12.3 自博弈、自进化与学习路线
AlphaGo 通过自我博弈从零开始学会了下围棋——不需要人类棋谱,不需要专家演示,只需要一个棋盘和自我对弈的循环。这个"从零到超人"的故事是 RL 最具传奇色彩的篇章之一。2025-2026 年,同样的思路正在被迁移到大语言模型:模型能否通过和自己的博弈来持续进化,最终突破人类数据的上限?
这一节我们来拆解自博弈和自进化的核心思路,从底层的数学原理到具体的代码循环,讨论它面临的挑战,最后为整本书画上一个句号——提供一条从本书出发的持续学习路线。
自博弈 RL:让模型互为对手
自博弈(Self-Play)的核心思想极其优雅:不依赖外部数据,让模型自己生成训练数据,并在互相对抗中寻找纳什均衡。

具体的训练流程通常是:
- 模型生成多个候选回答(或在游戏中执行动作)。
- 另一个模型实例(或同一个模型)评估这些回答的质量,或者在游戏中与它对抗分出胜负。
- 用评估结果或胜负结果作为 reward 信号,通过 PPO 等算法更新模型策略。
- 将更新后的模型加入到"历史对手池"中,重复循环。
1. 从数学上看:寻找纳什均衡 (Nash Equilibrium)
在普通的单智能体 RL 中,我们的目标是最大化累积期望回报 。但在自博弈中,环境是包含其他智能体的,这就变成了多智能体强化学习(MARL) 中的博弈论问题。
- 零和博弈(Zero-Sum Game):像围棋或 Dota 2 的 1v1,你赢的概率加上对手赢的概率等于 1。
- 纳什均衡:自博弈的终极目标不是"获得最高分"(因为对手也在变强,你的胜率可能永远在 50% 徘徊),而是收敛到一个纳什均衡点。在这个状态下,任何单方面改变策略的智能体都会导致自己的收益下降。
也就是说,如果模型 学到了纳什均衡策略,无论对手 用什么阴招,它都能保证不亏(立于不败之地)。
2. 从代码上看:虚拟对弈循环 (Fictitious Play)
如果你只是让"最新版本的模型 A"和"最新版本的模型 A"一直对打,很容易陷入策略崩溃(Policy Collapse):A 发明了招式 X 赢了,明天 A 发明了招式 Y 克制 X,后天 A 又发明了招式 Z 克制 Y,结果它把怎么对付 X 给忘了!
因此,在工业级代码中,我们通常使用虚拟对弈(Fictitious Play) 或维护一个历史模型池(Model Pool),每次随机抽一个过去的自己作为对手:
def self_play_training_loop(env, current_model, model_pool, total_iterations):
"""一个典型的工业级 Self-Play 训练循环"""
for i in range(total_iterations):
# 1. 以 80% 的概率和最新的自己打,20% 的概率和历史版本打
if np.random.rand() < 0.8:
opponent = current_model
else:
opponent = random.choice(model_pool)
# 2. 在环境中收集自我对弈的数据 (Trajectories)
trajectories = collect_self_play_data(env, current_model, opponent)
# 3. 使用 PPO 算法更新当前模型
current_model.update_with_ppo(trajectories)
# 4. 定期将当前模型快照保存到历史池中,防止"灾难性遗忘"
if i % save_interval == 0:
model_pool.append(current_model.copy())
# 5. 评估 ELO 积分
evaluate_elo_rating(current_model, model_pool)LLM 时代的自进化:Generator-Judge 与辩论训练
1. Generator-Judge 对抗训练与自我奖励 (Self-Rewarding LM)
这是自博弈在大模型领域最核心的形态。传统的 RLHF 需要一个外部训练的 Reward Model(通常性能上限比主模型差),这就限制了主模型的提升空间(因为裁判不够聪明)。
2024 年,Meta 与 NYU 联合提出了 Self-Rewarding Language Models(自我奖励语言模型)。其核心思想是:让同一个模型同时扮演 Generator(生成回答)和 Judge(LLM-as-a-Judge,评估回答质量)。
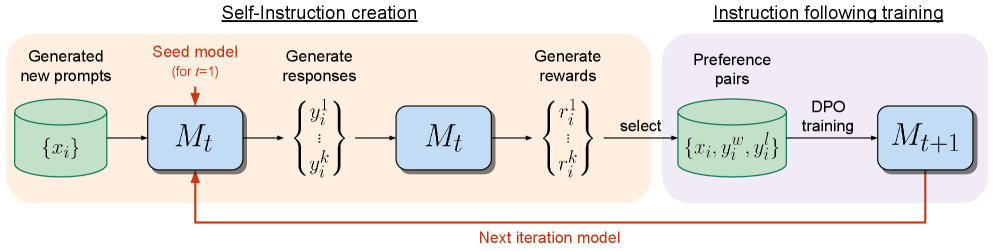
工作流:
- Self-Instruction:模型 M1 根据一批提示词生成候选回答。
- Self-Reward:同一个模型 M1 根据提示词"像一个严格的裁判一样评估以上回答,并给出 0-5 分",为自己生成的回答打分。
- Iterative DPO:取高分回答和低分回答构成偏好对 ,使用 DPO 算法训练模型,得到更强的模型 M2。
令人惊奇的是,随着模型生成能力的提升,它的"裁判能力(Reward 准确度)"也在同步提升!这就形成了左脚踩右脚上天的正向螺旋飞轮,摆脱了外部人类偏好数据的限制。
2. 辩论式训练 (Debate Training)
辩论式训练是 LLM 自博弈的一个前沿变体。两个大模型对同一个问题给出不同的回答,然后由一个裁判模型(或人类)判断哪个回答更好。关键在于:两个模型可以看到对方的回答并进行反驳。
这个过程迫使模型学会严谨推理——如果你的推理有漏洞,对手会抓住它并扣分;如果对手的推理有漏洞,你需要指出它来得分。这种"辩论-裁判"的机制让模型在对抗中学会了深度的长逻辑链推理。
def debate_training(question, model_a, model_b, judge, rounds=3):
"""辩论式 RL 训练:两个模型辩论,裁判评判,用策略梯度更新"""
# 收集完整 rollout 的 log_prob(用于策略梯度计算)
log_probs_a, log_probs_b = [], []
answer_a = model_a.generate(question)
answer_b = model_b.generate(question)
for round_idx in range(rounds):
# A 看到B的回答,反驳(同时记录 log_prob)
rebuttal_a, lp_a = model_a.generate_with_logprob(
f"问题: {question}\n你的回答: {answer_a}\n"
f"对手回答: {answer_b}\n请反驳对手。"
)
# B 看到A的反驳,回应
rebuttal_b, lp_b = model_b.generate_with_logprob(
f"问题: {question}\n你的回答: {answer_b}\n"
f"对手反驳: {rebuttal_a}\n请回应。"
)
log_probs_a.append(lp_a)
log_probs_b.append(lp_b)
answer_a, answer_b = rebuttal_a, rebuttal_b
# 裁判评判 → 转化为 RL reward(零和博弈:A 的收益 = -B 的收益)
score_a, score_b = judge.evaluate(question, answer_a, answer_b)
reward_a = score_a - score_b
reward_b = -reward_a
# REINFORCE 策略梯度更新:胜者策略被强化,败者被弱化
# loss = -log_prob * reward(正 reward → 增大该动作概率)
for lp in log_probs_a:
loss_a = -lp * reward_a
for lp in log_probs_b:
loss_b = -lp * reward_b
return reward_a # 返回 reward 供上层 self-play 循环记录Online Learning:永不停止的进化飞轮
传统的 RLHF(如 PPO)通常是"离线"的:收集一批人类偏好数据 训练 Reward Model 冻结 RM,用它指导策略优化 部署。整个过程像一个瀑布,一次做完,无法跳出人类标注的数据分布。
自进化系统的核心是 Online Learning(在线强化学习),它把这个过程变成了一个永不停止的飞轮:
核心优势:突破人类上限 在离线 RLHF 中,模型只能在"人类已经给出的上限"内模仿。而在 Online Learning 的 Self-Play 中,模型通过自我探索,可能会发现人类从未想到的解题策略。例如在 DeepSeek-R1-Zero 中,模型完全依靠强化学习,在没有任何 SFT 冷启动的情况下,通过与规则环境的在线博弈,自己"顿悟"出了长思维链(CoT)、自我反思、反复验证等高级推理能力。
自进化系统:三个 RL 闭环
综合自博弈框架和 Online Learning,自进化系统实际上由三个互相耦合的 RL 闭环组成——每个闭环都可以用前面章节学过的 RL 概念来理解。
闭环一:对手多样性——防止策略坍缩
自博弈最大的陷阱不是"学不好",而是策略坍缩(Policy Collapse)。如果模型只和最新版本的自己对打,可能陷入循环:发明招式 A → 发明克制 A 的招式 B → 忘记怎么对付 A。这在 RL 理论中对应策略在纳什均衡附近震荡而不收敛。
解决方案是种群训练(Population-Based Training):维护一个包含 个历史策略的对手池 ,每次随机抽取对手。等价于将对手的策略扩展为混合分布:
其中 是选择第 个历史策略的概率。现代框架如 PSRO(Policy Space Response Oracles) 进一步引入"基于遗憾的策略选择"——优先选择当前策略最难以应对的历史对手,最大化每轮训练的信息增益。AlphaZero 和 OpenAI Five 都使用类似机制:DeepSeek-R1 的 RL 训练中,维护多样化的历史检查点同样是稳定训练的关键。
闭环二:自适应课程——从均匀采样到难度匹配
标准 GRPO/DAPO 训练中每个 prompt 被均匀随机采样,但自进化系统可以自动识别薄弱区域——这在 RL 中对应课程学习(Curriculum Learning)。维护一个 prompt 难度分布,模型在每个难度上的通过率 反映掌握程度。目标是让模型在"学习区"训练:
通过率低的题目被更多采样。更高级的方案让 Proposer 模型通过 RL 学习生成"恰好超过 Solver 当前能力"的难题——Proposer 本身也用 RL 训练。这与第 9 章 GRPO 有直接联系:GRPO 的组内 advantage 自动提供难度信号(全组都答对的 prompt 太简单,全组都答错的太难),可用来动态调整 prompt 分布。
闭环三:奖励信号的自进化——从外部 RM 到自验证
自进化的最高形态是奖励信号本身也通过 RL 进化,对应三个阶段:
阶段一:外部 RM(RLHF,第 8 章)。奖励来自人类偏好训练的 Reward Model,上限受 RM 质量限制。
阶段二:规则验证(RLVR,第 9 章)。奖励来自可验证信号(答案对错、代码能否运行),消除 RM 但限于有标准答案的领域。
阶段三:自验证与 LLM-as-Judge。模型自己评估生成质量——即本节讨论的 Self-Rewarding LM。随着生成能力提升,判断能力也同步提升,形成正向飞轮。STaR(Self-Taught Reasoner) 是这一闭环的典型实现:模型自己写出推理过程,如果最终答案正确(正 reward),就把这段推理当作正样本;如果错误(负 reward),给出正确答案让模型反向推导——整个过程本身就是一个 RL 循环。
自验证的核心 RL 挑战是评估偏差累积:Generator 的输出有系统性偏差时,Judge(来自同一模型)也可能偏好这种风格——即本节前面讨论的"AI 回音室"。缓解方案是引入外部锚定信号(测试用例、证明验证器)定期校准自评估偏差。三个阶段对应奖励函数从外部固定信号 → 环境规则信号 → 策略自生成信号的演进——每一步减少外部依赖,但也引入新的稳定性挑战。
自进化的挑战
自进化系统听起来很美好,但目前仍面临几个根本性挑战:
| 挑战 | 描述 | 可能的缓解方案 |
|---|---|---|
| 自循环退化 | 模型的自我评估有偏差,错误被不断放大 | 引入外部验证信号(如测试用例) |
| 多样性丧失 | 自博弈导致策略坍缩到狭窄的局部最优 | 多样性奖励、种群训练 |
| 安全性风险 | 模型自主探索可能发现有害的行为模式 | 安全约束 RL(如 12.2 节讨论的) |
| 评估瓶颈 | "模型是否真的在进步"越来越难评估 | 多维度评估、对抗性测试 |
自循环退化是最令人担忧的。如果 Generator 和 Judge 都来自同一个模型,它们的偏差可能互相强化——Generator 生成某种风格的回答,Judge 因为"熟悉这种风格"而给高分,Generator 受到鼓励继续生成同种风格的回答。这就像一个"AI 回音室"——错误不是被纠正,而是被放大。
多样性丧失是另一个常见问题。自博弈训练中,两个模型可能很快收敛到同一个策略——因为"模仿胜者"是最快提升的方式。但如果所有模型都用同一个策略,就失去了博弈的意义。种群训练(Population Training)是一个缓解方案:维持一个包含多种策略的"种群",每次从中随机选择对手,确保模型需要应对多种不同的策略。
自博弈与前面章节的联系
自博弈和自进化的思想贯穿了整本书的核心主题。让我们梳理一下这些联系:
| 前面章节的概念 | 在自博弈/自进化中的对应 |
|---|---|
| AlphaGo 自博弈(第 5 章) | 自博弈的直接前身——从围棋到语言 |
| GRPO 组内比较(第 9 章) | 组内比较是"简化版自博弈"——同模型多回答互相比 |
| 经验回放(第 4 章) | 自进化中的"经验提炼"——从原样复用到总结提炼 |
| PPO(第 7 章) | 自博弈训练的策略优化算法 |
| RLVR(第 9 章) | 自博弈的 reward 可以用可验证信号,不需要 RM |
| Agentic RL(第 9 章) | 自博弈可以训练工具使用策略——模型自己生成工具调用场景 |
| 测试时搜索(12.1 节) | 自博弈学到的推理策略可以在推理时使用 |
最深刻的联系可能是:GRPO 就是自博弈的简化版。GRPO 让同一个模型生成多条回答,然后在组内比较——这相当于同一个模型的多个实例在"竞争"。自博弈把这个竞争扩展到了更复杂的场景:不只是比较最终答案,而是在多轮交互中对抗,甚至扮演不同的角色(Generator vs Judge,Debater A vs Debater B)。
从这个角度看,从第 9 章的 GRPO 到本章的自博弈,是一条自然的技术演进路线:从简单的组内竞争到复杂的多角色博弈,从固定数据集到持续进化的训练循环。
接下来我们讨论 12.4 LLM 多智能体 RL——从多智能体协作到基于模型的 RL,并动手用 PettingZoo 做实验。
参考资料
Chen Z, Deng Y, et al. "SPIN: Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models." ICML 2024. —— 将 RLHF 建模为自博弈,模型通过与"过去的自己"博弈来持续提升。
Metak Q, Yu D, et al. "Self-Rewarding Language Models." 2024. —— Meta 与 NYU 联合提出自我奖励语言模型,让同一模型同时扮演 Generator 和 Judge。
Zelikman E, et al. "STaR: Self-Taught Reasoner." NeurIPS 2022. —— 自我训练推理器,用自我生成的推理数据迭代提升。
Lanctot M, et al. "A Unified Game-Theoretic Approach to Multiagent Reinforcement Learning (PSRO)." NeurIPS 2017. —— 统一博弈论视角下的多智能体 RL 框架,引入 Policy Space Response Oracles。
Zhang R, Xu Z, et al. "A Survey on Self-play Methods in Reinforcement Learning." 2024. —— 自博弈 RL 领域最全面的综述,覆盖传统自博弈、PSRO、基于遗憾最小化的方法。
DeepSeek-AI. "DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning." 2025. —— 证明纯 RL(无 SFT 冷启动)也能激发推理能力。