叠起来,并按通道优先的形式送入 CNN。动作空间是 Pong 的离散摇杆动作,包括 NOOP、FIRE、RIGHT、LEFT、RIGHTFIRE 和 LEFTFIRE。所以,网络真正要学的不是记住“绿色代表自己”,而是从像素在屏幕中的位置、亮度和运动变化里恢复球的位置、速度和方向,并把这些信息转化为稳定的防守和击球动作。
训练结果
Atari Pong 的短实验只适合检查管线:ALE 环境能否启动,wrapper 是否正确接入,CNN policy 能否输出动作,评估、保存和 GIF 渲染能否跑通。如果要真正展示策略学到了什么,还是要看长实验。 也就是说,要先固定好环境、回放池、探索退火和评估频率,再用多个 checkpoint 展示策略从失败到会玩的变化。
复现实验与导出素材
pip install -r code/chapter04_dqn/requirements.txt
# 与成功链路对齐的长实验:观察评估回报是否持续脱离随机水平
python code/chapter04_dqn/dqn_atari_sb3.py \
--env-id PongNoFrameskip-v4 \
--total-timesteps 10000000 \
--buffer-size 10000 \
--learning-starts 100000 \
--exploration-fraction 0.1 \
--exploration-final-eps 0.01 \
--eval-freq 250000 \
--eval-episodes 5 \
--checkpoint-freq 500000 \
--optimize-memory-usage \
--output-dir output/dqn_atari_long \
--run-name PongNoFrameskip-v4_dqn_seed0_10m_zoo_aligned \
--no-swanlab \
--device auto训练日志会写到 output/dqn_atari_long/PongNoFrameskip-v4_dqn_seed0_10m_zoo_aligned/。 观察训练过程时, 应优先看评估回报是否逐渐脱离随机水平, 而不是只看 loss 是否下降:
tensorboard --logdir output/dqn_atari_long
# 将本地 eval CSV 重新导出为讲义图片
python code/chapter04_dqn/export_dqn_curves.py --run pong渲染 GIF 时使用同一个脚本,只需要替换 checkpoint 和输出路径:
python code/chapter04_dqn/render_atari.py \
--env-id PongNoFrameskip-v4 \
--model output/dqn_atari_long/PongNoFrameskip-v4_dqn_seed0_10m_zoo_aligned/checkpoints/dqn_atari_500000_steps.zip \
--output docs/chapter04_dqn/images/dqn-atari-pong-500k.gif \
--max-steps 1800 \
--render-every 6 \
--fps 20 \
--scale 2如果要渲染 1M 和当前 best model,把 --model 分别换成 checkpoints/dqn_atari_1000000_steps.zip 和 best_model/best_model.zip, 并把 --output 改成对应的 GIF 文件即可。
本节实际运行的是一条按成功链路配置启动的长实验。完整 10M 环境步通常是隔夜级实验;在一台本地 MPS 机器上,训练到 1.25M 已经需要数小时,跑满 10M 还要继续等待十几个小时。因此,讲义先截取前 1.25M 的评估曲线和三个 checkpoint,用它们展示策略从失败到明显会玩的变化。
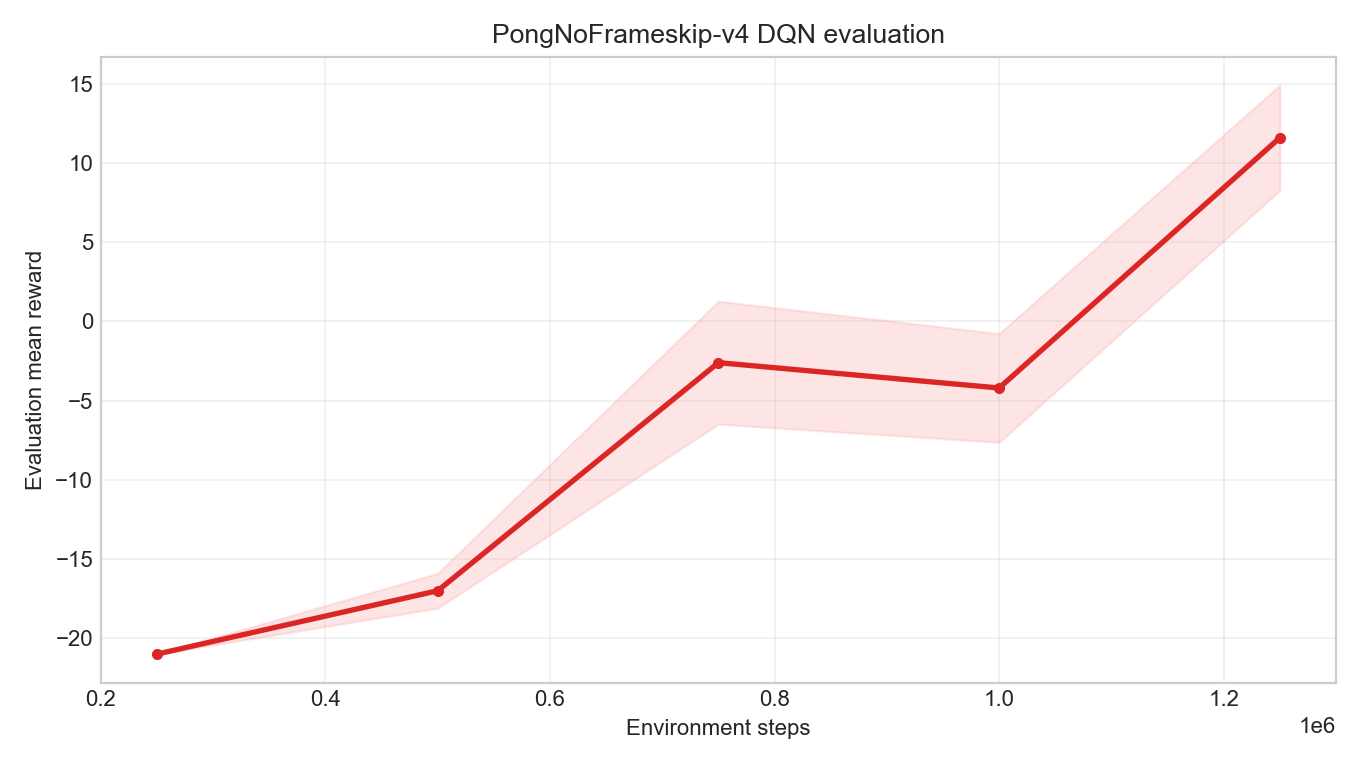
| 训练步数 | 评估平均回报 | 标准差 | 平均 episode 长度 | 含义 |
|---|---|---|---|---|
250k | -21.0 | 0.0 | 3056 | 确定性策略仍然几乎整局输掉 |
500k | -17.0 | 1.10 | 10550 | 开始能延长回合,但仍明显偏弱 |
750k | -2.6 | 3.88 | 11297 | 已经接近打平,策略开始形成有效防守 |
1M | -4.2 | 3.43 | 15637 | 评估仍有波动,但不再是全输策略 |
1.25M | 11.6 | 3.32 | 13830 | 评估均值转正,说明策略已经明显好过随机和早期 DQN |
这张曲线比单张 GIF 更重要。单局回放会受开局随机性影响,可能看起来特别好或特别差;评估曲线则把多个 episode 的均值和波动放在一起,能回答“策略是否整体变好”。从 250k 到 1.25M,回报不是平滑单调上升,而是在波动中跨过 0。这正是强化学习实验常见的样子:策略更新不是每一步都带来可见进步,但足够长的评估序列会暴露趋势。
下面三段 GIF 对应不同训练阶段。它们不是三种算法,而是同一条 DQN 训练链路的三个 checkpoint。
500k checkpoint:开始防守,但仍然偏弱。
这个阶段的评估均值是 -17.0。智能体已经不再像未训练网络那样只重复一个动作,球拍会尝试跟随球,但跟球时机和移动幅度仍不稳定。训练已经开始产生效果,但还不能说学会 Pong。

1M checkpoint:策略进入过渡阶段。
这个阶段的确定性评估均值仍为 -4.2,但某些单局回放已经能看到正回报。这提醒我们不要用一个 episode 判断算法成败:单局好看不等于稳定学会,评估均值和方差仍然要一起看。

1.25M best model:评估均值转正。
这个阶段的 5 局评估均值达到 11.6,下方渲染的这段单局回放回报为 +17(智能体 21:4 获胜)。这时才适合说智能体已经学到有效 Pong 策略:它不是只会移动球拍,而是能从像素帧中判断球的位置和运动方向,并把球拍移动到可防守的位置。

关键设置
Atari DQN 的关键不在某个单独的超参数, 而在一组相互配合的训练条件。 这些条件分别回答三个问题: 观测如何整理, 样本如何积累, 训练如何稳定。
| 训练条件 | 实现中的位置 | 作用 |
|---|---|---|
AtariWrapper | make_atari_env(...) | 自动接上 no-op reset、max-and-skip、life-loss episode、Fire reset、84×84 预处理和奖励裁剪 |
VecFrameStack(..., 4) | build_env | 把 4 帧合成一个状态,让网络看到运动方向 |
CnnPolicy | DQN("CnnPolicy", ...) | 使用适合像素输入的卷积特征提取器 |
buffer_size=10000 | DQN 参数 | 与已验证的 RL-Zoo Pong DQN 链路对齐,避免早期大量失败经验在过大的回放池中保留过久 |
learning_starts=100000 | DQN 参数 | 先填充回放池,避免网络从极少量连续样本里过早学习 |
exploration_fraction=0.1 | DQN 参数 | 在前 10% 训练步内把 epsilon 从 1.0 降到 0.01,让前期充分探索,后期逐渐转向利用 |
train_freq=4 | DQN 参数 | 不必每一帧都更新,降低相关样本带来的抖动 |
target_update_interval=1000 | DQN 参数 | 避免 TD Target 随在线网络每步同步变化 |
optimize_memory_usage=True | DQN 参数 | 降低 Atari replay buffer 的内存占用,使本地长训练更可行 |
EvalCallback 和 checkpoint | callbacks | 在长训练过程中持续保留评估结果和模型状态 |
这些处理弥补了教学片段中省略的训练条件。 NoopReset 让每局开头不完全一样, 避免智能体只适应固定开局。 EpisodicLife 把丢一条命视作训练 episode 的结束, 使 Pong、Breakout 这类游戏更快暴露错误动作的后果。 MaxAndSkip 每 4 帧重复一次动作并取相邻帧最大值, 既降低计算量, 也减轻 Atari 闪烁画面对观测的干扰。[6:1]
如果使用 Gymnasium 的 ALE/Pong-v5 这类环境, 还要注意它本身可能带默认帧跳过和 sticky action。 此时训练入口会显式将环境构造参数设为 frameskip=1、repeat_action_probability=0.0, 再交给 AtariWrapper 统一处理。 本节主实验直接采用 PongNoFrameskip-v4, 目的也是让 frame skip 只由 wrapper 控制, 并和已经验证过的 Pong DQN 训练链路保持一致。
资源预期也应当跟实验问题对应起来。 如果只是确认环境、wrapper、评估和保存流程是否连通, 100k 到 200k 环境步已经足够; 这类实验在 CPU 上也能完成, 只是速度较慢。 如果目标是观察 Pong 的学习趋势, 通常需要 1M 到 2M 环境步, 并且更适合使用 GPU。 若要接近常见 Atari DQN 训练设置, 步数往往会扩大到 5M 到 10M, 此时需要保存 checkpoint、评估均值、方差和必要的视频回放。
Atari DQN 能够稳定训练, 关键不在于额外隐藏了某个新算法, 而在于这些稳定训练的条件是否齐全: 图像被压到合适尺寸, 状态包含运动信息, 奖励尺度被裁剪, 回放池足够大, 学习开始得足够晚, 目标网络更新得足够慢, 训练过程包含评估和保存。 CleanRL、RL-Zoo 和 SB3 的实现风格不同, 但对 Atari DQN 的核心判断是一致的。
4.5.4 其他可以尝试的 DQN 任务
除了前面的 LunarLander 和 Atari,还有更多环境适合作为 DQN 的练习入口。
只要动作离散、观测足够决策、奖励能在合理时间内反馈,就可以把 DQN 当作基线来试。但"适合"不等于"放进去就能跑"——在动手之前,有四个条件值得先过一遍。
什么样的任务适合 DQN
动作空间要能写成 0, 1, ..., n_actions-1 的离散集合。
这样 Q 网络的输出层才能一一对应。如果任务要求连续转向角、油门大小或机械臂力矩,朴素 DQN 就不再自然,应该考虑 DDPG、TD3、SAC 这类连续动作算法。
观测也要足够用来决策。
当前帧或帧堆叠应该包含关键信息。如果当前画面看不见敌人位置、任务进度藏在很长的历史里,只看当前帧的 DQN 就会缺少信息,需要增加帧堆叠、加入 RAM 特征,或者换成带记忆的网络。
奖励要能在合理时间内反馈出来。
DQN 通过 TD Target 把未来回报一步步传回。如果回放池里长期只有负样本或无意义转移,网络就不知道早期哪个动作有用。这不是公式写错了,是学习信号离动作太远。
最后,ε-贪心探索要能产生有效经验。
当动作组合太多、episode 太长、失败反馈太晚时,随机探索可能长时间收集不到有意义样本。这时需要缩小动作集合、设计阶段性奖励,或者换用更适合长时探索的方法。
不满足这些条件并不意味着 DQN 完全不行,而是说明需要额外设计:动作连续就换算法,观测缺失就加记忆,奖励稀疏就做工程或分解任务。
在这些条件之下,任务可以按状态表示的复杂度大致分成三类。
低维起点:Classic Control
Gymnasium 的 CartPole、MountainCar 和 Acrobot 给出低维连续状态,但动作空间是离散的。
以 CartPole 为例,状态只有小车位置、速度、杆的角度和角速度四个数,动作只有向左和向右两个选择。这类任务适合作为第一批 DQN 实验,因为失败原因容易定位:如果 CartPole 学不起来,通常说明学习率、探索衰减、回放池或目标网络中至少有一处不合适。
MountainCar 的状态更短,只包含位置和速度,但奖励更稀疏。
智能体需要通过左右摆动积累势能才能到达山顶。同样是低维控制任务,MountainCar 通常比 CartPole 更能体现探索策略的重要性。
实验入口:Classic Control
cd code
pip install -r chapter04_dqn/requirements.txt
python chapter04_dqn/dqn_gym_sb3.py \
--env-id CartPole-v1 \
--total-timesteps 100000 \
--learning-starts 1000
python chapter04_dqn/dqn_gym_sb3.py \
--env-id MountainCar-v0 \
--total-timesteps 300000 \
--learning-starts 5000在 CartPole 中,若评估回报接近环境上限,说明策略已能稳定保持杆子平衡。
在 MountainCar 中,更合理的观察对象是到达终点的频率是否上升,以及平均回报是否逐步接近较短路径对应的数值。两个任务强调的问题不同:CartPole 看更新是否稳定,MountainCar 看探索是否足够。
像素进阶:Atari
从低维向量到像素画面,Atari 是下一个自然台阶。
Atari 的核心变化不是 TD Target,而是状态表示从向量变成了图像。Pong、Breakout 等环境的观测是游戏画面,动作是有限个控制指令,奖励来自游戏分数。LunarLander 主要考察如何稳定学习动作价值,Atari 还额外考察如何从图像中学习状态表示,因此需要 CNN、帧堆叠和更长训练。
训练设置比网络结构本身更容易影响结果。
84×84 灰度化、帧跳过、4 帧堆叠、奖励裁剪、足够大的 replay buffer,以及较晚开始学习的 learning_starts——这些处理共同决定了回放池中的样本是否具有足够的多样性和稳定性。Atari 更适合作为完整视觉 DQN 实验,而不是第一个用来判断算法是否写对的环境。
实验入口:Atari Pong
python chapter04_dqn/dqn_atari_sb3.py \
--env-id PongNoFrameskip-v4 \
--total-timesteps 10000000 \
--buffer-size 10000 \
--learning-starts 100000 \
--eval-freq 250000 \
--checkpoint-freq 500000 \
--optimize-memory-usage自定义环境:GridWorld 与小型任务
GridWorld 提供了最透明的任务设计方式。
起点、障碍物、目标位置、动作集合和奖励函数都写在环境里,结构一目了然。状态可以用坐标、one-hot 或局部图像表示,动作通常是上下左右。当状态空间较小时,可以先用表格 Q-Learning 验证最优路径;当状态表示变为更高维特征时,再用 DQN 代替 Q 表。
如果智能体学不到有效策略,原因通常可以回到环境定义本身:奖励是否太稀疏,动作设计是否合理,episode 是否过长。
这些问题在小型任务中容易被观察到,因此 GridWorld 适合用来理解 DQN 中状态、动作和奖励的基本关系。

再往上走一步,任何动作空间为 gym.spaces.Discrete(n_actions) 的任务都可以尝试 DQN。
低维向量用 MlpPolicy,图像用 CnnPolicy。但"动作离散"只是必要条件——如果奖励极其稀疏、观测严重缺少信息,或者随机探索几乎无法得到有效反馈,朴素 DQN 仍然难以收敛。
综上,DQN 适用于动作离散、奖励可观测、episode 长度有限且探索能产生有效转移的任务。
当任务表现出强部分可观测、极稀疏奖励或长时规划需求时,需要结合 Double DQN、Dueling DQN、优先回放、n-step return 或记忆网络等改进。
下面的附录沿着这条边界展开:ViZDoom 主要暴露部分可观测问题,宝可梦主要暴露稀疏奖励和长时规划问题,Minecraft 则进一步把开放世界、层级目标和长程探索推到更困难的位置。
ViZDoom 原始论文就在简化场景上用卷积网络 + Q-learning + 经验回放训练了智能体。[8] DQN 可以训练,但依赖几个约束:场景专为学习设计、动作集合受控、奖励离目标行为较近、episode 长度适中。

官方示例 examples/python/learning_pytorch.py[9] 结构完整:环境初始化、图像预处理(缩放到 30×45 灰度)、动作枚举(按钮 0/1 组合)、帧重复(frame_repeat=12)、在线/目标网络、经验回放和 Double DQN 更新。这些组件和本章前面介绍的 DQN 直接对应。
最小运行方式:
git clone https://github.com/Farama-Foundation/ViZDoom.git
cd ViZDoom
python -m venv .venv
source .venv/bin/activate
pip install vizdoom torch numpy scikit-image tqdm
python examples/python/learning_pytorch.py训练时要区分两件事:一是代码路径是否完整(每个 epoch 能产出训练/测试回报),二是策略是否真正学到行为(评估回报应逐步脱离随机水平)。如果 loss 下降但评估回报长期无趋势,说明网络可能在拟合噪声。

合理的实验起点是 simpler_basic.cfg 或 basic.cfg:场景小、反馈近、移动和射击都能较快影响奖励。观测先用灰度图缩放到 84×84 或更小;动作集合保持克制(左转、右转、前进、射击),避免枚举所有按钮组合导致输出维度膨胀。

更复杂的场景(如 HealthGathering、MyWayHome)需要更长时记忆。Lample 和 Chaplot 的研究就在 DQN 思路上加入了循环记忆和辅助游戏特征预测。[10] 这说明当任务需要记住来路、敌人位置或已探索区域时,短帧堆叠的 CNN-DQN 往往不够。
ViZDoom 不是否定 DQN,而是说明另一条边界:当观测本身不满足马尔可夫性时,只增加卷积深度不能自动补全缺失的历史信息。此时需要 DRQN 等记忆机制,或更强的探索与任务分解。
| 问题 | 表现 | 对 DQN 的影响 |
|---|---|---|
| 第一人称视角 | 当前帧只显示面前区域 | 当前观测不能表示全局状态 |
| 3D 导航 | 距离、转角和遮挡改变动作后果 | 同一按键在不同朝向下含义不同 |
| 延迟反馈 | 当前移动可能很久之后才影响生存 | TD Target 难以把远期收益传回早期动作 |
| 动作组合 | 前进、转向、射击可组合 | 动作数膨胀后,随机探索很难采到好样本 |
| 场景过拟合 | 一个 cfg 上学到的策略未必迁移 | 需在独立场景或固定测试集上检查评估 |
附录:DQN 可以通关宝可梦吗?
《宝可梦红》可以被包装成 DQN 环境:屏幕是观测,方向键和 A/B/Start 是离散动作,剧情推进可以变成奖励。[11] 但和 Pong 不同,宝可梦的目标和按键之间隔着很长的行动链,随机探索几乎不会产生足够的正样本。
| 问题 | Pong | 宝可梦红 |
|---|---|---|
| 决策链长度 | 一局几十到几百步 | 关键目标可能隔数千步 |
| 奖励密度 | 得分变化较频繁 | 剧情和徽章奖励很稀疏 |
| 状态含义 | 球和球拍位置、速度 | 地图、坐标、菜单、剧情 flag、背包、队伍状态 |
| 探索难度 | 随机动作可较快看到反馈 | 随机动作容易原地循环或卡在菜单 |
早期子任务实验
Alec Letsinger 的实验将宝可梦包装为 PyBoy 环境,用 DQN 训练智能体离开起始房子并触发早期 flag。[12] 这个结果依赖较小的状态空间(角色位置、所在区域、flag 数),说明 DQN 可以处理早期子任务,但一旦目标继续推进,就需要对话、剧情、菜单和战斗之间的长动作序列,Q 网络很难直接学到。
PWhiddy 的 PokemonRedExperiments[13] 提供了更完整的实验基础:PyBoy 环境、ROM 校验、状态文件、地图可视化和反循环检测。这类任务的工程重点不在 model.learn(...),而在环境包装:从模拟器读屏和 RAM、保存可复现起点、用地图覆盖率追踪探索、检测智能体是否卡住。
因此,宝可梦中的 DQN 目标应从短反馈任务开始:
| 训练目标 | 可用状态 | 奖励信号 | 教学意义 |
|---|---|---|---|
| 离开起始房间 | 坐标、地图编号、少量 flag | 新坐标、新地图 | 观察 DQN 是否能从局部导航中学到动作偏好 |
| 探索 Pallet Town | 屏幕图像加坐标记录 | 新位置、循环惩罚 | 观察探索覆盖是否扩大 |
| 触发早期剧情 | 坐标、地图、flag | flag 变化、关键位置奖励 | 观察稀疏事件如何进入 TD Target |
| 完整通关 | 徽章、剧情、战斗、背包和队伍状态 | 最终目标过远,单一奖励很难训练 | 说明朴素 DQN 需要分任务和更强记忆 |
宝可梦中的 DQN 形式
如果采用 DQN,网络结构本身不变:给定屏幕状态 ,输出每个按键动作的价值。输入可以是 84×84 灰度图和 4 帧堆叠;RAM 中的地图编号、坐标更适合用于构造奖励和评估指标。
| 组件 | Atari Pong | 宝可梦早期任务 |
|---|---|---|
| 观测 | 84×84 灰度,4 帧堆叠 | 同上;可记录 RAM 坐标 |
| 动作 | Atari 离散动作 | Game Boy 按键,通常 7–8 个 |
| 奖励 | 游戏分数 | 新坐标、新地图、事件变化等 shaping |
| 回放池 | 包含防守、击球、得分等短反馈 | 容易包含撞墙、原地循环、菜单状态 |
| 合理目标 | 百万级步数后观察得分趋势 | 出房间、进入新地图、扩大探索覆盖 |

最小训练入口。
cd code
pip install -r chapter04_dqn/requirements.txt准备合法获得的 PokemonRed.gb,建议从已有存档 start.state 开始(避免消耗步数在标题菜单上):
python chapter04_dqn/dqn_pokemon_red_pyboy.py \
--rom /path/to/PokemonRed.gb \
--state /path/to/start.state \
--total-timesteps 500000 \
--learning-starts 20000
tensorboard --logdir output/dqn_pokemon_red/tb如果平均回报和 unique_positions 长期不动,通常不是网络不够深,而是奖励太稀疏、动作持续帧数不合适,或智能体被菜单、墙边和重复对话困住。当短训练能产生位置变化后,再扩大步数并使用多个随机种子评估,才有意义讨论策略是否稳定。
训练目标的边界
若任务限制在早期导航,并且奖励对新坐标、新地图和循环行为给出明确反馈,DQN 可以从 replay buffer 中采样到有用转移。完整通关则要求智能体在很长时间范围内维持目标,处理剧情、背包、队伍和战斗等隐藏状态,这超出了朴素 DQN 的能力范围。
| 朴素 DQN 的问题 | 在宝可梦里的表现 | 可能的改进 |
|---|---|---|
| 随机收集经验 | 大量样本是撞墙、原地循环、反复开菜单 | 课程学习、密集奖励、优先回放 |
| 当前帧信息不完整 | 同一画面对应不同剧情 flag 或菜单状态 | 帧堆叠、RAM 特征、DRQN |
| Q 值高估 | 稀疏奖励下错误高估被反复利用 | Double DQN、Dueling DQN、n-step |
| 无效操作 | 反复开菜单、对话卡住 | action mask、anti-loop 惩罚 |
| episode 太长 | 单次失败消耗大量采样 | 存档起点、阶段目标、checkpoint |
因此,"DQN 可以通关宝可梦吗?"的精确回答是:DQN 可以在模拟器上训练早期子任务;若目标是完整通关,则需要任务拆分、奖励工程和更长时记忆。这与本节主线一致:DQN 的关键限制不是"不能看像素",而是当奖励太远、状态太隐蔽、规划链条太长时,单纯增大 Q 网络并不能自动解决问题。
附录:DQN 可以通关我的世界吗?
Minecraft 是开放世界沙盒游戏,目标不是单一动作技能,而是一串相互依赖的长期任务链:砍树 → 木镐 → 石头 → 石镐 → 铁矿 → 铁锭 → 铁镐 → 钻石。
从接口上看,Minecraft 可以被包装成强化学习环境:屏幕是观测,键盘鼠标动作可离散化,获得物品可以成为奖励。[14] [15] 但"获得钻石"之前通常要先完成一长串中间步骤,如果只把最终成功作为奖励,随机探索几乎不会产生正样本。
MineDojo 进一步把 Minecraft 组织成开放式任务平台,包含物品收集、合成、技术树和程序生成任务。[16] 一个高层目标往往不是单个 Q 函数能短期传播完的,而是一条由许多中间步骤组成的依赖链。
因此,"能不能用 DQN 训练 Minecraft 子任务"的答案是肯定的——可以把任务限制为固定小地图中收集木头、走到指定方块、在短 episode 内获得某个物品,并用少量离散动作。此时 CNN-DQN 可以作为基线。
但"朴素 DQN 能不能从零完整通关"的答案应当谨慎得多。完整通关涉及长时记忆、层级目标、背包状态、合成配方、稀疏奖励和复杂动作空间,超出了 Atari DQN 的典型假设。更常见的路线是引入模仿学习(如 VPT[17])、世界模型(如 DreamerV3[18])或语言驱动的层级策略(如 Voyager[19])。
| 目标 | DQN 是否适合 | 关键原因 |
|---|---|---|
| 固定区域内收集物品 | 可以作为基线 | 动作少、奖励近、episode 较短 |
| 简短导航或拾取任务 | 可以尝试 | 状态和目标关系较直接 |
| 获得钻石 | 需要大量任务设计 | 中间步骤多,奖励极稀疏 |
| 完整通关 | 不适合朴素 DQN | 需要长期规划、记忆、合成和开放探索 |
所以,DQN 可以训练 Minecraft 中被约束好的离散子任务;若目标是从零获得钻石甚至完整通关,就需要把任务拆成层级目标,引入演示、世界模型或更强的规划机制。这与宝可梦附录的结论相似,但 Minecraft 更进一步:它不仅奖励远,动作和状态也更加开放。
本节收获
- 从 LunarLander 到 Atari,核心公式不变,变化的是状态表示:MLP 处理向量,CNN 处理像素,帧堆叠提供运动信息。
- Pong 的成功标准不是球拍会动,而是多局确定性评估平均回报持续脱离
-21、接近0并最终超过0。 - 真正可训练的 Atari DQN 还需要完整 wrapper 链、延迟学习、足够大的回放池、周期评估和 checkpoint;否则只能证明训练管线能跑通,不能证明策略已经学到稳定行为。
- DQN 适合动作离散、奖励可观测、episode 长度有限且探索能产生有效转移的任务。
- ViZDoom 提醒我们:部分可观测会让当前观测不能完整表示状态,DQN 需要记忆机制或更强表示来补足历史信息。
- 宝可梦提醒我们:DQN 可以训练真实模拟器里的神经网络 Q 策略,但完整通关需要分任务、奖励工程和更长时记忆。
- Minecraft 提醒我们:开放世界任务不仅奖励稀疏,还包含层级目标、背包状态、合成链和更复杂的动作空间。
到这里,第 4 章完成了从表格 Q-Learning 到深度 Q 网络,再到像素游戏实验的过渡。下一章将转向另一条路线:不再先学习动作价值表,而是直接优化策略本身。策略梯度与 REINFORCE
参考文献
Mnih, V., et al. (2015). Human-level control through deep reinforcement learning. Nature, 518(7540), 529-533. https://www.nature.com/articles/nature14236 ↩︎
Farama Foundation. Arcade Learning Environment documentation. https://ale.farama.org/ ↩︎
Farama Foundation. Arcade Learning Environment environment list. https://ale.farama.org/environments/ ↩︎
CleanRL. DQN implementations and Atari DQN training scripts. https://docs.cleanrl.dev/rl-algorithms/dqn/ ↩︎
Stable-Baselines3. DQN documentation. https://stable-baselines3.readthedocs.io/en/master/modules/dqn.html ↩︎
Stable-Baselines3. Atari wrappers documentation. https://stable-baselines3.readthedocs.io/en/master/common/atari_wrappers.html ↩︎ ↩︎
RL-Baselines3-Zoo. DQN hyperparameter configuration for Atari. https://github.com/DLR-RM/rl-baselines3-zoo/blob/master/hyperparams/dqn.yml ↩︎
Kempka, M., Wydmuch, M., Runc, G., Toczek, J., & Jaśkowski, W. (2016). ViZDoom: A Doom-based AI Research Platform for Visual Reinforcement Learning. https://arxiv.org/abs/1605.02097 ↩︎
ViZDoom official examples.
examples/python/learning_pytorch.py. https://github.com/Farama-Foundation/ViZDoom/blob/master/examples/python/learning_pytorch.py ↩︎Lample, G., & Chaplot, D. S. (2016). Playing FPS Games with Deep Reinforcement Learning. https://arxiv.org/abs/1609.05521 ↩︎
PyBoy. Python API documentation for emulator control, memory and screen access. https://docs.pyboy.dk/ ↩︎
Alec Letsinger. Reinforcement Learning: Pokemon Red. https://aletsinger.com/projects/project-one/ ↩︎
PWhiddy. PokemonRedExperiments. https://github.com/PWhiddy/PokemonRedExperiments ↩︎
Johnson, M., Hofmann, K., Hutton, T., & Bignell, D. (2016). The Malmo Platform for Artificial Intelligence Experimentation. https://arxiv.org/abs/1607.05077 ↩︎
Guss, W. H., et al. (2019). MineRL: A Large-Scale Dataset of Minecraft Demonstrations. https://arxiv.org/abs/1907.13440 ↩︎
Fan, L., et al. (2022). MineDojo: Building Open-Ended Embodied Agents with Internet-Scale Knowledge. https://arxiv.org/abs/2206.08853 ↩︎
Baker, B., et al. (2022). Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos. https://arxiv.org/abs/2206.11795 ↩︎
Hafner, D., et al. (2023). Mastering Diverse Domains through World Models. https://arxiv.org/abs/2301.04104 ↩︎
Wang, G., et al. (2023). Voyager: An Open-Ended Embodied Agent with Large Language Models. https://arxiv.org/abs/2305.16291 ↩︎