强化学习简史
如果我们在 2010 年代初询问一位 AI 研究员“什么是强化学习”,他大概会给你画一个智能体与环境交互的反馈循环图,并告诉你这主要用于机器人控制和下棋。但如果我们将时间的指针拨回一个世纪前,或者快进到今天的大模型时代,你会发现强化学习(Reinforcement Learning, RL)经历了一场波澜壮阔的演变——它从心理学家的动物实验出发,一步步成长为驱动当今最先进 AI 系统的核心引擎。
在开始我们的代码实践之前,不妨先花几分钟,快速回顾一下这段跨越百年的简史。了解这些里程碑,能帮助你更好地理解为什么现代 RL 算法会设计成今天的样子。
1. 启蒙与奠基:从心理学到数学框架(1890s - 1950s)
强化学习的思想最早并非诞生于计算机科学,而是来自心理学和神经科学。 1898 年,心理学家爱德华·桑代克(Edward Thorndike)通过著名的"猫的迷笼实验"提出了效果律(Law of Effect):如果一个行为带来了好的结果,这个行为就会被强化;反之则被弱化。这正是"试错学习(Trial-and-Error)"的本源。
半个多世纪后,随着控制论的兴起,这种生物本能开始被严谨地数学化。1957 年,理查德·贝尔曼(Richard Bellman)提出了马尔可夫决策过程(MDP)与贝尔曼方程(Bellman Equation) [1]。他用一个五元组 将现实中的序列决策问题抽象为一个精确的数学对象——状态集 、动作集 、转移概率 、奖励函数 和折扣因子 。在这个框架下,智能体的目标是找到一个策略 ,使得长期累积折扣奖励的期望最大化:
为了衡量"一个策略到底有多好",贝尔曼引入了价值函数的概念—— 表示从状态 出发、始终遵循策略 所能获得的期望累积奖励。而所有策略中最优的那个,就对应着最优价值函数 。贝尔曼证明,它满足一个优美的递推关系——贝尔曼最优方程:
这个方程的含义极为深刻:当前状态的最优价值,等于"立即奖励"加上"未来所有可能状态的最优价值的折扣期望"。它将一个看似无穷无尽的序列决策问题,转化为一个可递推求解的方程——这就是动态规划的思想根源。这标志着强化学习正式拥有了坚实的理论根基。
2. 理论成型:时序差分与无模型学习(1980s - 1990s)
贝尔曼的动态规划虽然在数学上无懈可击,但在实际应用中存在两个致命的限制。第一,它要求完全已知环境的模型——即转移概率 和奖励函数 必须事先给出。但在现实中,机器人不知道推开一扇门后走廊有多宽,AI 也不知道对手下一步会走哪步棋。第二,它面临严重的"维度灾难"——贝尔曼方程需要对所有状态逐一求解,而状态空间的规模随问题复杂度呈指数增长。以围棋为例,棋盘状态数约为 ,即使全宇宙的原子都用来存储状态表也远远不够。为了让智能体在未知环境中、不依赖完整状态表也能学习,先驱者们开始寻找新的出路。
- 1988 年,被誉为"强化学习之父"的理查德·萨顿(Richard Sutton)系统性地提出了时序差分学习(Temporal Difference, TD) [2]。它巧妙地结合了蒙特卡洛采样和动态规划的自举特性,让智能体可以在没有完整环境模型的情况下边走边学。TD 的核心更新规则极其简洁:
其中 被称为 TD 误差。直觉上,它衡量的是"新估计"与"旧估计"之间的差距——如果走到下一步后发现情况比预期好(),就上调当前状态的价值;反之则下调。这种"边走边学"的机制,是现代 RL 最核心的思想之一。
- 1989 年,克里斯·沃特金斯(Chris Watkins)在他的博士论文中提出了著名的 Q-Learning 算法 [3]。这是一种无模型(Model-Free)的离策略算法,至今仍是 RL 入门的第一课。其更新规则为:
Q-Learning 的精妙之处在于:它直接学习动作价值函数 ——在状态 下执行动作 到底"值多少分"。有了这个打分表,智能体只需要在每个状态贪心地选得分最高的动作 就能做出最优决策。
- 1992 年,IBM 的杰拉尔德·特萨罗(Gerald Tesauro)开发了 TD-Gammon [4]。通过将 TD 算法与一个浅层神经网络结合,它在西洋双陆棋中达到了人类世界冠军的水平。这是神经网络与 RL 结合的早期成功典范。

1998 年,Sutton 和 Barto 出版了影响深远的经典教材《强化学习:一个介绍》(Reinforcement Learning: An Introduction) [5],现代强化学习的学科框架正式成型。
3. 深度革命:当 RL 遇见深度学习(2013 - 2019)
进入 21 世纪后,尽管 RL 理论日益完善,但传统的表格型方法和线性函数近似根本无法处理真实世界中高维、复杂的输入(如图像)。直到深度学习的爆发,RL 才真正迎来了它的"高光时刻"。
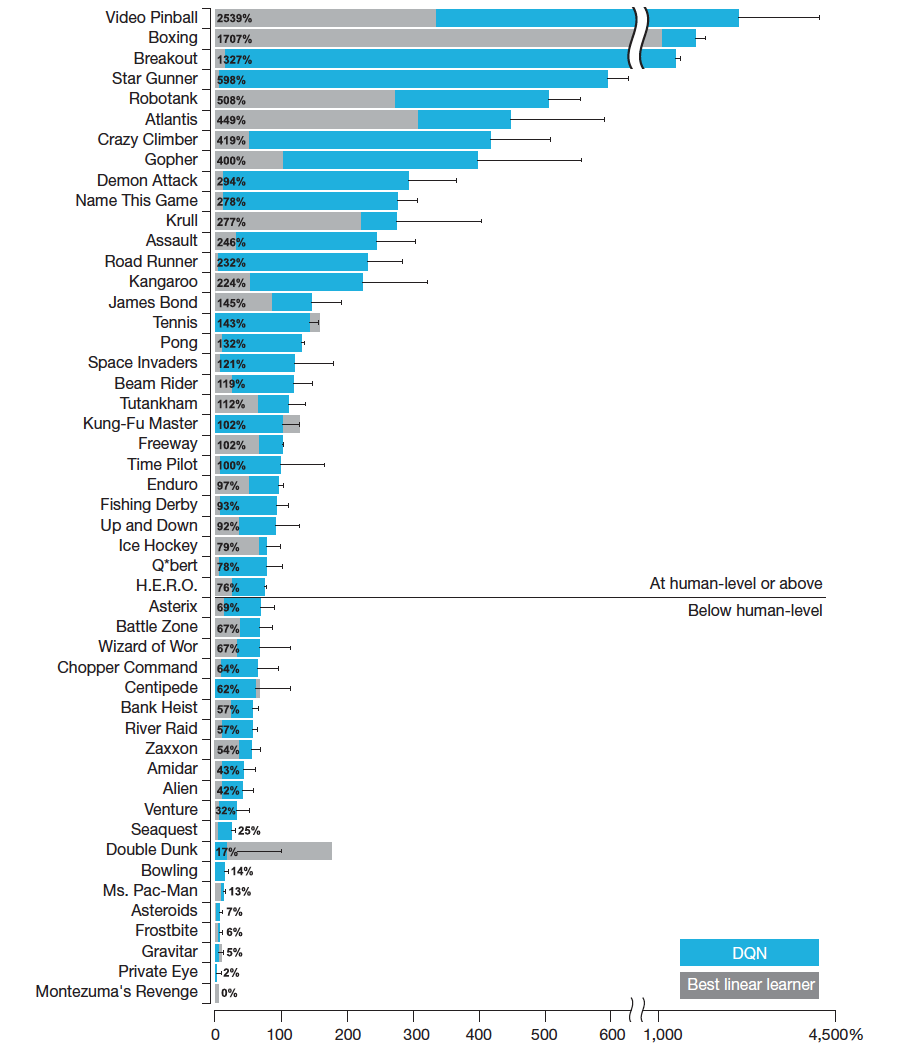
- 2013 年,DeepMind 提出了深度 Q 网络(DQN) [6],首次将深度神经网络与 RL 完美结合,让 AI 仅凭屏幕像素就能学会在多款 Atari 街机游戏中超越人类。深度强化学习(Deep RL)的时代正式拉开帷幕。DQN 的核心思路是用一个参数为 的神经网络 来近似 Q 值函数,其损失函数为:
其中 是目标网络的参数(定期从 复制过来,而非每步更新), 是经验回放缓冲区(Experience Replay Buffer)。这两个看似简单的工程技巧——目标网络和经验回放——彻底解决了深度网络与 Q-Learning 结合时的训练不稳定问题,是 DQN 成功的关键。
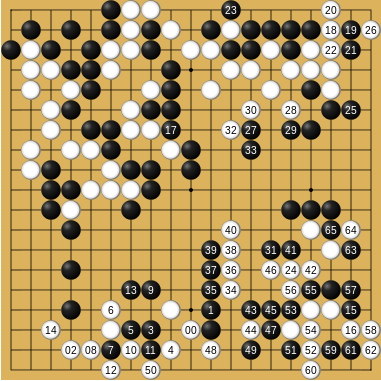
- 2016 年,注定载入史册的一年。DeepMind 的 AlphaGo [7] 结合了深度强化学习与蒙特卡洛树搜索,以 4:1 击败了围棋世界冠军李世石。这一事件不仅震惊了世界,也让 RL 第一次以极其震撼的方式进入了公众视野。
- 2017 年,OpenAI 提出了 PPO(近端策略优化,Proximal Policy Optimization) 算法 [8]。相比于早期策略梯度方法的高方差和脆弱性,PPO 在训练稳定性和采样效率之间找到了绝佳的平衡。其核心思想是通过裁剪来限制每次策略更新的幅度,避免"步子迈太大"导致训练崩溃:
其中 是新旧策略的概率比, 是优势函数的估计, 通常取 0.1~0.2。裁剪机制确保每次更新后,策略不会偏离旧策略太远——这就像给学习率加了一道"安全护栏"。由于其易于调参和出色的鲁棒性,PPO 迅速成为了工业界的默认标准算法。随后 OpenAI 使用基于 PPO 的大规模分布式系统 OpenAI Five 击败了 DOTA 2 的世界冠军团队。
4. 大模型时代:对齐与推理的新范式(2020s 至今)
就在人们以为 RL 的应用边界主要局限于游戏和机器人控制时,大语言模型(LLM)的崛起为 RL 赋予了全新的使命——对齐(Alignment)与推理(Reasoning)。
- 2022 年,OpenAI 发布了 ChatGPT。其背后的核心功臣正是 RLHF(基于人类反馈的强化学习) [9]。通过训练一个奖励模型来模拟人类偏好,再用 PPO 算法优化语言模型,RL 成功地让 LLM 从"能接话的统计机器"变成了"懂分寸的智能助手"。RLHF 的训练分两步:首先用人类偏好数据训练一个奖励模型 ,然后以它为奖励信号,用 PPO 优化语言模型策略 :
其中 KL 散度惩罚项 确保模型不会为了追求高分而偏离原始行为太远——这是 RLHF 中防止"奖励投机"(Reward Hacking)的关键约束。

- 2023 年,斯坦福大学等提出了 DPO(直接偏好优化) [10]。研究者们发现,可以绕过繁琐的奖励模型训练,直接用一个简单的分类损失函数在人类偏好数据上微调语言模型。DPO 的损失函数直接从 RLHF 的目标中推导而来:
其中 (winner)和 (loser)分别是人类标注的"好回答"和"差回答", 是 sigmoid 函数。这个公式优雅地将 RLHF 中隐含的奖励模型直接消去了——模型只需要学会"好回答的概率相对提升,差回答的概率相对下降"。DPO 极大地降低了 RLHF 的工程门槛,迅速席卷了开源社区。
- 2024 - 2025 年,随着 OpenAI o1 和 DeepSeek-R1 [11] 等推理模型的惊艳亮相,强化学习再次进化。特别是 DeepSeek-R1-Zero 证明了在有明确客观规则(如数学对错、代码编译)的场景下,完全可以抛弃传统的 SFT(监督微调)冷启动,直接让 Base 模型进行纯粹的强化学习(Pure RL)。 这一过程不仅打破了"必须先 SFT 才能做 RL"的刻板印象,更让模型自主涌现出了长思维链(CoT)和顿悟(a-ha moment)能力。DeepSeek 采用的 GRPO(群体相对策略优化) 算法,去除了传统 PPO 中极其消耗显存的 Critic 网络,直接通过组内相对奖励来优化策略。GRPO 的核心思路是:对同一个 prompt 采样一组回答 ,用组内均值和标准差对奖励做归一化后作为优势估计:
然后直接用裁剪目标优化策略:
这种轻量级架构不需要额外的 Critic 网络,直接用同一组回答之间的相对排名来驱动学习,使得在大规模集群上进行纯 RL 强化推理能力成为现实。
小结
从桑代克的迷笼,到贝尔曼的方程;从雅达利游戏机里的 DQN,到今天云端集群里飞速迭代的 DPO 和 GRPO。强化学习的历史,就是一部智能体**"从环境中学习、从反馈中进化、从单机走向超级模型"**的史诗。
今天,强化学习已经不再是象牙塔里的理论玩具,它是通向通用人工智能(AGI)的必经之路。在接下来的章节中,我们将沿着这段历史的脉络,从第一行代码开始,亲手将这些伟大的算法实现出来。
参考文献
Bellman, R. (1957). A Markovian Decision Process. Journal of Mathematics and Mechanics, 6(5), 679-684. DOI ↩︎
Sutton, R. S. (1988). Learning to predict by the methods of temporal differences. Machine Learning, 3(1), 9-44. PDF ↩︎
Watkins, C. J. C. H. (1989). Learning from Delayed Rewards. PhD Thesis, King's College, Cambridge. PDF ↩︎
Tesauro, G. (1995). Temporal difference learning and TD-Gammon. Communications of the ACM, 38(3), 58-68. DOI ↩︎
Sutton, R. S., & Barto, A. G. (2018). Reinforcement Learning: An Introduction (2nd ed.). MIT Press. 在线阅读 ↩︎
Mnih, V., et al. (2013). Playing Atari with Deep Reinforcement Learning. arXiv preprint. arXiv:1312.5602 ↩︎
Silver, D., et al. (2016). Mastering the game of Go with deep neural networks and tree search. Nature, 529(7587), 484-489. DOI ↩︎
Schulman, J., et al. (2017). Proximal Policy Optimization Algorithms. arXiv preprint. arXiv:1707.06347 ↩︎
Ouyang, L., et al. (2022). Training language models to follow instructions with human feedback. arXiv preprint. arXiv:2203.02155 ↩︎
Rafailov, R., et al. (2023). Direct Preference Optimization: Your Language Model is Secretly a Reward Model. arXiv preprint. arXiv:2305.18290 ↩︎
DeepSeek-AI, et al. (2025). DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv preprint. arXiv:2501.12948 ↩︎