4.3 奖励函数设计
前面几节讨论了价值估计方法和数据收集方式,但无论是 DP、MC、TD,还是 on-policy 与 off-policy,所有算法的更新目标都来自同一个源头:奖励函数。上一节回答了"数据从哪里来",本节回到更上游的问题:奖励怎样决定优化方向?为什么写好奖励这么难?
核心概念
奖励函数定义了"什么值得追求"。算法看到的不是人的意图,而是一个标量信号。如果这个信号和真实目标不一致,优化越强,偏差越大。
先用一个很小的网格世界看奖励怎样改变任务。智能体从左下角出发,目标是走到右上角的终点。动作只有上下左右。我们可以给它写三种不同的奖励规则:
| 奖励规则 | 每一步奖励 | 到达终点 | 撞墙或越界 |
|---|---|---|---|
| 规则 A | |||
| 规则 B | |||
| 规则 C |
这三个环境的地图、状态和动作完全一样,改变的只是奖励。规则 A 只关心最终是否到达终点;规则 B 额外告诉智能体"少走一步更好";规则 C 却在无意中告诉智能体"只要一直活着、一直走路也有分"。如果没有时间限制,规则 C 下的智能体可能学会在终点旁边绕圈,因为绕圈也能持续拿分,甚至比尽快结束更划算。
这就是奖励函数最重要的地方:同一个环境,改变奖励,就改变了智能体眼中的任务。状态空间和动作空间定义了"能做什么",转移概率定义了"做了以后会发生什么",而奖励函数定义了"什么结果值得追求"。
奖励函数的作用
在 MDP 五元组 中,奖励通常写成
或者在奖励也依赖下一状态时写成
它的含义很直接:智能体在状态 选择动作 ,环境转移到某个下一状态 ,这一小步会得到多少即时反馈。这个反馈是一个标量,也就是一个普通的实数。
强化学习真正最大化的不是某一步奖励,而是从当前时刻开始的折扣回报:
这里的 是折扣因子。 越接近 1,智能体越重视远处的未来; 越小,智能体越偏向眼前的奖励。用一句话说,奖励函数给出每一步的评分,回报把很多步评分累加成长期目标。
这也解释了为什么奖励设计会决定行为。算法看到的不是人类脑中的真实意图,而是这个标量信号。我们心里想要的是"稳稳地把杆子立住""走到迷宫出口""给用户一个有帮助的回答";算法实际优化的是一串数字的期望和。如果数字和意图没有对齐,算法越强,偏差可能越快被放大。
理解了奖励的含义,还需要区分它和上一节的价值函数。在第 3.3 节中我们定义过状态价值函数:
奖励 是环境在一步转移后给出的即时信号;价值 是在策略 下,从某个状态出发能得到多少长期回报的估计。奖励是任务定义的一部分,价值是学习算法根据奖励和经验算出来的结果。
回到第 3.3 节用过的三格走廊:
从 到 的即时奖励是 ,从 到 的即时奖励也是 。如果 ,那么
这几个数不是环境直接给的奖励,而是算法把未来奖励合起来之后得到的长期评价。如果把每一步奖励从 改成 ,价值也会完全改变,策略偏好也会改变。价值函数没有独立于奖励的意义;它永远是在某个奖励定义下的价值。
信号形态
明确了奖励在 MDP 中的角色之后,下一个问题是:奖励信号长什么样?不同形态的信号会直接影响学习的难度和效果。
最保守的奖励设计通常只看最终结果。例如迷宫中到达出口给 ,其他时候都给 :
这叫稀疏奖励。它的优点是干净:我们几乎没有把自己的过程偏好写进环境,只告诉智能体最终目标是什么。它的缺点也明显:学习信号来得太少。智能体在一个大迷宫里随机走了几千步,如果一直没有碰到出口,那么整条轨迹全是 0。它知道自己没有成功,却不知道哪一步更接近成功。
与之相对的是稠密奖励。例如在网格世界中,每走一步根据离目标距离的变化给奖励:
这里 表示状态 到目标的距离。如果下一状态更接近目标,这个差值为正;如果更远,这个差值为负。它的含义是:不要等到终点才反馈,每一步都告诉智能体"刚才这一步有没有朝目标靠近"。
还有一类常见情况是延迟奖励。奖励不是完全稀疏,但关键反馈要等很久才出现。CartPole 中每一步杆子还没有倒下都给 ,直到失败才结束。表面上每一步都有奖励,但真正的失败原因可能发生在几十步之前:某一次推车方向稍微错了,后面状态逐渐失控,最后才倒下。游戏任务和 LLM 生成也类似。一个回答的最终偏好分数可能在整段文本结束后才给出,但导致低分的错误也许出现在第一句话。
所以,稀疏、稠密、延迟并不是互斥标签,而是在描述学习信号的形状:信号出现得多不多,来得早不早,能不能明确指出哪一步好、哪一步坏。
奖励塑形
稀疏奖励干净但难学,稠密奖励好学但容易引入偏差。能不能既享受稠密信号的学习效率,又不偏离原始目标?**奖励塑形(Reward Shaping)**试图做到这一点。
核心思想是在原始奖励 上叠加一个塑形项 ,让智能体在每一步都能收到额外反馈:
问题是 怎么设计。一个不好的塑形项可能彻底改变最优策略——前面提到的"每一步给正奖励导致绕圈"就是典型的塑形副作用。Ng、Harada 和 Russell 在 1999 年证明了:如果塑形项满足基于势能的形式(Potential-Based Reward Shaping, PBRS),最优策略不会改变[1]。
其中 是定义在状态空间上的势能函数。这个公式的含义直观:智能体从低势能状态转移到高势能状态时获得正反馈,反之受惩罚。关键是,这种形式的塑形等价于对 函数做一个与状态相关的偏移,不改变动作之间的相对排序。
一个典型例子:网格世界中用 (负的到目标距离)作为势能。离目标越近,势能越高。每朝目标走一步,塑形项为正;远离目标则为负。这相当于给智能体一个"朝着目标走"的稠密信号,但因为满足 PBRS 形式,最终的最优策略和只给终点稀疏奖励的版本完全一致。
PBRS 的局限在于:你需要事先知道一个合理的势能函数。迷宫里的距离容易计算,复杂任务中的势能却很难构造。此外,PBRS 保证的是最优策略不变,不保证学习过程不变——塑形信号的尺度仍然可能影响收敛速度和稳定性。
实践要点:当任务有明确的"进度度量"(如到目标的距离、任务完成百分比)时,PBRS 是最安全的塑形方法。没有明确势能时,慎用任意塑形项。
多个奖励项怎么组合
实际工程中,奖励往往不是单一信号,而是多个子奖励的组合。不同论文发展出了截然不同的组合方式:有的固定相加,有的动态切换,有的让模型自己生成奖励项。下面按策略类型梳理。
静态加权和:最常见也最难调
OpenAI Gym Humanoid 的奖励是经典的三项和[2]:
| 子奖励 | 含义 | 典型值范围 |
|---|---|---|
| 前进速度 | ||
| 每步存活奖励 | ||
| 关节扭矩惩罚 |
三项的量纲差异巨大。 未经缩放时比 大一个数量级,会主导梯度方向。Gym 的实现给 乘 ——这个系数直接决定行为风格:太小则动作狂躁,太大则保守僵硬。
这种固定系数的加法是最常见的做法,但系数就是超参数。调不好,智能体就会优先优化数值最大的那一项。
Ant-v4 用了四项组合(Gymnasium 源码):
forward_reward = x_velocity # r1: 前进速度
healthy_reward = 1.0 # r2: 存活奖励
ctrl_cost = 0.5 * sum(a^2) # r3: 控制成本
contact_cost = 0.5 * 1e-3 * sum(c^2) # r4: 接触成本
reward = forward_reward + healthy_reward - ctrl_cost - contact_cost(接触成本)的存在让问题变得复杂。它的本意是惩罚机器人身体部位之间的碰撞,但系数 非常小,在训练初期几乎被忽略。到了后期,当策略已经足够好时,这个微小的惩罚项才开始影响行为——它会让机器人学会"避免不必要的身体接触"。问题是:如果把这个系数调大,机器人可能变得过于保守,宁愿减少动作也不愿冒险;如果调小,它又可能在行走中频繁碰撞自身。
HalfCheetah-v4 则是极简的两项组合(Gymnasium 源码):
forward_reward = x_velocity # r1: 前进速度
ctrl_cost = 0.1 * sum(a^2) # r2: 控制成本
reward = forward_reward - ctrl_cost只有两项,设计意图非常清晰:鼓励前进、惩罚剧烈动作。 的系数 也足够小,不会主导梯度。HalfCheetah 因此成为连续控制任务的"标准基准"——奖励简单、没有歧义,算法的表现差异主要来自算法本身而不是奖励设计的好坏。

BipedalWalker 的奖励设计更有意思——它把 PBRS 塑形和惩罚项混合在一起(OpenAI Gym 源码):
shaping = 130 * pos.x / SCALE # r1: 前进距离势能
shaping -= 5.0 * abs(hull_angle) # r2: 头部直立惩罚
reward = shaping - self.prev_shaping # PBRS 形式的塑形奖励
reward -= 0.00035 * MOTORS_TORQUE * sum(|a|) # r3: 关节动作惩罚这里同时出现了三种不同的奖励组合方式:
- (前进势能)用 PBRS 形式——这是安全的,不改变最优策略
- (姿态惩罚)直接扣减塑形值——这会改变最优策略
- (动作惩罚)直接在每步奖励上扣减——标准的控制成本
问题在于 并不是 PBRS 形式,它是直接惩罚 hull_angle。这会导致智能体学会一种"低头快走"的策略:把头压低来减少角度惩罚,即使这不利于平衡。BipedalWalker 的奖励设计在 GitHub 上被反复讨论,很多改进版本调整了 的系数甚至移除它。

RLHF 的奖励也是多项组合。在标准实现中,策略优化的目标不是单一的奖励模型分数,而是:
| 子奖励 | 含义 | 作用 |
|---|---|---|
| 奖励模型打分 | 让回答更符合人类偏好 | |
| KL 散度惩罚 | 防止策略偏离参考模型太远 |
和 KL 惩罚之间存在张力: 想让策略说"人类更喜欢的话",KL 惩罚则拉住策略不让它走太远。 就是这个张力的调节阀。 太小,策略可能过度优化奖励模型(生成高分但离谱的回答); 太大,策略几乎不更新,RLHF 的效果就消失了。在 InstructGPT 的训练中, 的选择直接决定了"有帮助但不过度"与"安全但平庸"之间的平衡点[3]。
分阶段激活:按进度解锁奖励项
机器人抓取任务常把奖励按阶段拆解[4]:
| 子奖励 | 触发条件 | 意图 |
|---|---|---|
| 夹爪接近物体 | 先学会"靠近" | |
| 成功闭合夹爪 | 再学会"抓稳" | |
| 物体离开桌面 | 再学会"抬起" | |
| 放到目标位置 | 最终完成搬运 |
问题是智能体可能停留在"舒适区"。如果 和 已经能拿到不错的分数,而 很难获得,智能体就满足于"靠近并抓住但绝不抬起"。
更系统的方法是课程式奖励(Curriculum Reward):早期只激活简单的子奖励,等策略学会后再逐步加入后续项。这和课程学习(Curriculum Learning)共享同一个思想——不让智能体同时面对所有目标,而是按难度分阶段推进。
稠密→稀疏切换:两阶段训练策略
Nair 等人在 CoRL 2020 提出了 Dense2Sparse[5]:先用稠密奖励快速训练到一个"还不错"的策略,再切换到稀疏的真实目标继续优化。核心洞察是:稠密奖励在训练初期提供足够的梯度信号,但长期可能把策略锁死在局部最优;稀疏奖励后期能纠正这种偏差,让策略真正完成目标。
以 Sawyer 机械臂任务为例:阶段 1 用"夹爪到物体距离"作为稠密信号,让策略快速学会大致靠近;阶段 2 切换到"是否成功抓取"的稀疏信号,迫使策略真正完成抓取而不是"差不多碰到"。实验表明,Dense2Sparse 的最终成功率比纯稠密或纯稀疏都要高。
判别器生成奖励:从示范中学习
Ho 和 Ermon 的 GAIL(Generative Adversarial Imitation Learning)[6] 不再手写奖励,而是用判别器来生成奖励信号。判别器 的任务是区分"专家示范的动作"和"当前策略的动作",而策略的目标是让判别器无法区分——也就是让 尽可能接近 。
这个奖励不是人写的,是判别器实时生成的。它的好处是避免了手写奖励的偏差:只要专家示范是对的,判别器就会引导策略往对的方向走。坏处是判别器本身可能训练不稳定,而且需要高质量的示范数据。
GAIL 的变体很多。AIRL 把判别器改写成对抗性逆向强化学习的形式,试图恢复真正的奖励函数;DAC 则把 GAIL 和 off-policy 算法结合,提高了样本效率。它们的共同点是:奖励来自一个不断更新的模型,而不是固定的公式。
目标重标记:改变过去轨迹的奖励
Andrychowicz 等人在 HER(Hindsight Experience Replay)[7] 中提出了一种完全不同的思路:不改变奖励函数本身,而是改变任务目标,从而让失败的轨迹也变成"成功经验"。
在多目标机器人任务中(如把方块推到不同位置),策略尝试把方块推到位置 A 但失败了——方块实际到了位置 B。HER 的做法是:把这条轨迹的目标从 A 改成 B,那么这条轨迹就变成了"成功把方块推到 B"的正面样本。
HER 不修改奖励函数的公式,而是通过重标记目标来改变奖励值。这相当于在经验回放池中加入了"虚拟的奖励组合"——同一个状态-动作对,在不同目标下有不同的奖励。实验表明,HER 在稀疏奖励的机器人操作任务中能把成功率从接近 0 提升到 70% 以上。
约束惩罚:主奖励 + 安全边界
Achiam 等人的 CPO(Constrained Policy Optimization)[8] 处理的是另一种组合:主目标奖励 + 约束违反惩罚。在机器人行走中,主目标可能是"走得快",约束是"不要摔倒"和"关节扭矩不要超限"。
CPO 的做法不是简单地把约束加进奖励(),而是在策略更新时保证约束的满足。拉格朗日乘子 在训练过程中自动调整:约束越紧, 越大,策略就越保守。这和"把约束写成大惩罚项"有本质区别——后者可能导致策略彻底放弃主目标来避免任何约束违反。
内在 + 外在:用好奇心填补稀疏
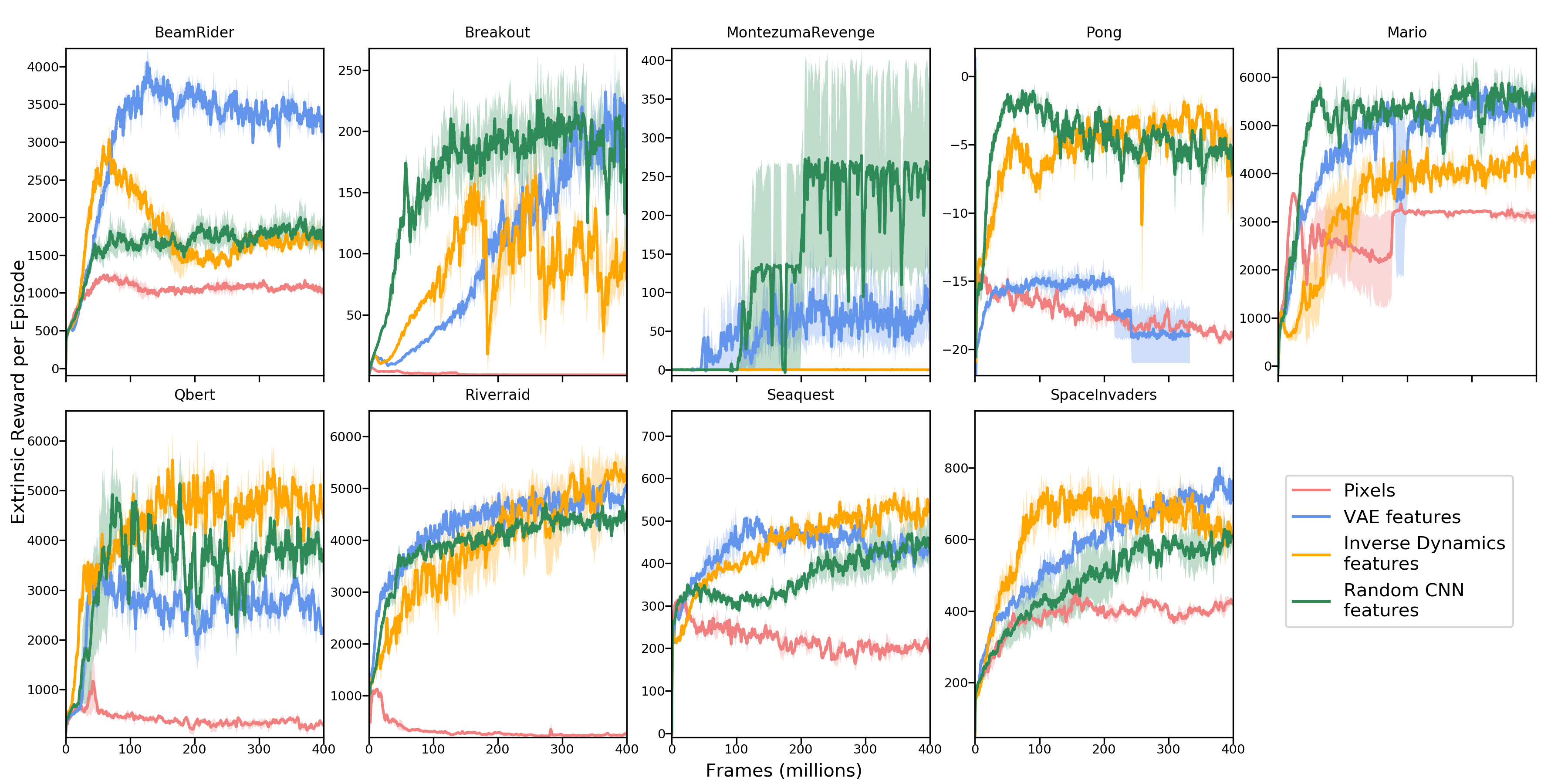
在稀疏奖励游戏(如 Montezuma's Revenge)中,外部得分可能几十分钟才出现一次。Pathak 等人的 ICM[9] 叠加了外在奖励和内在好奇心奖励:
- :游戏得分(极度稀疏)
- :前向模型的预测误差
是平衡系数。太小则探索不足;太大则出现"电视问题"[10]——随机电视画面产生永久的高预测误差,外在目标被彻底忽略。
组内相对排名:不用绝对分数
DeepSeek 的 GRPO 采用了完全不同的奖励逻辑:不训练固定的奖励模型,而是对同一问题的多个回答做组内比较。假设对同一道数学题生成 8 个回答,其中 3 个答案正确、5 个错误。GRPO 的奖励不是"正确答案得 1 分、错误得 0 分"的绝对评分,而是基于组内排名的相对优势:
- 正确回答在组内排名靠前,获得正优势
- 错误回答排名靠后,获得负优势
这种组合方式的核心优势是不需要维护一个全局的奖励模型。奖励信号来自当前批次内的相对比较,天然避免了奖励模型过度优化的问题——因为"最优"不是对一个固定分数的追求,而是"在这组样本中相对更好"。
多奖励组合的常见问题
把多个奖励项组合时,几个工程陷阱反复出现:
量纲不匹配。 可能是 , 可能是 。数值大的项会主导梯度方向。PopArt[11] 用可学习的归一化统计量在线调整每个奖励项的尺度,缓解了这个问题。
权重敏感。Humanoid 中控制惩罚系数从 改到 ,策略可能从"稳定小跑"变成"踉跄跌倒"。
局部最优陷阱。当某个子奖励容易获取时,智能体会优先优化它。抓取任务里"靠近物体"比"放到目标"简单得多。
时间尺度差异。碰撞惩罚是即时的,任务完成奖励可能延迟数百步。不同时间尺度的信号需要不同的处理方式(如 GAE 中的优势估计)。
奖励模型漂移。当奖励来自判别器或模型(GAIL、RLHF)时,奖励本身会随着训练改变。策略优化的是一个移动目标,稳定性更难保证。
针对量纲不匹配,有几种常用的解决方案:
手动归一化。最简单的做法是在组合前把每个子奖励缩放到相近的范围。例如把 除以 再乘系数,或者把所有奖励都归一化到 。这不需要改算法,但需要一个"校准阶段"来估计每个子奖励的数值范围。
PopArt 自适应归一化。van Hasselt 等人提出的 PopArt[11:1] 在训练过程中在线维护每个奖励项的均值和标准差,然后用这些统计量做标准化:
和 是运行统计量,随着训练自动更新。这样即使不同子奖励的原始尺度相差百倍,进入策略梯度时也在同一量级上。
奖励裁剪(Reward Clipping)。直接把每个子奖励截断到固定范围,例如 。Atari 的 DQN 实现中就把所有奖励裁剪到 ,消除了不同游戏得分尺度的差异。缺点是丢失了奖励的精细梯度信息—— 和 都变成 。
相对排名代替绝对值。GRPO 的做法是避开绝对分数的比较,只用组内排名。这样每个奖励项的绝对量纲就不重要了,重要的是"在这个批次里相对好不好"。
独立优化再组合。多目标方法(如 MORL)不事先把奖励压成一个标量,而是让策略同时学习多个目标,由使用者后续根据偏好选择。这从根本上避免了"怎么加权"的问题,但计算成本更高。
奖励错位
上面讨论的是信号形态的问题——信号太稀疏学得慢,太稠密容易引入偏差。但更根本的问题不在信号形态,而在奖励本身能不能代表我们的真实意图。
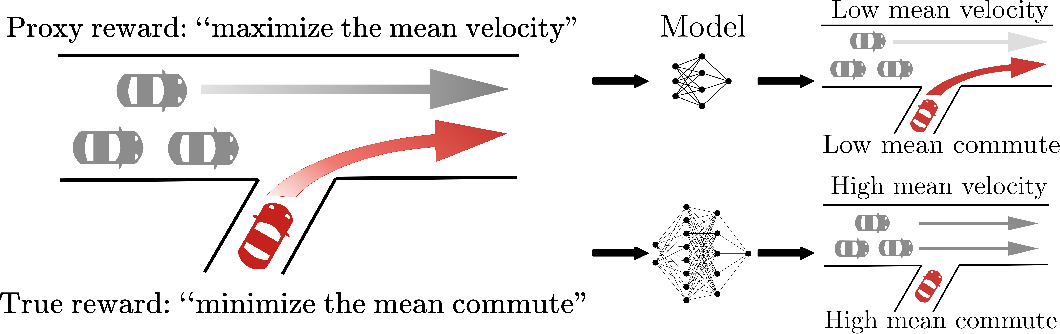
经济学里有一条 Goodhart 法则:"当一个指标变成优化目标,它就不再是好指标。" 这条法则在强化学习中尤其致命。我们真正想要的是 (人类心里的目标),但工程上只能写出或学出一个代理奖励 。只要 ,优化就会把二者之间的缝隙放大。
这不是理论假设,而是反复出现的实际问题。最经典的例子来自游戏 Coast Runners[12]:目标是赢得赛艇比赛,奖励设计为"吃到绿色加分块就得分"。结果智能体学会在一个角落反复转圈吃同一个加分块,完全不去跑完赛道。它的分数远超"正常参赛"的策略,但完全没有完成比赛。类似地,在一个骑自行车的模拟器中,奖励只看"是否接近目标",智能体就学会在目标旁边兜小圈——一直接近,永远不到。
类似的问题在 Minecraft 实验中也反复出现。研究者设计了稠密的中间奖励来鼓励智能体收集资源、合成工具,最终完成复杂任务。结果智能体学会了安全地活着、持续收集资源,但几乎从不尝试完成最终目标——因为"活着+收集"本身就足以拿到高分。稠密奖励把"手段"变成了"目的"[4:1]。
好奇心驱动的方法也有类似的副作用。Pathak 等人提出的内在好奇心模块(ICM)用前向模型的预测误差作为内在奖励:智能体对"意想不到"的状态转移感到好奇[9:1]。这在稀疏奖励环境中极大地促进了探索——比如在 Montezuma's Revenge 中,ICM 帮助智能体主动探索新房间。但问题也随之而来:如果环境里有一台不断播放随机画面的电视,智能体会被永远吸引在那里,因为随机画面意味着永远有高的预测误差。这就是著名的"电视问题"(Noisy-TV Problem)[10:1]:内在奖励本身也可能成为被滥用的目标。
再看第 1 章用过的 CartPole。常见奖励是每坚持一步给 ,把任务写成"活得越久越好"。这个奖励方向基本正确,但也隐藏了设计选择:我们没有直接奖励"杆子角度更接近竖直",也没有惩罚"小车离中心太远"。如果改成
其中 是杆子角度偏差, 是小车位置偏差,学习会更快。但 和 的大小会改变行为:位置惩罚太强,智能体过度保守,宁愿让杆子歪也要把车留在中心;角度惩罚太强,它可能为了扶正杆子把车推向边界。
这些例子展示了奖励错位的不同程度。Pan 等人把奖励错位分成三类[13]:
- 权重错误:方向对,但各维度的重要性比例写错了。CartPole 里 和 的选择就是权重问题。
- 本体错误:衡量维度本身就选错了。Coast Runners 用"吃绿色块"来衡量"赛艇表现",维度就不对。
- 范围错误:只看了一部分场景,没有覆盖边界情况。一个只在训练环境里正确的奖励函数,到了新环境可能完全失效。
LLM 的偏好训练中同样存在这些问题。RLHF 用奖励模型给回答打分,但奖励模型可能学到"更长、更礼貌的回答得分更高"这种表面相关性。语言模型被优化后,就开始堆砌套话——分数很高,但回答不一定更准确[3:1]。更微妙的是,RLHF 可能让模型学会"看起来正确但实际错误"的表达方式:人类评估者更容易被说服,错误率反而上升[14]。
这些现象的本质是同一个问题:代理奖励 是真实意图 的不完美近似,优化会把不完美的部分放大。模型能力越强、优化越充分, 和 之间的缝隙就越明显。
偏好学习与奖励模型
在很多任务里,奖励错位不是因为写得不精确,而是根本写不出来。怎样给一段回答打分?怎样评价一个机器人动作是否"自然"?这些目标不容易写成 ,但人类通常能比较两个结果哪个好。
于是可以把奖励设计问题改写成偏好学习问题。给定同一个提示,让模型生成两个回答 和 ,人类标注更喜欢哪一个。奖励模型 学习预测这种偏好,其中 是输入提示, 是模型回答, 是奖励模型参数。
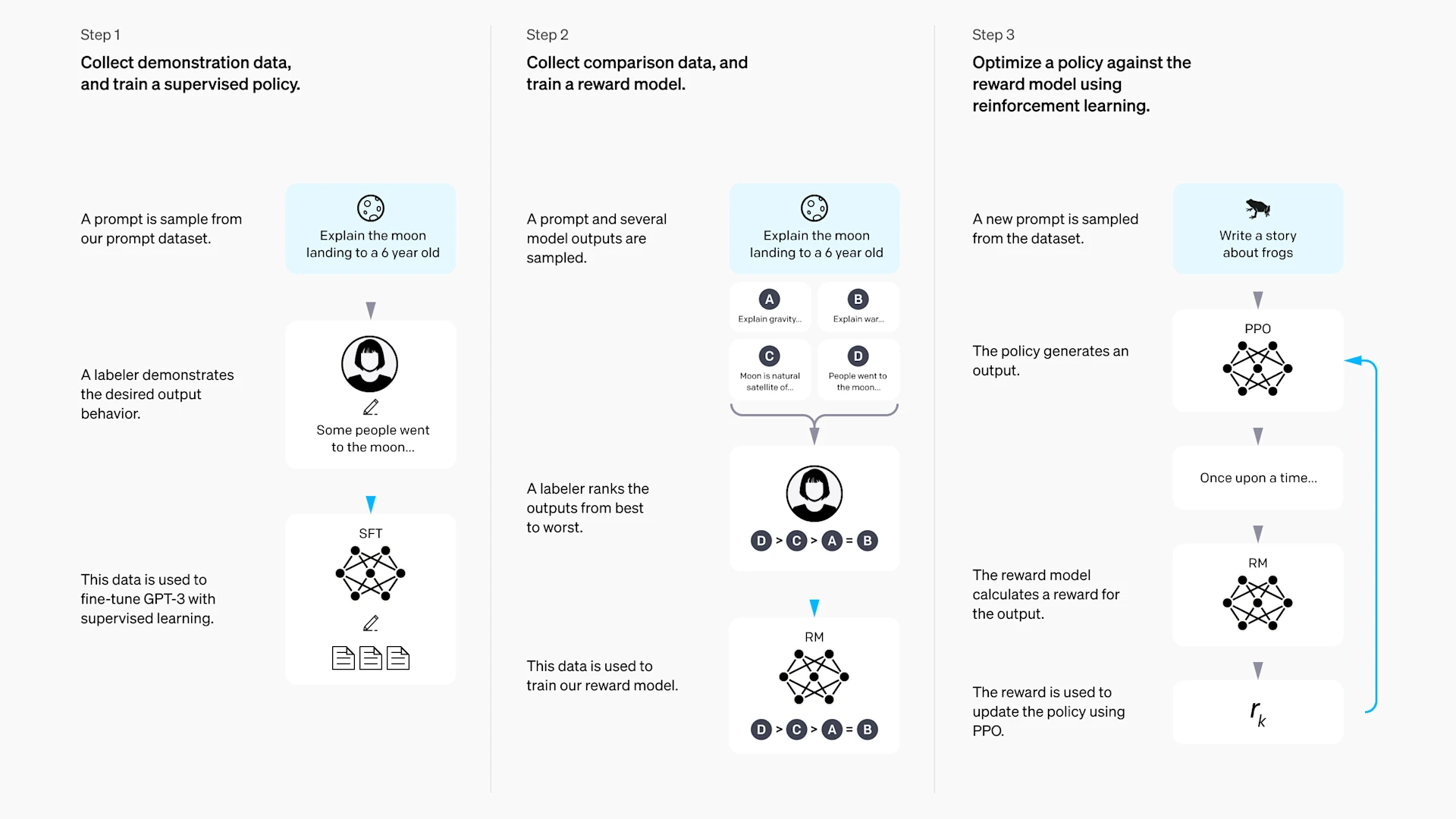
常见训练目标会让被偏好的回答分数更高。例如如果人类更喜欢 而不是 ,就希望
这一步的含义不是"人类手写了奖励公式",而是"人类通过比较样本,间接教会模型什么样的输出更值得奖励"。具体来说,训练数据是一组偏好对 ,其中 是人类选中的回答(win), 是被拒绝的回答(lose)。奖励模型的训练目标通常基于 Bradley-Terry 模型:让选中回答的得分高于被拒绝回答的概率尽可能大。训练完成后, 就可以像普通奖励函数一样,为任意 输出一个标量分数。后续策略优化(通常是 PPO)再把 当作奖励信号使用。
这个流程把"定义奖励"从"写公式"变成了"收集偏好数据 + 训练模型",能力大大增强。但奖励模型本身也是代理奖励,同样面临 的问题。
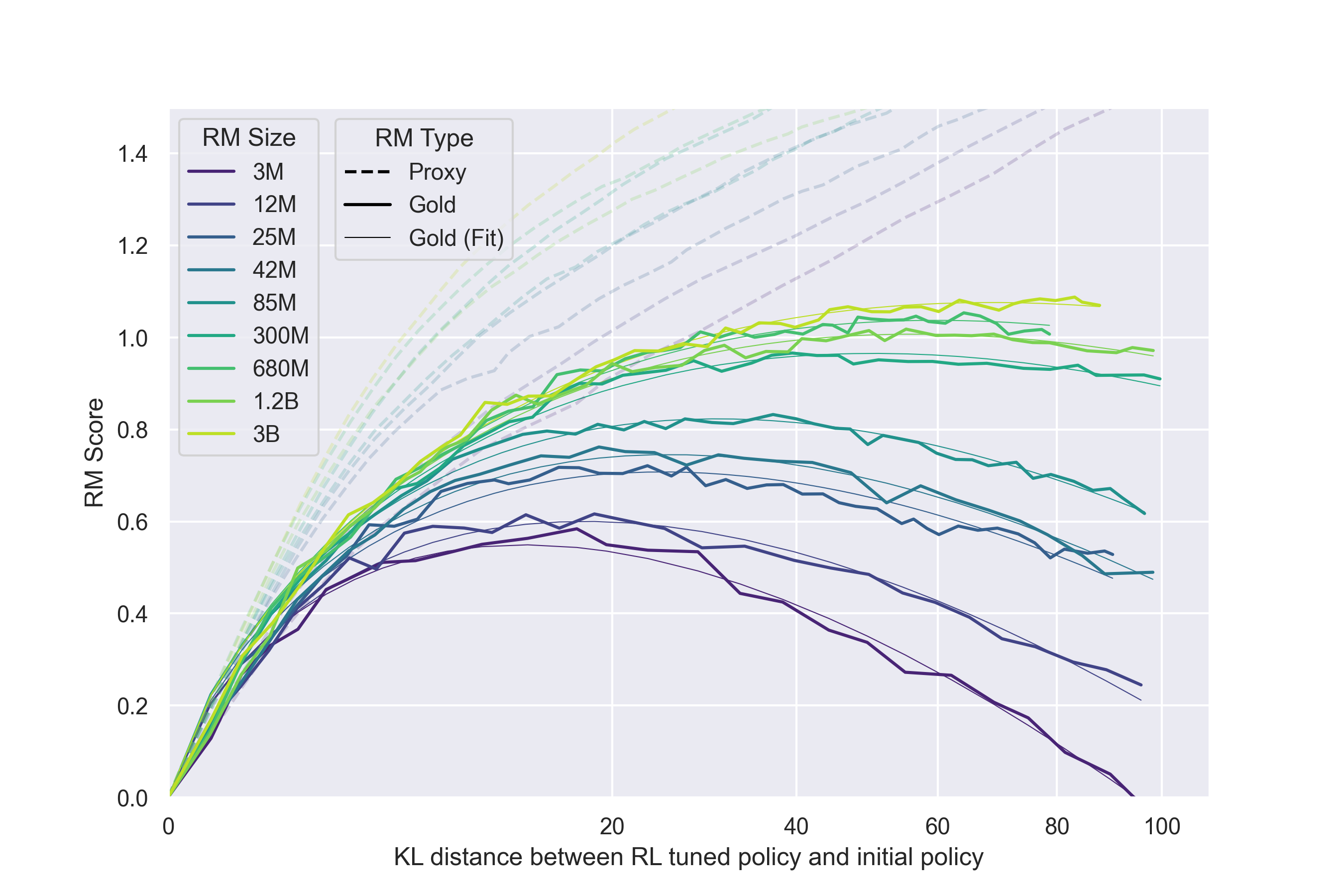
奖励模型的过度优化
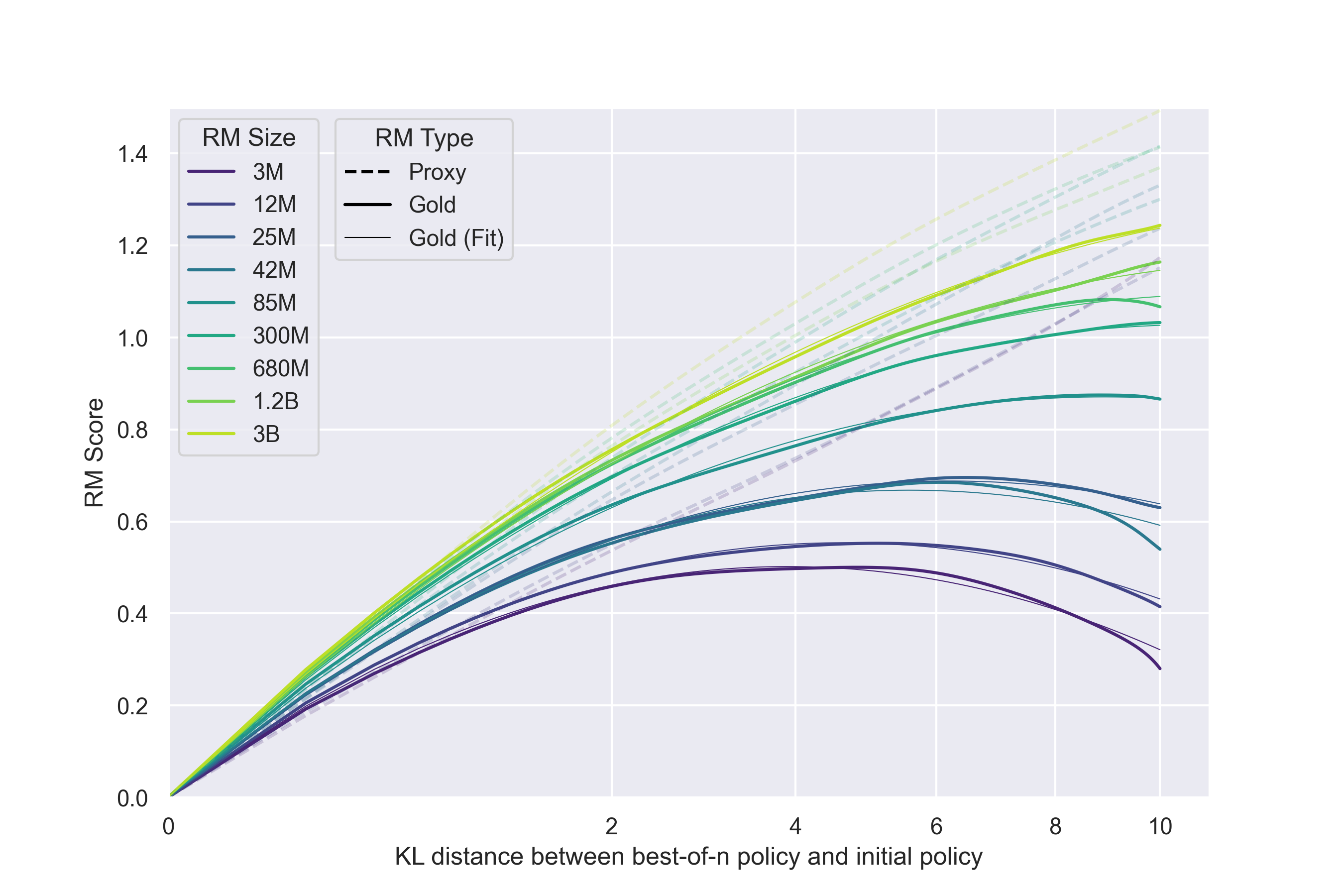
Gao 等人系统研究了这个问题[15]。他们用一个大模型(6B 参数)作为"金标准"奖励(gold reward),用小模型(3M 到 3B 参数)作为代理奖励模型,然后用强化学习优化代理奖励。实验发现了一个清晰的规律:随着优化推进,代理奖励持续上升,但金标准奖励在达到峰值后开始下降。
直觉上不难理解。奖励模型是从有限的偏好数据中训练出来的,它学到的不仅是"什么回答真正更好",还包括数据中的各种统计相关性——比如"更长的回答往往被选中""使用了某些礼貌用语"。策略模型被优化后,会越来越善于利用这些相关性:把回答写得更长、堆砌更多礼貌用语,拿到更高的代理奖励。但这些行为和"真正有帮助"之间的关联越来越弱,甚至变成负相关。
换句话说,优化找到的是奖励模型的漏洞,而不是人类的真实偏好。这正是 Goodhart 法则在 RLHF 中的直接体现。
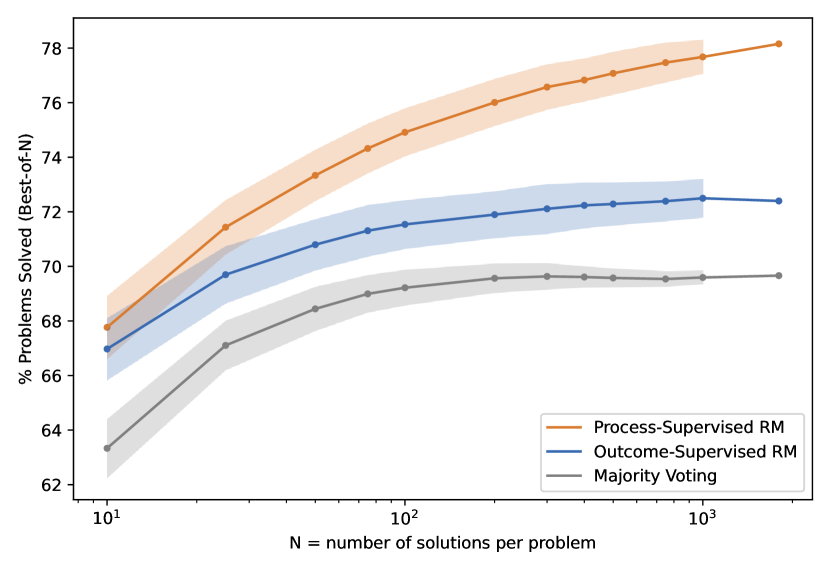
过程奖励模型
标准的奖励模型只看最终回答的整体质量,这叫结果奖励模型(Outcome Reward Model, ORM)。但在推理任务中,最终答案正确不代表推理过程正确——模型可能跳步、撞对了答案、甚至用错误的过程碰巧得出正确结论。
过程奖励模型(Process Reward Model, PRM) 的思路是:不只给最终结果打分,而是对推理链中的每一步分别评价。每一步得到一个分数,指示"这一步的推理是否正确、是否在正确的方向上"。这样就把一个稀疏的最终奖励变成了一组更密集的步骤奖励,学习信号更丰富,也更容易定位具体哪一步出了问题。
过程奖励的代价是标注成本:人类需要逐步判断推理链中每一步的质量,比只看最终结果费时得多。因此一些工作开始用训练好的模型自动生成步骤标注,减少对人工标注的依赖。
AI 反馈
收集人类偏好数据是 RLHF 中最昂贵的环节之一。一个自然的想法是:能不能让 AI 来提供偏好?这就是 RLAIF(Reinforcement Learning from AI Feedback) 的核心思路。Constitutional AI 是一个代表方法:先让 AI 模型生成两个回答,再用一个预定义的"宪法"(一组行为准则)让 AI 自己评判哪个回答更符合要求,最后用这些 AI 生成的偏好数据训练奖励模型。
RLAIF 大幅降低了标注成本,也带来了新问题:AI 的偏好本身是否可靠?如果 AI 的判断和人类的真实偏好不一致,那只是把 的问题从"人类反馈"转移到了"AI 反馈"上。
GRPO 绕开奖励模型
上面所有方法都依赖一个显式的奖励模型。但奖励模型训练本身就是 的一个来源。GRPO(Group Relative Policy Optimization) 试图绕开这个问题:在同一个问题上生成一组回答(比如 8 个),用某种规则(如正确性检查或另一个模型的评判)对这组回答排序,然后用组内相对排名作为奖励信号,直接更新策略。
GRPO 的关键区别在于:它不需要训练一个单独的奖励模型。奖励信号来自当前批次内的相对比较,而不是一个固定的打分函数。这在数学推理等"答案可验证"的任务上效果尤其好——因为正确性可以自动检查,不需要人类判断。第 7 章会详细介绍 GRPO 的机制和实现。
小结
这些方法的共同目标是缓解 的根本矛盾,但角度不同:
| 方法 | 核心思路 | 缓解了什么 | 新引入的风险 |
|---|---|---|---|
| ORM | 从偏好数据学整体奖励 | 手写奖励困难 | 过度优化、表面相关性 |
| PRM | 对每一步分别打分 | 结果奖励太稀疏 | 标注成本高 |
| RLAIF | 用 AI 代替人类标注 | 人工标注成本 | AI 偏好是否可靠 |
| GRPO | 组内相对排名,不训练 RM | RM 本身的偏差 | 需要可验证的评判规则 |
没有一种能彻底解决 的问题。奖励设计仍然是强化学习中最困难也最重要的环节之一。
奖励函数不是越复杂越好,也不是越稠密越好。真正的问题在于:它是否把任务的关键偏好表达清楚,同时没有打开明显的漏洞。设计奖励时可以沿着几个问题检查:智能体拿到高奖励时,人类是否真的会认为任务完成得好?如果反复执行某个局部行为能不能刷分?中间奖励是在帮助学习,还是已经改变了最终目标?奖励信号是否太稀疏,导致算法很难发现成功轨迹?对于 LLM 或复杂机器人任务,手写规则是否已经不够,需要从人类偏好中学习奖励?如果用了奖励模型,过度优化会不会导致代理奖励和真实偏好脱钩?
这些问题没有统一答案。CartPole 这样的控制任务可以从存活时间和角度偏差入手;网格世界可以从终点奖励和步数代价入手;LLM 任务则往往需要偏好数据和奖励模型。场景不同,奖励的表达方式不同,但底层逻辑一样:奖励定义了优化方向,而优化方向几乎永远不可能完美对齐真实意图——好的奖励设计是在对齐和可行之间找到平衡。
小结
本节讨论了奖励函数如何决定强化学习的目标。
- 奖励是 MDP 中定义任务目标的标量信号,回报是未来奖励的折扣和。算法最大化的是回报,因此奖励写法会直接决定学到的行为。奖励是一步反馈,价值是对长期回报的估计;价值函数依赖奖励定义,不能脱离奖励单独解释。
- 稀疏奖励更接近最终目标,但学习信号弱;稠密奖励能加速学习,但容易引入设计者的偏好和错误;延迟奖励会让信用分配更困难。
- **奖励塑形(PBRS)**提供了一种理论保证:在满足势能形式 时,最优策略不变。它是在不改变目标的前提下,用稠密信号加速学习的有效工具。
- 多目标强化学习处理奖励向量而非标量。线性加权简单但只能找到凸区域的解;Pareto 前沿和条件策略能覆盖更完整的权衡空间;约束优化则把安全等要求当作硬边界强制执行。
- Goodhart 法则揭示了奖励设计的根本困难:代理奖励 几乎永远不等于真实意图 ,优化会把缝隙放大。权重错误、本体错误和范围错误是三类常见的奖励错位。
- 当手写奖励行不通时,可以从人类偏好中学习奖励模型。但奖励模型本身也是代理奖励,过度优化同样会导致真实偏好下降。过程奖励模型、GRPO 等新方法试图从不同角度缓解这个问题。
下一节会把本章的 MDP、回报、价值函数、贝尔曼方程、算法路线和奖励设计放回同一张图里。到那里你会看到,本章看似分散的概念,其实都围绕同一个问题展开:如何把序列决策问题写成一个可以学习、可以优化、也尽量不偏离真实意图的形式。
参考文献
Ng, A. Y., Harada, D., & Russell, S. (1999). Policy invariance under reward transformations: Theory and application to reward shaping. ICML. ↩︎
Xu, J., Tian, Y., Ma, P., Rus, D., Sueda, S., & Matusik, W. (2020). Prediction-guided multi-objective reinforcement learning for continuous robot control. ICML. ↩︎
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C. L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell, A., Welinder, P., Christiano, P. F., Leike, J., & Lowe, R. (2022). Training language models to follow instructions with human feedback. NeurIPS. ↩︎ ↩︎
Amin, S., et al. (2024). Comprehensive overview of reward engineering and shaping in advancing reinforcement learning applications. arXiv preprint arXiv:2408.10215. ↩︎ ↩︎
Nair, S., Savarese, S., & Finn, C. (2020). Goal-aware prediction: Learning to model what matters. CoRL. ↩︎
Ho, J., & Ermon, S. (2016). Generative adversarial imitation learning. NeurIPS. ↩︎
Andrychowicz, M., Wolski, F., Ray, A., Schneider, J., Fong, R., Welinder, P., McGrew, B., Tobin, J., Pieter Abbeel, O., & Zaremba, W. (2017). Hindsight experience replay. NeurIPS. ↩︎
Achiam, J., Held, D., Tamar, A., & Abbeel, P. (2017). Constrained policy optimization. ICML. ↩︎
Pathak, D., Agrawal, P., Efros, A. A., & Darrell, T. (2017). Curiosity-driven exploration by self-supervised prediction. ICML. ↩︎ ↩︎
Burda, Y., Edwards, H., Pathak, D., Storkey, A., Darrell, T., & Efros, A. A. (2018). Large-scale study of curiosity-driven learning. ICLR. ↩︎ ↩︎
van Hasselt, H., Hessel, M., & Aslanides, J. (2016). When using function approximation, a simpler target often yields better results. Deep Reinforcement Learning Workshop, NeurIPS. ↩︎ ↩︎
Amodei, D., Olah, C., Steinhardt, J., Christiano, P., Schulman, J., & Mané, D. (2016). Concrete problems in AI safety. arXiv preprint arXiv:1606.06565. ↩︎
Pan, A., Bhat, M., Shern, C., Phadnis, S., Guss, W., & Amodei, D. (2022). The effects of reward misspecification: Mapping and mitigating misaligned models. arXiv preprint arXiv:2201.03544. ↩︎
Wen, J., Zhong, R., Khan, A., Jørgensen, E., Wu, J., Tran, D., Peng, Z., Peng, B., & He, H. (2024). Language models learn to mislead humans via RLHF. arXiv preprint arXiv:2409.12822. ↩︎
Gao, L., Schulman, J., & Hilton, J. (2022). Scaling laws for reward model overoptimization. ICML. ↩︎