1.2 奖励、熵、Value Loss 与 KL
📁 本章代码:1-ppo_cartpole.py · 2-pytorch_ppo.py · requirements.txt
观察训练过程
观察训练过程中的控制台输出, 你会发现训练脚本会持续打印各种数值。 下面这段摘自一次真实训练日志 (2026-04-21,code/chapter01_cartpole/swanlog/ 目录下的本地备份):
------------------------------------------------------------
迭代 1/20 | 回合数: 98 | 平均奖励: 20.8 | KL: 0.0047 | clip%: 6.2%
迭代 7/20 | 回合数: 10 | 平均奖励: 196.5 | KL: 0.0027 | clip%: 6.0%
迭代 13/20 | 回合数: 4 | 平均奖励: 410.0 | KL: 0.0075 | clip%: 10.6%
迭代 18/20 | 回合数: 4 | 平均奖励: 500.0 | KL: 0.0050 | clip%: 4.5%
迭代 19/20 | 回合数: 4 | 平均奖励: 500.0 | KL: 0.0041 | clip%: 4.0%
迭代 20/20 | 回合数: 4 | 平均奖励: 500.0 | KL: 0.0005 | clip%: 0.0%
------------------------------------------------------------
训练完成!20 回合评估: 500.0 +/- 0.0这些数值包含丰富的训练信息。 接下来的内容分成两个部分: 快速理解部分聚焦最关键的指标,回答"训练是否成功"; 详细解释部分则将所有指标逐个拆解,给出完整的数学定义和判读方法。 初次阅读建议先看快速理解,建立整体印象后再查阅详细解释。
快速理解
训练一次 PPO 会产生十几个指标, 但判断训练是否成功,只需关注以下四个。
回合平均奖励
平均奖励(mean reward)是判断训练效果最直接的指标。 在 CartPole 中,智能体每保持平衡 1 步获得 +1 奖励, 一局结束时的总步数即为该局的累积奖励,上限为 500 分。 训练日志里的"回合数"和指标名里的 ep, 说的都是 episode(回合 / 一局): 环境从 reset 开始,到杆子倒下、小车出界,或达到 500 步上限为止的一次完整尝试。 由于单局得分存在较大波动 (同一策略可能一局得 480 分、下一局仅得 200 分), 实际中通常取最近若干局的得分均值, 记为 ep_rew_mean(rollout episode reward mean), 以更稳定地反映智能体当前的真实水平。
训练完成后得到的奖励曲线如下图所示, 展示了 SB3 PPO(蓝色)和自研 PyTorch PPO(橙色) 在同一个 CartPole 任务上的训练过程:
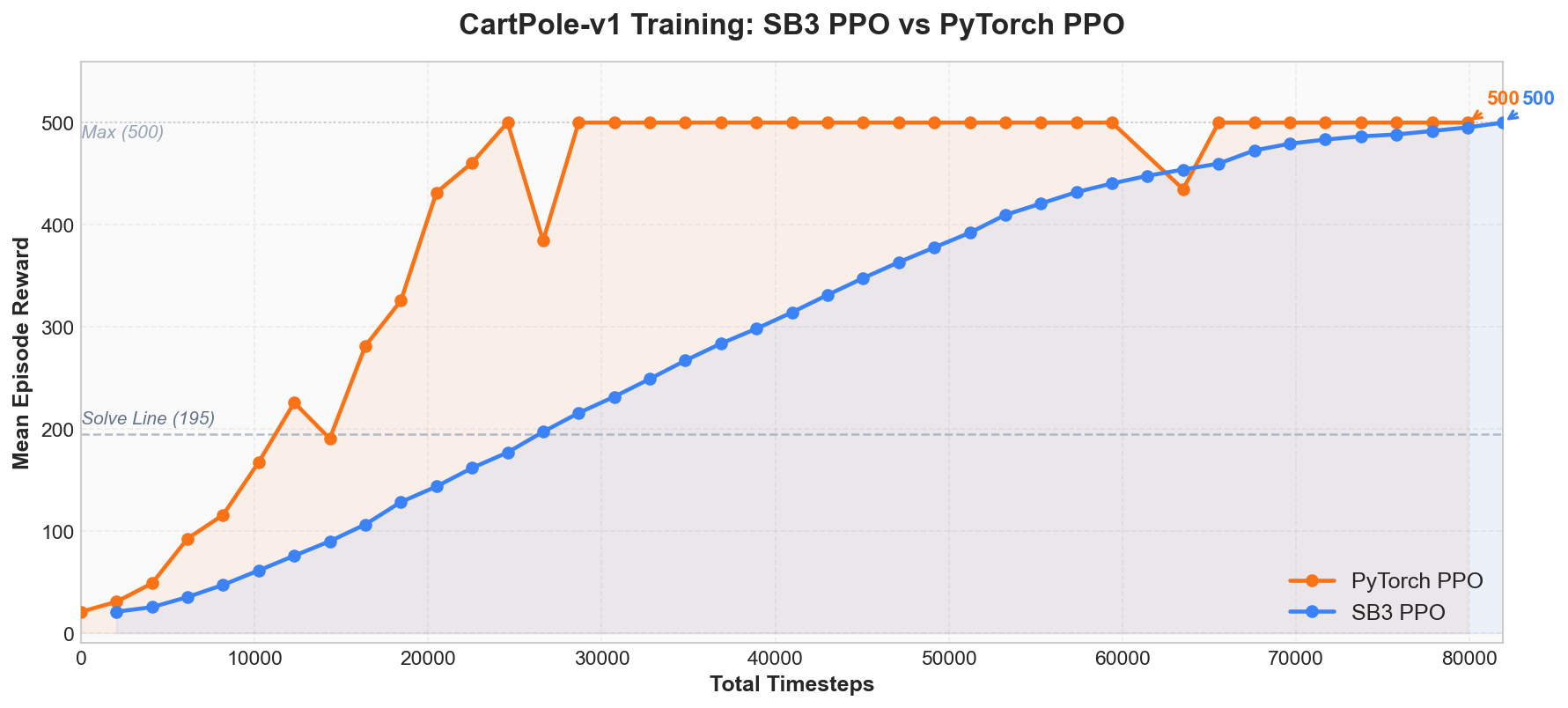
从图中可以清晰地看到三个阶段:
- 初始阶段(0 ~ 5K Total Timesteps): 两条曲线均在
20 ~ 50附近, 与随机策略(random policy)的表现相当, 表明模型尚未学到有效的平衡策略。 - 快速上升阶段(5K ~ 25K Total Timesteps): 奖励从不到 100 迅速攀升至 300 以上, 越过 195 分解题线(图中虚线), 表明策略已初步掌握平衡控制。 PyTorch PPO(橙色)因采用线性学习率衰减, 收敛速度更快。
- 收敛阶段(25K Total Timesteps 之后): 奖励进入
400 ~ 500区间, 最终稳定在满分500。 两个实现最终均达到了500.0 +/- 0.0的评估结果。
总结而言:曲线持续上升并趋于稳定,即表明训练成功。 若曲线始终持平或出现突然暴跌, 则说明训练过程存在异常。
策略熵
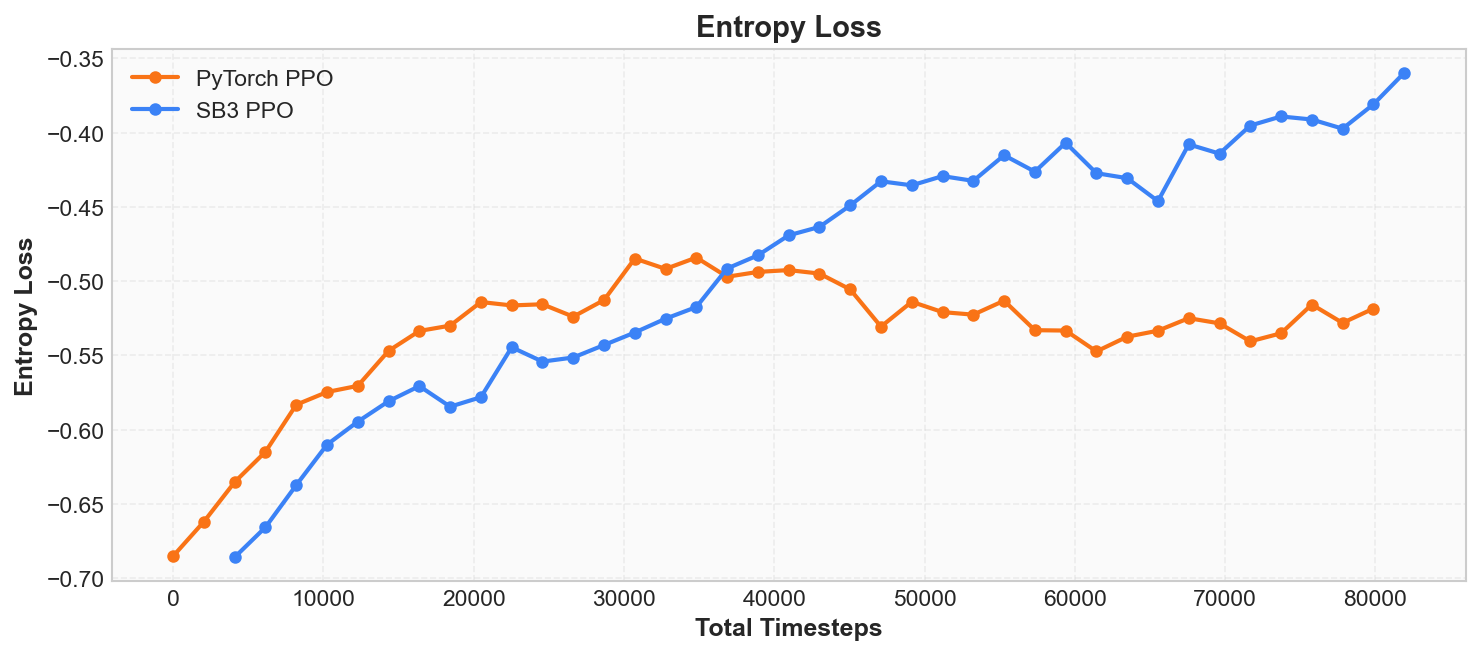
策略熵(policy entropy)度量智能体在动作选择上的不确定性。 熵来自信息论,在这里反映的是策略的随机性: 高熵表示智能体仍在广泛探索(动作分布接近均匀), 低熵表示智能体逐渐确定了最优动作(动作分布趋于集中)。
一条健康的策略熵曲线应从高到低缓慢下降, 与奖励曲线形成"剪刀交叉"—— 奖励上升的同时熵下降,这是强化学习训练的典型特征。 若训练初期熵即迅速降至 0, 则说明策略过早地收敛到某个可能并非最优的动作模式上, 这称为过早收敛(premature convergence)。
价值损失
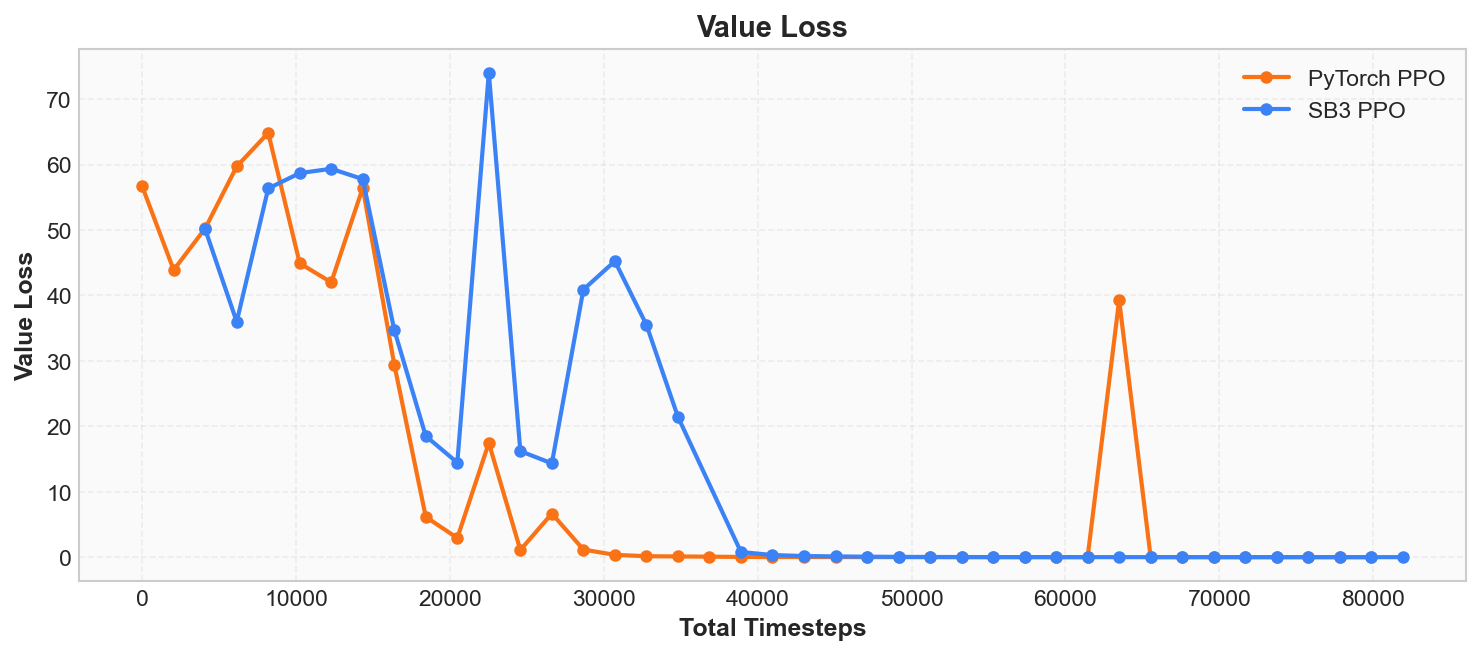
PPO 内部包含一个 Critic 组件, 其任务是预测状态价值函数—— 即"从当前状态出发,未来预期能获得的总奖励"。 价值损失(value loss)度量的就是 Critic 的预测值与实际回报之间的偏差。
训练初期,Critic 尚未学会准确评估状态价值(value_loss 较大)。 随着训练推进,Critic 的预测逐渐趋近实际回报(value_loss 逐步减小)。
需要注意的是: value_loss 减小并不等同于策略在改善。 它仅表明 Critic 的评估更为准确。 策略本身的表现应以平均奖励为判据。 若 value_loss 长期不降或反而增大, 通常意味着 Critic 未能跟上策略的变化速度。
KL 散度与裁剪比例
PPO 的核心思想是"每次只对策略做小幅修改"。 判断修改幅度是否合理,需要关注两个指标: 近似 KL 散度(approximate KL divergence)和裁剪比例(clip fraction)。
KL 散度衡量新旧策略之间的差异程度。 KL = 0 表示完全没变,KL 越大说明改得越多。 正常训练中,KL 应该始终压在 0.001 ~ 0.02 的低位; 超过 0.03 就说明策略更新幅度过大,有崩溃的风险。
裁剪比例表示当前更新中, 触发 PPO 裁剪机制的样本占总样本的比例。 可以将其理解为"安全阀触发率"。 正常情况下该值应在 5% ~ 15%, 偶尔冲高属于正常波动,但长期超过 30% 则意味着策略变化过于剧烈。
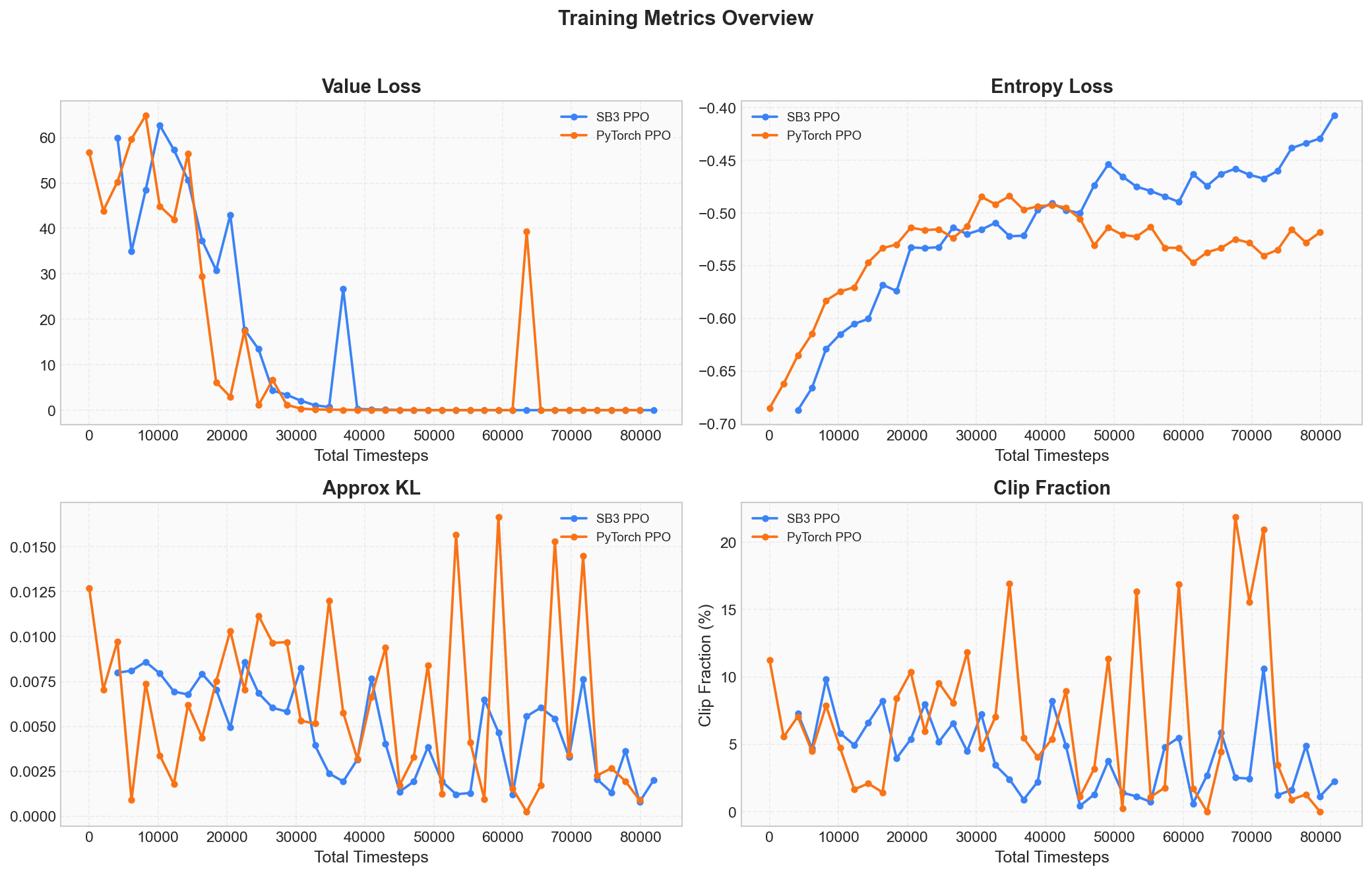
上图四个面板综合展示了训练过程的核心信号: Value Loss 在减小、Entropy 持续下降、 KL 散度始终未失控上升、Clip Fraction 也未长期处于高位—— 这正是 PPO"持续更新且幅度受控"的典型表现。
SB3 日志格式
使用 1-ppo_cartpole.py(Stable-Baselines3 版本)时, 控制台输出格式如下:
-----------------------------------------
| time/ | |
| fps | 5342 |
| iterations | 1 |
| time_elapsed | 3 |
| total_timesteps | 2048 |
| train/ | |
| entropy_loss | -0.683 |
| learning_rate | 0.0003 |
| loss | 0.0124 |
| policy_gradient_loss | -0.0187 |
| value_loss | 8.2741 |
-----------------------------------------阅读方法:首先查看 total_timesteps 确认训练进度, 再通过 value_loss 和 entropy_loss 判断训练状态。 SB3 版本在 80K 步训练设置下, 评估结果为 500.0 +/- 0.0, 演示 5 回合得分均为 500.0。
训练完成后运行以下命令,即可在浏览器中查看完整曲线:
swanlab watch swanlog训练诊断的核心问题
在观察曲线的过程中,可以尝试回答以下三个问题, 以加深对强化学习训练本质特征的理解。
问题一:为什么刚开始得分这么低?
因为智能体尚未学习任何策略。 第 1 轮平均奖励仅为 20.8, 与随机策略的表现相当。 CartPole-v1 的最大步数为 500 步(满分 500), 而随机策略平均只能维持约 20 步。
问题二:为什么曲线不是平滑上升,而是锯齿状的?
强化学习训练使用随机采样, 因此奖励曲线并非单调递增。 即便在这次总体稳定的训练中, 奖励也出现了波动: 第 9 轮为 319.0,第 10 轮回落到 276.9, 第 11 轮继续降至 238.9, 但第 13 轮又回升至 410.0。 这种局部回撤属于正常现象, 只要整体趋势向上,训练即仍在有效推进。
问题三:如果把 total_timesteps 改成 5000,会怎样?
训练将提前结束, 智能体可能尚未进入"稳定 500 分"的收敛阶段。 从本次训练数据看, 真正稳定在高分段大约发生在第 13 轮之后。 缩短训练时间后, 最常见的结果是模型停留在 100 ~ 300 分之间—— 偶尔能维持较长时间,但表现尚不稳定。
动手实验:将
total_timesteps分别修改为 5000、10000、50000, 对比三次训练后智能体的表现差异, 直观感受"训练步数"与"学习效果"之间的关系。
指标详解
上面"快速理解"部分覆盖了最关键的四个指标。 接下来的内容将把 SwanLab 记录的所有指标逐个展开, 包括数学定义、判读方法和异常信号。 本节可作为参考手册,在遇到具体指标疑问时随时查阅。
在我们的训练脚本中,SwanLab 会记录完整的训练指标, 分成三大类:
| 类别 | 指标 | 含义 |
|---|---|---|
| Rollout(策略表现) | ep_rew_mean | 回合平均奖励 |
ep_len_mean | 回合平均长度 | |
| Train(训练过程) | value_loss | Critic 预测误差 |
entropy_loss | 策略随机性 | |
policy_gradient_loss | 策略损失 | |
approx_kl | 新旧策略差异 | |
clip_fraction | 裁剪触发比例 | |
explained_variance | Critic 拟合质量 | |
learning_rate | 当前学习率 | |
loss | 总损失(SB3) | |
clip_range | 裁剪范围 | |
n_updates | 梯度更新次数 | |
| Time(进度追踪) | total_timesteps | 累计交互步数 |
iterations | PPO 迭代轮数 | |
fps | 每秒步数(SB3) | |
time_elapsed | 已用时间(SB3) |
下面是 SB3 PPO 和自研 PyTorch PPO 在同一个 CartPole 任务上的真实训练曲线对比 (均约 80K Total Timesteps、40 轮迭代):
Episode Reward(回合奖励)
回合奖励(episode reward)是一个回合中所有步骤奖励的总和。 在 CartPole 中,每步奖励固定为 +1, 因此回合奖励就等于杆子保持平衡的总步数。 SwanLab 中记录为 rollout/ep_rew_mean, 即每次 Rollout(策略与环境交互收集数据的过程) 中得到的所有回合的奖励均值:
其中 是回合结束时的步数。 在 CartPole-v1 中, 的上限为 500。
从上面的对比图中可以看到, 两个实现在约 25K~80K Total Timesteps 后都收敛到了 500 分: PyTorch PPO(橙色)在约 25K 步首次达到满分, SB3 PPO(蓝色)在约 80K 步稳定达到 500。 两者的收敛路径相似,但 PyTorch 版本因使用了线性学习率衰减而收敛更快。
这是衡量强化学习智能体表现的核心指标。 一条健康的曲线应该呈现以下特征:
- 整体趋势上升:策略在改进。 如果从头到尾都是一条平线,说明训练没有生效。
- 上升速度先快后慢: 早期从"完全随机"到"基本能平衡"的进步空间大,曲线陡峭; 后期改进越来越难,曲线趋于平缓。
- 最终趋于稳定: 策略收敛到一个较好的水平, 曲线在某个值附近小幅波动。 波动来源于采样的随机性。
如果曲线出现以下异常,说明训练出了问题:
| 异常现象 | 可能原因 | 严重程度 |
|---|---|---|
| 突然暴跌到 0 | 策略崩溃,学习率太大 | 严重 |
| 始终不动(卡在 20 左右) | 策略没有在学习,超参数不当 | 严重 |
| 剧烈震荡不收敛 | 训练不稳定,奖励信号太稀疏 | 中等 |
| 稳定在 100 左右不上去了 | 探索不够,陷入局部最优 | 中等 |
Episode Length Mean(回合平均长度)
SwanLab 中的 rollout/ep_len_mean 记录的是 每次 Rollout 中所有回合的平均步数。 在 CartPole 中, 由于每步奖励固定为 +1, 回合长度和回合奖励在数值上完全相等—— 一个回合走了 200 步,奖励就是 200。
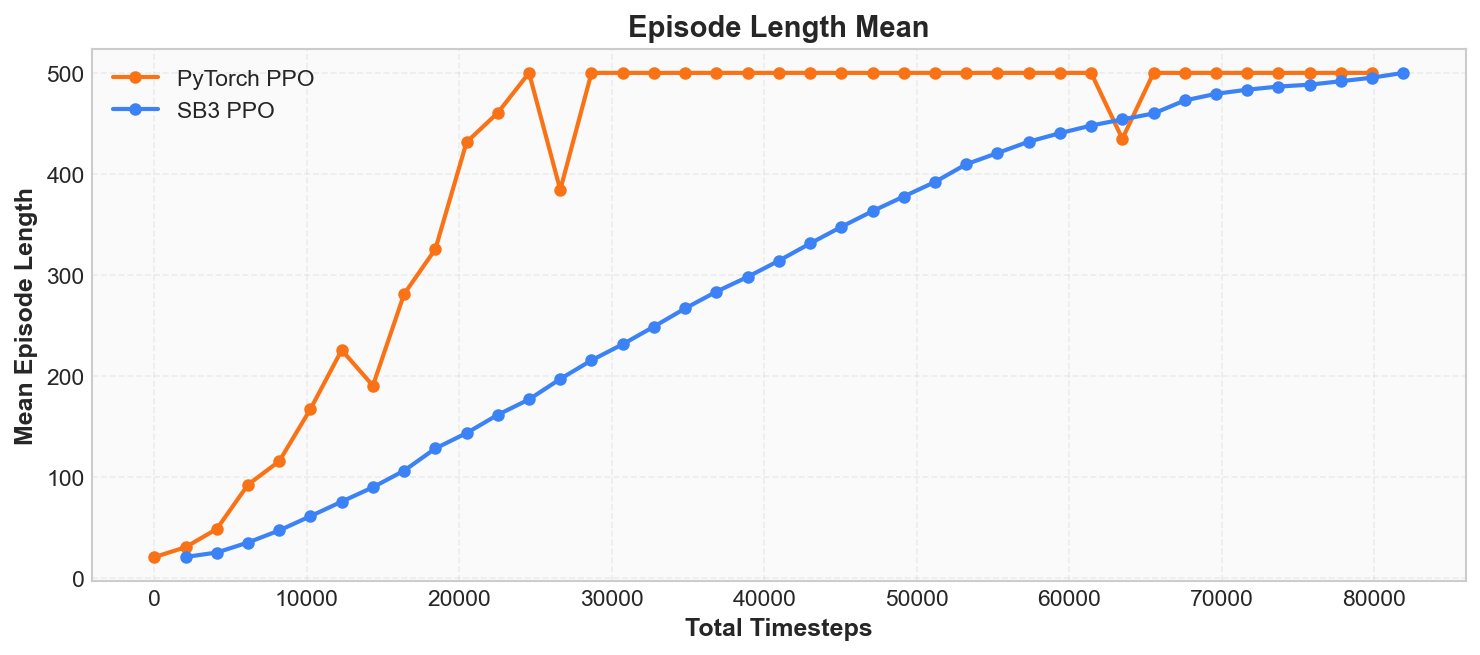
既然数值相等,为何还要单独记录该指标? 因为并非所有环境的奖励都与步数等价。 在后续章节中将遇到更复杂的环境,届时会发现:
- 非均匀奖励:有些步给 +0.1,有些步给 +10, 奖励和长度不再一一对应。
- 惩罚机制:某些步可能扣分(比如碰壁 -5), 此时高奖励可能对应短回合。
- 任务目标:有些任务要尽快结束 (最少步数达到目标), 长回合反而是坏事。
在这些场景下, 回合平均长度(episode length mean)即成为 独立于回合奖励的重要信号。 建议从现在起养成同时观察两项指标的习惯。
Entropy(策略熵)
训练日志中的 entropy_loss 对应的概念是策略熵(policy entropy)。 熵来自信息论,衡量的是分布的不确定程度。 对于离散策略,熵的定义为:
在 CartPole 中只有两个动作(左推和右推),所以:
- 均匀分布 时, 熵最大,。
- 确定性策略 时, 熵最小,。
训练过程中,熵从高到低的变化 反映了策略从"广泛探索"到"逐渐确定"的过程。 如果你在 SwanLab 中同时查看 Episode Reward 和 Entropy, 会看到前者上升、后者下降—— 两条曲线形成剪刀交叉, 这是强化学习训练的典型特征。
但熵并非越低越好。 若训练初期熵即迅速降至接近 0, 则说明策略过早地收敛到某个可能并非最优的动作模式, 这称为过早收敛(premature convergence)。 强化学习算法通常通过熵正则化(entropy regularization) 来缓解这个问题,我们将在第 7 章中详细讨论。
动手实验:运行 2-pytorch_ppo.py, 在 SwanLab 中同时查看
rollout/ep_rew_mean和train/entropy_loss, 观察两条曲线的变化。
Value Loss(价值损失)
训练日志中的 value_loss 是 Critic 网络的损失值。 Critic 的工作是预测状态价值函数(state value function), 即"从当前状态出发,未来预期能拿多少总奖励"。 价值损失(value loss)衡量的是 Critic 的预测值与实际回报之间的差距:
其中 是 Critic 对状态 的预测价值, 是从该状态出发的实际累积奖励, 是当前批次(batch)的样本集合。
训练初期,Critic 还没学会准确评估局面 (value_loss 很大)。 随着训练推进,Critic 的预测越来越准确 (value_loss 逐步减小)。
需要注意的是: value_loss 减小不等于策略在变好。 它只说明 Critic 的评估更准了。 策略本身的表现要看 Episode Reward。 如果 value_loss 长期不降或者反而增大, 通常意味着 Critic 没有跟上策略的变化。
Explained Variance(解释方差)
解释方差(explained variance)是 Critic 拟合质量的另一个角度。 它的定义是:
其中 是实际回报, 是 Critic 的预测值。 直观理解:
- EV = 1:Critic 的预测完美匹配实际回报,没有任何误差。
- EV = 0:Critic 的预测和直接猜平均值一样差,等于没学到东西。
- EV < 0:Critic 的预测比猜平均值还差。
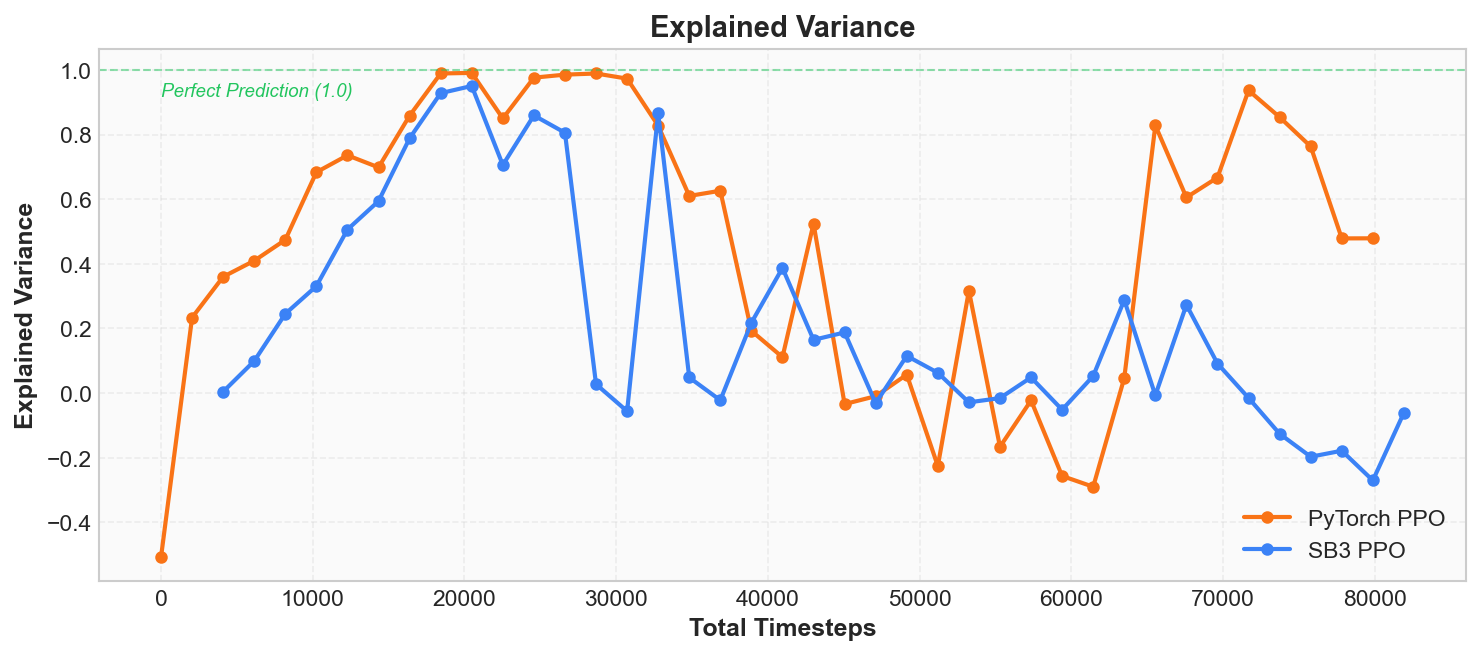
训练初期 EV 可能为负值(Critic 的预测尚不如直接取均值), 随着训练推进 EV 逐步上升, 在策略快速改进的阶段会达到 0.9 以上。 但你会注意到一个看似反常的现象: 策略收敛后(所有回合都是 500 分),EV 反而会波动甚至回落。 这是因为当所有回报都相同(variance 趋近 0)时, Critic 的微小预测误差就会被分母放大。 这并不代表 Critic 变差了——Value Loss 此时会降到接近 0,说明预测本身没有问题, 只是 EV 这一指标在低方差场景下不再稳定。
它和 Value Loss 是同一问题的两个视角: Value Loss 度量"绝对误差的大小", Explained Variance 度量"预测相对于均值基线的改善程度"。 判断 Critic 质量,建议以 Value Loss 为主、EV 为辅。
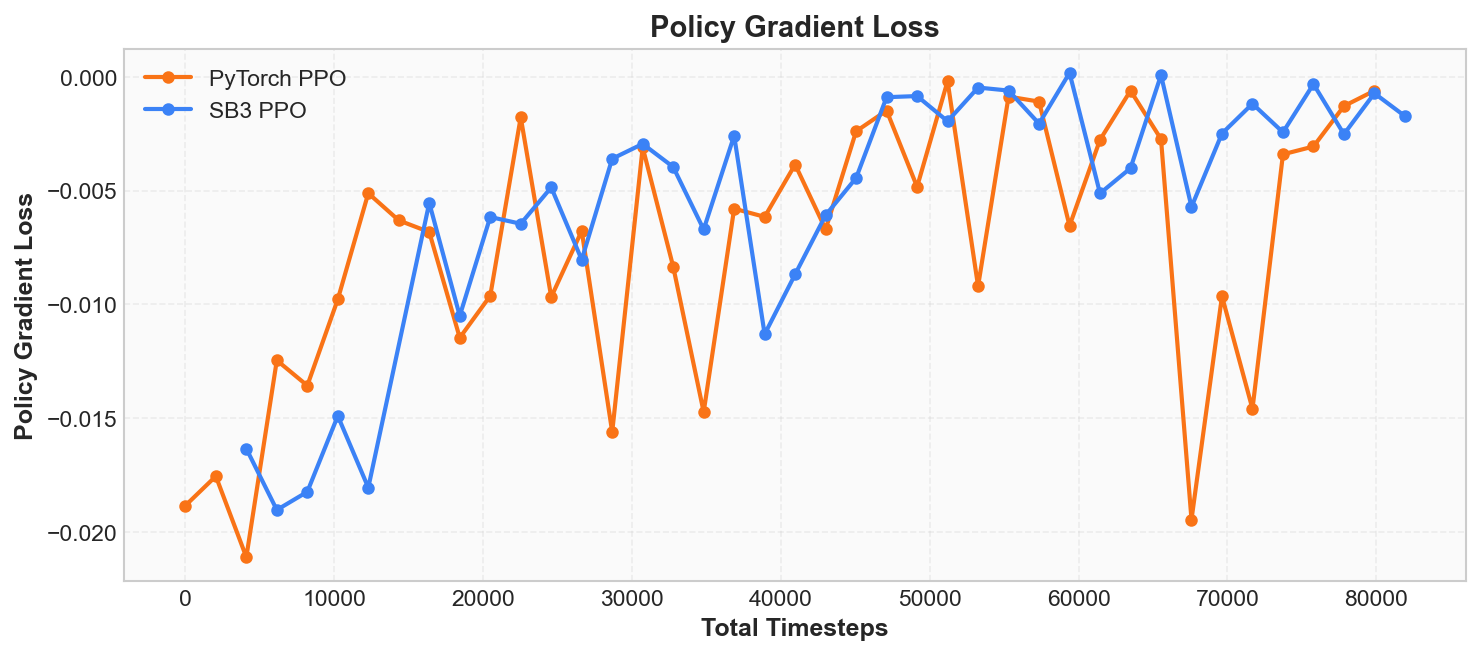
Policy Gradient Loss(策略梯度损失)
日志中的 policy_gradient_loss 是策略网络的损失值。 回顾「核心原理」一节中介绍的 PPO 裁剪目标:
这个值的大小本身不太重要, 重要的是它的符号和趋势:
- 在健康训练中, 这个值通常在一个小范围内波动(比如 -0.01 到 -0.02)。
- 如果突然变成很大的正数或负数, 可能意味着策略更新出了问题。
Total Loss(总损失)
SB3 的日志中有一个 loss 字段 (我们的自研 PPO 没有单独记录, 因为它的值可以由其他指标算出来)。 它是策略损失、价值损失和熵正则化项的加权和:
其中 (价值损失系数), (熵系数)。 这个值就是优化器实际在最小化的目标。 它本身不需要特别关注—— 如果各个分项指标都健康,总损失自然健康。 但如果你只想看一条曲线做快速判断, Total Loss 的趋势可以作为一个综合信号。
Approx KL 和 Clip Fraction
这两个指标是 PPO 独有的安全监测仪。 回顾「核心原理」一节: PPO 的核心思想是"每次只改一点点策略", 而这两个指标就是在回答—— "改了多少?有没有改过头?"
Approx KL 衡量的是更新前后两个策略之间的差异程度, 用的是 KL 散度(Kullback-Leibler Divergence)的近似值:
直观理解:KL = 0 表示新旧策略完全相同; KL 越大,说明更新后策略偏离越远。 PPO 的设计目标就是将该值控制在很小的范围内, 确保每次更新都是小幅调整而非剧烈变动。
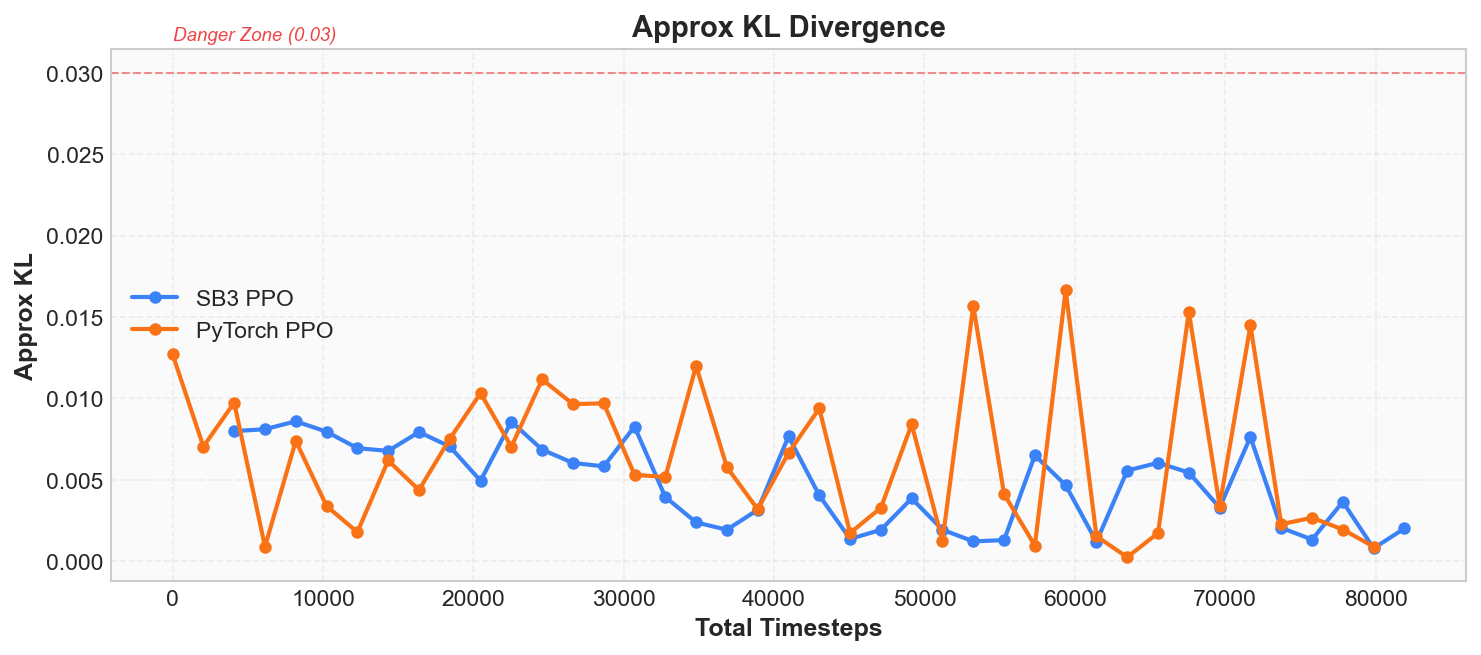
Clip Fraction 表示在这一轮更新中, 有多少比例的样本真的触发了 PPO 的裁剪机制 (即重要性采样比率 超出了 的范围):
可以将裁剪机制理解为"安全阀"—— 当策略变化过大时自动截断。 Clip Fraction 即安全阀被触发的比例。 正常情况下该值应处于较低区间,偶尔升至 15%~20% 属于正常现象, 说明安全阀确实在工作,但未对训练造成持续阻碍。
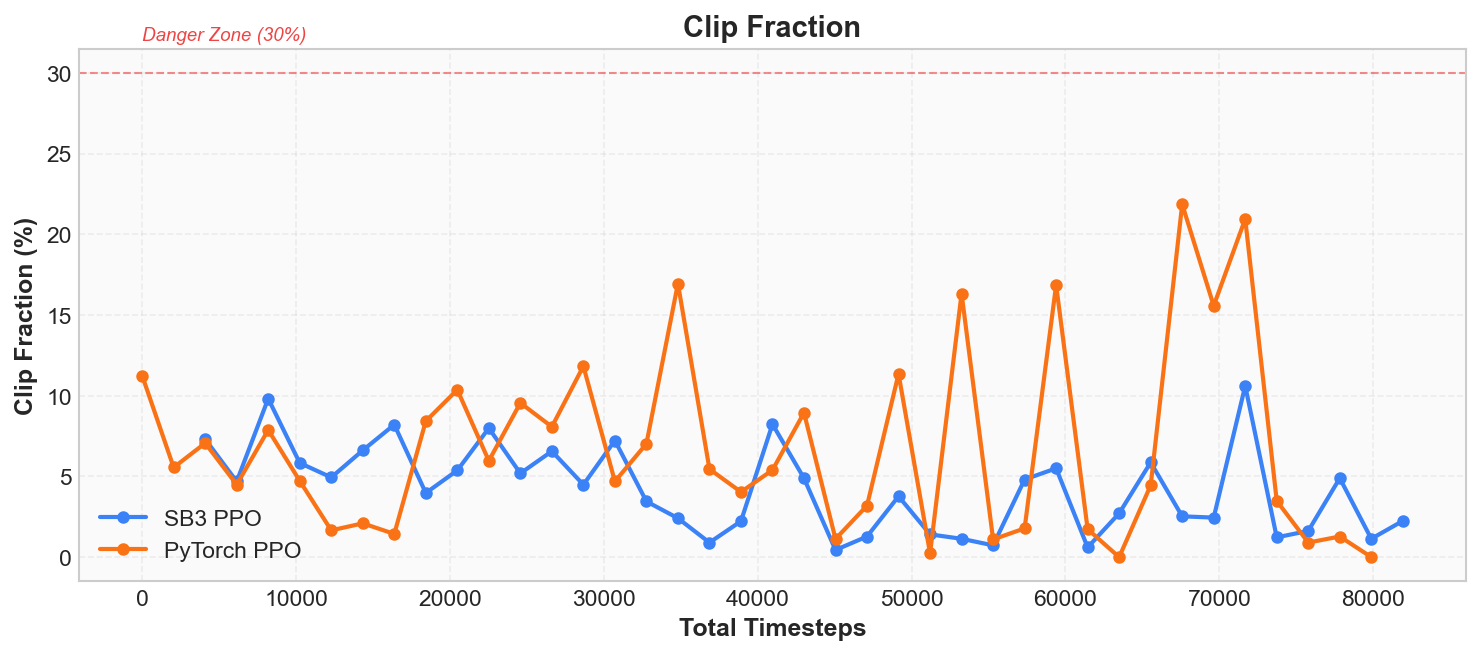
| 指标 | 健康范围 | 危险信号 | 含义 |
|---|---|---|---|
| Approx KL | 0.001 ~ 0.02 | > 0.03 | 策略单步变化过大,有崩溃风险 |
| Clip Fraction | 0% ~ 20% | 长期 > 30% | 太低说明裁剪范围过宽;太高说明策略变化过于剧烈 |
动手实验:打开 2-pytorch_ppo.py, 找到
clip_eps参数,把它从0.2改成0.5,重新运行。 你会看到 Clip Fraction 急剧下降(裁剪范围太宽,几乎不会触发), 同时 Approx KL 会升高(策略在"裸奔",没有约束)。
Learning Rate(学习率)
日志中的 learning_rate = 0.0003 是 Adam 优化器的学习率(learning rate), 控制每次参数更新的步长:
学习率过大(如 0.01), 每次更新幅度过大,策略容易崩溃; 学习率过小(如 0.000001), 每次更新幅度不足,训练收敛极慢。 SB3 的默认值 0.0003 对 CartPole 这类简单任务效果良好。
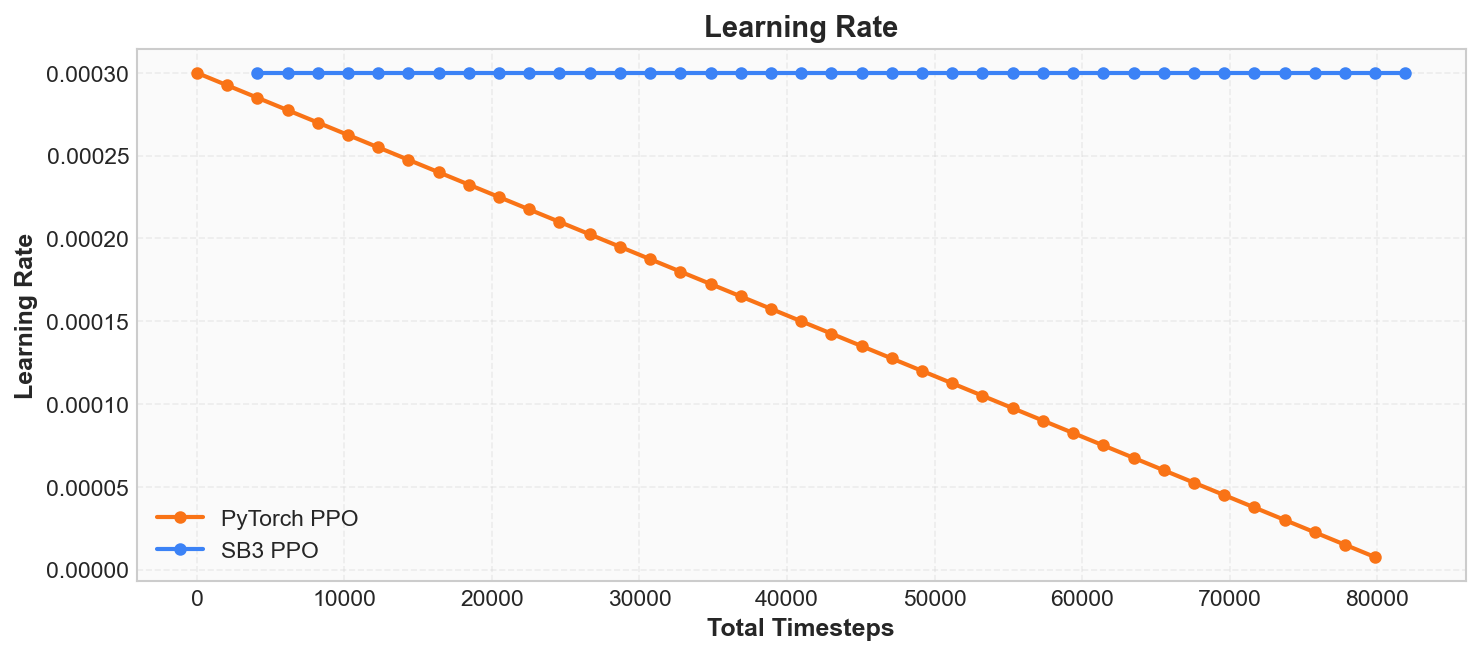
从图中可以看到两条曲线的差异: SB3 使用恒定学习率(始终 0.0003), 我们的自研 PPO 使用线性衰减(从 0.0003 线性降到 0)。 两种策略都能让 CartPole 收敛, 但线性衰减的训练后期更新更温和, 有助于策略稳定收敛。 在后面的章节中我们会看到, 学习率调度策略对训练效果有显著影响。
动手实验:打开 2-pytorch_ppo.py, 把学习率从
3e-4改成3e-2(增大 100 倍),重新运行。 你会看到训练曲线剧烈震荡甚至崩溃。
Clip Range(裁剪范围)
train/clip_range 是 PPO 裁剪区间 中的 值, 默认为 0.2。 它是一个超参数(hyperparameter),在训练过程中保持不变。 该值决定了裁剪的"阈值"—— 需与 Clip Fraction 结合分析才有意义 (见上方的动手实验)。
N Updates(梯度更新次数)
train/n_updates 记录的是从训练开始到当前, 优化器一共执行了多少次梯度更新(gradient update)。 它是一个单调递增的计数器,计算方式为:
在我们的设置中(10 epochs, 2048 steps, batch_size=64), 每轮迭代会执行 次更新。 这个指标主要用于确认训练进度是否符合预期—— 如果它突然停止增长,说明训练卡住了。
Time 指标(进度追踪)
time/ 前缀下的四个指标都是进度信息, 不是训练诊断指标:
| 指标 | 含义 | 说明 |
|---|---|---|
total_timesteps | 累计交互步数 | 每次与环境交互(执行一步动作)加 1 |
iterations | PPO 迭代轮数 | 每次"收集数据 → 更新策略"算一轮 |
fps | 每秒交互步数 | 衡量训练速度(仅 SB3 记录) |
time_elapsed | 已用时间(秒) | 从训练开始到当前的耗时(仅 SB3 记录) |
它们可用于估算剩余训练时间。 例如 fps = 5000 且剩余 10000 步时,约需 2 秒。
Eval 指标(训练后评估)
我们的自研 PPO 在训练结束后会运行 20 回合的独立评估 (不探索,纯确定性策略),记录两个指标:
| 指标 | 含义 |
|---|---|
eval/mean_reward | 20 回合的平均得分 |
eval/std_reward | 20 回合得分的标准差 |
Eval 指标和训练时的 rollout/ep_rew_mean 有本质区别—— 训练时 Agent 仍在探索(策略具有随机性), 评估时使用确定性策略(deterministic policy,即选择概率最大的动作)。 因此 eval 指标更能反映 Agent 的实际能力。 在本次 CartPole 训练中,eval 结果为 500.0 +/- 0.0, 表明智能体已完全掌握了平衡控制。
指标速查表
核心指标(训练诊断用)
| 指标 | SwanLab Key | 数学定义 | 健康表现 | 异常信号 |
|---|---|---|---|---|
| Episode Reward | rollout/ep_rew_mean | 持续上升 → 趋于稳定 | 暴跌到 0 / 始终不动 | |
| Episode Length | rollout/ep_len_mean | 回合步数的均值 | 趋势与 Reward 一致 | 与 Reward 趋势背离 |
| Entropy | train/entropy_loss | 从高到低逐步下降 | 过快降到 0 / 长期不降 | |
| Value Loss | train/value_loss | 逐步减小 | 长期不降 / 反而增大 | |
| Explained Variance | train/explained_variance | 趋向 1 | 始终 ≤ 0 | |
| Policy Gradient Loss | train/policy_gradient_loss | 小范围波动 | 突然出现极端值 | |
| Total Loss | train/loss | 各分项健康的综合信号 | 突然飙升 | |
| Approx KL | train/approx_kl | 0.001 ~ 0.02 | > 0.03 策略更新过猛 | |
| Clip Fraction | train/clip_fraction | 0% ~ 20% | > 30% 变化太剧烈 | |
| Learning Rate | train/learning_rate | SB3 恒定;PyTorch 线性衰减 | 调大 → 训练崩溃;调小 → 收敛过慢 |
辅助指标(进度追踪)
| 指标 | SwanLab Key | 含义 |
|---|---|---|
| Clip Range | train/clip_range | 裁剪参数 ,训练中不变 |
| N Updates | train/n_updates | 梯度更新累计次数 |
| Total Timesteps | time/total_timesteps | 环境交互累计步数 |
| Iterations | time/iterations | PPO 迭代轮数 |
| FPS | time/fps | 每秒交互步数(仅 SB3) |
| Time Elapsed | time/time_elapsed | 训练耗时(仅 SB3) |
| Eval Mean | eval/mean_reward | 训练后确定性策略评估得分 |
| Eval Std | eval/std_reward | 评估得分标准差 |
本章小结
在第 1 章中,我们完成了四件事:
- 运行了第一个 RL 训练: 在数秒内完成了 CartPole 的策略学习。
- 学会了观察训练过程: 掌握了 Episode Reward、Entropy、Value Loss、KL 散度等核心指标的判读方法, 能够区分健康的训练曲线与异常信号。
- 理解了 RL 的基本框架: 状态、动作、奖励、策略—— 这四个要素构成了所有强化学习问题的共同骨架。
- 解构了 SB3 的实现: 用纯 PyTorch 实现了完整的 PPO 算法—— Actor-Critic 网络、Rollout 收集、GAE 优势估计、PPO 裁剪更新—— 效果与 SB3 持平。
值得注意的是: 整个训练过程中并未向智能体提供 "杆子向右倾倒时应向右推"之类的显式规则。 智能体完全通过试错学习, 从每步 +1 的反馈信号中自主习得了平衡策略。
RL 路线全景图
上面完成的 CartPole 训练使用的算法是 PPO。 目前暂不深入其实现细节, 而是先了解它在整个强化学习算法版图中的位置。
所有强化学习算法都在回答同一个问题: "怎么让 Agent 选出累计奖励最大的动作?" 但有两条截然不同的思路:

- Value-Based(蓝色):先学习"每个动作的价值"(Q 值), 再选择价值最高的动作。代表算法是第 5 章的 DQN。
- Policy-Based(橙色):跳过价值估计, 直接学习"在给定状态下应采取什么动作"的策略。 代表算法是第 6 章的 REINFORCE。
- 两条路线在 Actor-Critic 架构中汇合—— Actor 学习策略,Critic 学习价值函数。 这正是 PPO 的基本架构。
- 在 LLM 时代, DPO 绕过了 PPO 中的奖励模型, GRPO 绕过了 Critic 网络—— 路线趋于简洁,但底层逻辑不变。
这张图会在后续每章的开头再次出现。 当前只需记住一个要点: 本章使用的 PPO,正是两条路线汇合后的产物。 第 15 章将要介绍的 DPO,则是 PPO 在 LLM 时代的简化版本。
在下一章中,我们将看到强化学习不仅限于让小车平衡杆子—— 它同样能让大语言模型学会对齐人类偏好。 核心循环仍然是状态、动作、奖励、策略这四个要素。