3.1 V/Q 函数与贝尔曼期望方程
本节导读
核心内容
- :评价策略 在状态 下未来平均能拿多少分。
- 贝尔曼方程:把“看完整个未来”改写成“眼前奖励 + 下一状态价值”。
- 价值表:在有限状态问题中,把每个状态的 存成一组可以更新的数字。
- 从 到 :先评价策略,再比较动作,最终服务于找到更好的策略。
上一节我们建立了 RL 的形式化框架:MDP 描述环境规则, 衡量一条轨迹的总回报,策略 规定每一步怎么选动作。有了这些符号,我们已经能描述一个智能体如何和环境交互。但描述还不是求解。强化学习最终关心的是策略:在同一个状态下,换一种动作选择方式,未来可能完全不同。因此,在讨论“怎样找到好策略”之前,我们先要解决一个服务于策略改进的基础问题:怎样评价当前策略在各个状态下的表现?
状态价值函数 就是为这个问题准备的。它问的是:如果智能体现在站在状态 ,并且从这一刻开始始终按照策略 行动,那么未来平均能拿多少总回报?注意, 不是状态天然自带的分数,而是策略 在状态 下的表现。同一个 CartPole 局面,错误策略可能很快让杆子倒下,好的策略却能把杆子稳定住;状态相同,策略不同,价值就不同。
直接计算 看起来需要枚举从 出发的所有未来轨迹,这通常不可行。贝尔曼方程的作用,就是把这个长远评价拆成一步递推:先看眼前奖励,再把剩下的未来交给下一状态的价值。这样,评价策略不再需要一次看完整个未来,而可以通过相邻状态之间的关系逐步传播回来。
给定一个策略 ,如何评价它在每个状态下的表现?进一步,如果我们想得到更好的策略,怎样从“评价状态”走向“选择动作”?
核心概念
贝尔曼方程连接“评价策略”和“改进策略”:先用 评价策略,再用 或最优方程比较动作,策略才有改进方向。
核心公式
状态价值与贝尔曼方程 (State Value and Bellman Equation):
- :策略 在状态 下的价值(Value),即从 开始按策略 能拿到的平均总分。
- :未来第 步拿到的单步奖励(Reward)。
- :折扣因子(Gamma),控制对未来奖励的重视程度()。
- :动作空间,表示当前任务里所有可选动作的集合。例如 CartPole 里通常是“向左推”和“向右推”。
- :策略(Policy),在状态 下选择动作 的概率。
- :状态转移概率,在状态 采取动作 后,跳到下一个状态 的概率。
本节会反复使用下面这些符号。先明确它们各自表示什么:
| 符号 | 可以先怎么理解 |
|---|---|
| 第 步的状态,比如棋盘局面、机器人姿态 | |
| 第 步的动作,比如往左走、输出一个控制量 | |
| 动作空间,所有可选动作的集合 | |
| 第 步拿到的即时奖励 | |
| 策略在状态 下选择动作 的概率 | |
| 折扣因子,越远的奖励权重越小 | |
| 从第 步开始往后累积的总回报 | |
| 在状态 开始,按策略 行动的平均总回报 |
这里有一个很重要的区分:
- 是眼前这一步的即时奖励。它只看一步,走出这一步以后才知道。
- 是从第 步开始,沿着某一条具体轨迹实际拿到的折扣总回报。它看的是一整条轨迹,所以不同轨迹会有不同的 。
- 不是某一条轨迹的分数,而是从状态 出发、按策略 行动时,对许多可能轨迹上的 取平均。
G 和 V 有什么区别?看一个数值例子
先写完整定义。折扣回报 的原始公式是:
把求和展开,就是:
现在为了演示,假设折扣因子 ,从同一个状态 出发,按同一个策略玩两次,并且每次只截取前三步奖励。也就是先看这个三步截断版本:
第一次比较顺利,三步奖励分别是 。代入公式:
计算得到:
第二次后面遇到坏结果,三步奖励分别是 。同样代入公式:
计算得到:
注意,两次的第一步即时奖励都是 ,但后面发生的事情不同,所以整条轨迹的 差很多。状态价值 是这些可能 的期望;如果现在只有这两次采样,可以先用它们的平均值做一个粗略估计:
所以, 是一步分数, 是从某一刻开始沿着一条轨迹实际拿到的总分,而 要回答的是:如果很多次都从同一个状态 出发,长期来看这些总分平均是多少。
状态价值函数
上一节我们有了 MDP 五元组来描述游戏规则、 来衡量从某一时刻开始、沿着一条实际轨迹拿到的总成绩, 来定义怎么选动作。但真正做决策时,你面对的不是“已经发生的一整局”,而是某个具体的中间局面。你需要的不是事后总结“这一次最后拿了多少分”,而是事前判断“如果我现在站在这个局面,未来大概有多好”。
这里的“平均”很重要。它不是对时间步平均,也不是把一局里的奖励简单除以步数;它是对从同一个状态 出发、按照同一个策略 继续行动时,可能发生的很多条未来轨迹取平均。因为策略可能随机,环境转移也可能随机,所以即使都从同一个状态 出发,后面也可能走出不同轨迹,得到不同的 。
沿用上面的数字:同样从状态 出发,一条未来轨迹的回报可能是 ,另一条可能是 。这两个数都是“某一次真实发生后的总分”。如果在策略 下,第一种未来出现的概率是 ,第二种未来出现的概率是 ,那么状态价值就是:
所以, 像是“这一次实际跑出来的成绩单”,而 像是“还没开跑前,站在同一个状态 ,对很多种可能成绩单做出的平均预测”。
这就自然引出了状态价值函数 :把 从“一次实际发生的总分”变成“站在状态 时,未来总分的平均预测”。形式化地说,它就是 在条件 下的期望:
状态价值函数的定义是:
如果把 展开,就是:
这行公式可以按三层读:
- :从现在开始,把未来奖励加起来。
- :越远的奖励打折越多。 只看眼前, 接近 1 更重视长期。
- :环境和策略可能有随机性,所以我们看很多次尝试的平均结果。
展开前几项看得更清楚:
每一项的含义: 是马上拿到的奖励(不打折), 是下一步奖励打一次折, 是两步后的奖励打两次折……越远的奖励,折扣系数 的幂次越高,贡献越小。用 CartPole 的数字感受:每步 ,,则 (假设策略能永远活下去)。
一句话: 是”从状态 出发,按策略 玩下去,平均能拿多少总分”。
为什么上标要写 ?因为同一个状态,策略不同,价值也不同。在同一个棋局里,高手继续下和新手继续下,最终胜率当然不一样。好策略的 高,差策略的 低。RL 的目标,就是找到让价值最高的策略。
贝尔曼方程
现在回到计算本身。如果要评价策略 在状态 下的表现,最直接的办法似乎是把从 出发的未来轨迹都算出来,再对回报取平均。但未来轨迹可能很长,也可能分叉很多。幸好,回报本身有一个递归结构:。而状态价值又定义为 。把这两件事放在一起,自然产生一个问题:既然一条轨迹的回报 可以递归,那么评价策略用的 是否也能递归?
答案是肯定的。这就是贝尔曼方程。它不是凭空发明的概念,而是从 的定义出发,利用 的递归结构,把“评价策略”改写成“当前一步 + 下一状态评价”的结果。推导之前,先理解它为什么必要:
我们在前面已经定义了状态价值 :它是未来所有奖励的折现总和的期望。如果想知道一个状态的价值,最直观的想法就是:直接顺着策略往下走,把一条长长轨迹上的奖励加起来不就行了吗?
但这在现实中面临两个巨大的困难:
- 未来太长了:有些任务没有明确的终点(比如维持机器人的平衡),你要加到猴年马月?
- 可能性太多了:因为环境和策略都有随机性,状态会像树枝一样呈指数级分叉。要算出一个准确的期望,你需要遍历无数条轨迹。
面对这种无限视野和庞大状态树的问题,1950 年代,美国应用数学家理查德·贝尔曼(Richard Bellman) 在创立动态规划(Dynamic Programming)理论时,提出了大名鼎鼎的最优性原理(Principle of Optimality)。他发现:我们不需要一眼望穿整个未来,因为“今天的价值”里,必然包含着“明天的价值”。
这就像是算退休金。你不需要现在就把未来 30 年每一天的利息都分别算清楚再相加,你只要知道:“今天的总资产 = 今天的收益 + 明天本金带来的未来总资产”。这种把一个无限期的大问题,精妙地拆解成“当前这一步”和“剩下所有步”的思想,就是动态规划的灵魂。
基于这个原理写出来的递推等式,就被称为贝尔曼方程(Bellman Equation)。它将策略评价从一个难以直接计算的“无限求和问题”,转化成只依赖相邻状态的递推关系。也正因为有这个递推关系,后续 DP、MC、TD 等方法才能通过迭代或采样来估计价值。
接下来,我们就来看看这个神奇的”递归圈”在数学上是如何从 的原始定义中严谨推导出来的。
推导过程
前面我们凭直觉理解了价值的递推关系,现在我们给出严谨的数学推导。贝尔曼方程的本质是揭示了当前状态价值与未来状态价值之间的递归关系。这一步推导的伟大之处在于:它在数学上严格证明了,我们完全可以把对未来的无限穷举遍历,等价替换成只看“眼前一步”的递归计算。
根据状态价值函数的定义,将其展开:
这里 是固定策略 后,在状态 获得的期望即时奖励。它已经把动作的不确定性平均进去了:
接下来是最关键的一步:我们确实想把 改写成“下一状态价值”的形式,但这里不能直接写成 。
这个直接等号在数学上是不对的。
我们打个比方来理解这种微妙的差别:
- 就像是:你今天(站在 ) 在预测明天开始() 能赚多少钱。因为明天可能会落到不同状态,所以这个数已经把“明天会去哪里”的不确定性平均掉了。
- 就像是:你明天(已经站在某个具体的 ) 再来算未来能赚多少钱。但在今天看来, 还没发生,所以 本身仍然是一个随机变量。
所以,真正不能直接写的是:
左边是一个已经在条件 下取完平均的数,右边却还是依赖随机下一状态的量。正确的目标是把右边也放进同一个条件期望里:
要把视角(也就是概率论里的条件)从 顺利过渡到 ,我们其实不需要什么高深定理,只需要三个基础的数学工具:条件期望的定义、概率论中的边缘化(Marginalization),以及强化学习最重要的物理假设——马尔可夫性(Markov Property)。
补充证明:如何严谨地把条件从当前状态推到下一状态?
为了不引入让人眼花缭乱的新符号,我们全程只用 (当前状态)、(下一状态)和 (未来的总回报)这三个变量。 我们的终极目标是证明:。
在推导之前,我们要先复习一个高中概率知识:什么是条件变量?期望()到底怎么展开?
想象你在掷两枚骰子 和 。如果别人没告诉你任何信息,让你猜 掷出来的点数平均会是多少(即期望),你会怎么算? 很简单:把骰子可能掷出的所有点数(1到6),分别乘以它们掷出的概率(1/6),然后全部加起来。写成公式就是:。这就是最普通的期望。 但如果别人偷偷告诉你:“嘿, 掷出了个 6”。这时候, 就是一个已知条件(条件变量)。在已知 的情况下去猜 ,你的预测肯定会变,这就叫条件期望。写成公式就是把普通的概率换成条件概率:。
这个“把大写 拆成连加号 和条件概率 相乘”的操作,是我们下面推导的核心武器。记住:竖线
|后面的东西,就是我们站在当下已经确定的“既定事实”。
第一步:展开 的期望
根据定义, 就是在给定 且之后继续遵循策略 的情况下,未来回报 的期望。我们用上面复习的公式把它展开: 。
所以,我们等式右边要算的式子 ,其实就是在算一大串东西的期望:
第二步:对下一状态 再次展开期望
上面那个式子最外层还有一个大写的 。括号里的东西虽然长,但它本质上就是明天()的价值。
因为“明天”会发生什么是随机的,所以 是一个不确定的变量。我们怎么算这个随机变量的期望?还是用刚才那招:把每种可能出现的明天,乘以明天出现的概率,然后加起来。
也就是说,外层的 变成了 :
注:第二行只是把括号拆开,把外面的 乘进去了。
第三步:注入马尔可夫性(最关键的一步!)
注意上面式子里的 。根据马尔可夫性,在策略 固定之后,未来的回报 只和刚好发生的那一刻的状态 有关,跟更早之前的状态 没关系。 这就好比你掷骰子,第二把的结果只跟第二把怎么掷有关,跟第一把没关系。所以在数学上,我们可以在条件里强行塞进一个 ,它并不会改变概率的值:。代入上式:
第四步:概率的乘法公式与边缘化
如果高中的概率知识忘了也没关系,我们可以简单推导一下条件概率的乘法公式。 最基础的条件概率公式是:,也就是“在 B 发生的前提下,A 发生的概率”等于“A 和 B 同时发生的概率”除以“B 本身发生的概率”。 把分母乘过去,就得到了乘法公式:。
如果我们在所有事件上都加一个额外的条件 作为大前提,这个公式依然成立: 。
现在,我们把 看作 , 看作 , 看作 。所以式子后面的两个概率相乘可以合并:。 继续化简:
证毕!我们就这样一步步严谨地证明了:。
将这个结论代回原式,我们就得到了贝尔曼方程的标准形式:
第二行的展开依据是离散条件期望的定义。对于任意离散随机变量 和条件 :
即:把所有可能的结果 ,乘以在条件 下它发生的概率,再加起来。现在 就是 ,条件 就是 , 是离散随机变量,代入定义:
每一项的直觉:从当前状态 出发,按照策略 行动后,有 的概率跳到下一状态 ,而 的价值是 。把所有可能的下一状态的价值按概率加权,就是"下一步平均能值多少"。
这就是贝尔曼方程最核心的魅力:当前状态的价值,等于即时奖励加上下一个状态价值的期望。
矩阵形式
上面的贝尔曼方程只写了一个状态 的价值。但环境里不止一个状态——CartPole 有无穷多个状态,即使是简单的网格世界也有几十个。每个状态都有一条自己的贝尔曼方程,而且它们互相耦合: 依赖 ,而 的方程里又可能引用回 。这意味着你不能单独解一个方程,必须把所有状态的方程联立起来一起解。
为了把方程写成矩阵,我们先固定一个策略 。固定策略后,动作选择的不确定性可以被合并进两个量:
也就是说, 不是原始环境里的 ,而是“先按策略选动作,再由环境转移”之后得到的状态到状态转移概率。
当状态数量有限( 个)时,这 个联立方程可以写成矩阵形式:
在这里:
- 是一个 的列向量,装满了固定策略 下所有状态的价值。
- 是一个 的列向量,代表固定策略 后每个状态对应的期望即时奖励。
- 是一个 的策略诱导状态转移矩阵,描述了从任意状态出发、按策略行动后跳到另一个状态的概率。
如果你熟悉线性代数,就能立刻看出,这个庞大的方程组其实可以被极致压缩成一行简洁的表达式:
为什么左右两边都是 ,却还能表示“下一状态”的价值?
这里最容易困惑的一点是:前面的单状态公式里,左边看的是当前状态,右边看的是下一状态:
左边是 ,右边却有 。为什么写成矩阵后,左右两边看起来都变成了同一个 ?
关键在于:矩阵形式不是只写一个状态,而是把所有状态的方程同时写出来。为了看清楚,我们把当前状态固定成 。单状态公式就变成:
这里的对应关系是:
| 单状态公式里的符号 | 在矩阵里对应什么 |
|---|---|
| 当前状态 | 第 行,也就是当前正在算 的价值 |
| 下一状态 | 第 列,也就是可能跳到的 |
| 矩阵元素 | |
| 价值向量里的第 个分量 |
所以,右边不是单独的 ,而是:
这列向量只是把所有可能的“下一状态价值”都装起来:
真正决定“当前状态是谁、下一状态按什么概率出现”的,是前面的 。矩阵乘法的第 行展开后是:
这和单状态公式右边的下一状态期望完全一样:
例如第一行对应从 出发:
也就是“从 出发,下一状态价值的概率加权平均”。如果下一步可能到 ,就会取 ;如果可能留在 ,也会取 。所有可能下一状态的价值都在同一列 里,所以右边仍然要用这同一列向量。
换句话说:
- 左边的 :每个当前状态自己的价值。
- 右边的 :提供所有可能下一状态的价值表。
- 前面的 :按“从当前状态会跳到哪里”的概率,把这张价值表加权平均。
- 合起来的 :从每个当前状态出发,下一状态价值的期望。
贝尔曼方程不是说“当前价值等于自己本身”,而是说:
既然这是一个关于 的一元一次线性方程,我们完全可以通过移项和提取公因式来直接解出 :
(注:这里的 是单位矩阵。)
至此,我们得到了固定策略 下贝尔曼方程的解析解(Analytic Solution)。这意味着,只要环境的规则(奖励和转移概率)以及策略 是公开透明的,我们理论上就能直接算出这个策略下所有状态的准确价值。
既然有公式,为什么还要学其他算法?
因为现实很残酷。计算解析解需要对矩阵 求逆,而矩阵求逆的计算复杂度高达 。如果状态空间稍微大一点(比如围棋的 种局面),这辈子都算不完。所以,这种“上帝视角”的直接求解法通常只存在于理论和极简单的玩具环境中。面对复杂问题,我们必须转向动态规划(DP)、蒙特卡洛(MC)或时序差分(TD)等通过不断迭代来逼近真实价值的算法。
动作价值函数 Q(s,a)
前面我们一直在问:“站在这个状态,按策略 继续走,平均能拿多少分?” 这个答案就是 。它很有用,但它还不够用来做选择。原因在于: 只给状态打分,它没有单独回答“某一个动作本身好不好”。
换个更日常的说法:你站在一个路口, 像是在说“这个路口整体还不错”。可是你真正要决定的是:往左走,还是往右走? 只知道“这个路口不错”还不够,你还想知道“先往左走大概能拿多少分,先往右走大概能拿多少分”。CartPole 里也是一样:杆子右倾时,状态价值只告诉你这个局面在当前策略下平均怎么样,却不直接告诉你现在推左好,还是推右好。
所以,我们把问题问得更细一点:在状态 下,如果我先做动作 ,接下来再按照策略 继续行动,未来平均能拿多少分? 这个分数就是 Q 函数(Q-function),也叫动作价值函数。
和 相比, 多看了一个东西:动作 。可以把二者的区别记成:
V 和 Q 的区别
| 对比点 | ||
|---|---|---|
| 问的问题 | 站在状态 ,按策略 走,平均怎么样? | 站在状态 ,先做动作 ,再按策略 走,平均怎么样? |
| 动作怎么处理 | 不单独指定动作,动作由策略 来选 | 先把动作 指定出来 |
| 动作的影响 | 混在策略 的平均结果里 | 被单独拿出来打分 |
| 适合回答 | 这个局面整体好不好? | 这个局面下哪个动作更好? |
所以, 更适合评价“局面整体好不好”, 更适合比较“这个局面下哪个动作更好”。策略改进需要的是后者。
Q 函数的定义是:
这行公式直接定义了 :当前在状态 ,先指定动作 ,之后继续按策略 行动,未来回报 的期望是多少。
V 和 Q 的关系可以先用一句话理解: 是“还没决定动作时,这个状态平均值多少”; 是“已经指定某个动作后,这个选择值多少”。
看一个具体状态 。假设这里只能选两个动作:向右或向左。当前策略 不是固定选一个动作,而是有时向右、有时向左:
| 动作 | 策略选择概率 | 动作价值 | 对 的贡献 |
|---|---|---|---|
| 向右 | |||
| 向左 |
这里的 ,意思是:如果先向右走,之后继续按策略 行动,平均能拿 10 分。,意思是先向左走后平均只能拿 4 分。
但 问的不是“指定某个动作后值多少”,而是“在策略 自己选择动作时,这个状态平均值多少”。所以要把两种动作按策略概率加起来:
因此,这个例子里:
也就是说, 不是重新定义出来的另一个东西,而是把同一个状态下所有可能动作的 按策略概率平均起来:
同样, 也有自己的一步递推关系:先看动作 带来的即时奖励,再看动作之后到达的下一状态价值。
这说明:采取动作 的价值 = 动作 带来的即时奖励 + 动作 导致的下一状态的平均价值。
贝尔曼期望方程
有了 和 的转换关系,我们可以沿着等号继续推下去,写出完整的贝尔曼期望方程。
也就是先写出 和 的关系,再把 的贝尔曼展开式代进去:
这个公式的逻辑非常清晰,分两层展开:
| 层级 | 在平均什么 | 对应公式 |
|---|---|---|
| 动作层 | 策略可能选择不同动作 | |
| 状态层 | 同一个动作可能到达不同下一状态 |
直观例子:宝藏走廊
想象一条 5 格走廊,宝藏在最右边。你只能一直向右走。每走一步要花 1 点体力,所以每一步奖励是 ;到达宝藏后游戏结束,终点价值记为 。
先不要急着看整条路。我们从最容易的位置开始:第 5 格是宝藏,已经结束了,所以它的价值是 0。
| 位置 | 为什么这样算 | 价值 |
|---|---|---|
| 第5格 | 已经到宝藏,不用再走 | |
| 第4格 | 走一步到第5格: | |
| 第3格 | 走一步到第4格: | |
| 第2格 | 走一步到第3格: | |
| 第1格 | 走一步到第2格: |
所以这条走廊的价值表是:
这个例子只想说明一件事:当前位置的价值,可以用“走一步的奖励 + 下一格的价值”算出来。 这就是贝尔曼方程最直观的样子。
贝尔曼最优方程
贝尔曼期望方程回答的是:“如果我按照策略 行动,状态 值多少分?” 但 RL 的终极目标是寻找最好的策略。我们想知道:“如果我每一步都做最优选择,状态 最多值多少分?”
这就引出了最优价值函数 和最优动作价值函数 。 在一个状态下,最优的选择就是挑出那个让 最大的动作:
同样,最优的 依然遵循贝尔曼递推关系(只是未来的状态也被认为会按照最优策略行动):
把 代入 中,我们就得到了贝尔曼最优方程:
对比期望方程和最优方程,唯一的区别在于:求和(平均)变成了求最大值()。
- 期望方程 :按照策略的概率加权平均。
- 最优方程 :抛弃概率,直接挑选价值最大的那个动作。只要解出了最优方程,最优策略也就自然产生了(每次选 即可)。
看一个两步小例子。现在站在状态 ,你有两个动作:向右或向左。先把路径写清楚:
| 当前动作 | 眼前奖励 | 到达哪里 |
|---|---|---|
| 向右 | ||
| 向左 |
真正容易混淆的是“到达下一状态以后,后面怎么走”。普通策略和最优策略在这里不一样:
| 到达的状态 | 后面继续按普通策略 走 | 后面每一步都按最优方式走 |
|---|---|---|
| 平均还能拿 | 最多还能拿 | |
| 平均还能拿 | 最多还能拿 |
这张表的意思是:如果第一步向右到了 ,普通策略 后面可能还会探索、可能不会每次都选最好动作,所以它平均还能拿 ;但如果从 开始每一步都选最好的动作,最多还能拿 。如果第一步向左到了 ,普通策略后面平均还能拿 ;但如果后面也每一步都选最优动作,最多能拿 。
现在再算 就清楚了。先看普通策略 。 的意思是:先做动作 ,之后继续按策略 走。
| 动作 | 奖励 | 下一状态 | 后续按 走的价值 | |
|---|---|---|---|---|
| 向右 | ||||
| 向左 |
如果当前策略 在状态 仍然随机探索,比如 选向右、 选向左,那么它的状态价值就是把这两个 按概率平均:
再看最优情况。 的意思是:先做动作 ,之后每一步都按最优方式走。所以向右之后用的是 的最优后续价值 ,不是普通策略下的 :
| 动作 | 奖励 | 下一状态 | 后续按最优走的价值 | |
|---|---|---|---|---|
| 向右 | ||||
| 向左 |
在当前状态,向右的最优动作价值是 8,向左是 4,所以最优价值直接取最大值:
所以两种计算的区别是:
| 情况 | 用的是哪个 Q | 当前动作怎么处理 | 算出来的 V |
|---|---|---|---|
| 普通策略 | 按策略概率平均: 右、 左 | ||
| 最优价值 | 直接选最大: |
期望方程是在评价“当前策略平均怎么样”,所以用 并按策略概率平均;最优方程是在寻找“从现在到未来都做最佳选择,最多能有多好”,所以用 并取最大值。
价值表与可更新表示
到这里,我们已经知道 的定义,也推导出了贝尔曼方程。它告诉我们:如果策略 固定,真正的价值函数必须满足“眼前奖励 + 下一状态价值”的递推关系。
不过,贝尔曼方程只给出了一条约束,并没有直接给出答案——它说的是“真正的 必须让当前状态和下一状态的价值互相对得上”。这就像写出一组线性方程,还不等于解出了每个未知数;知道价值之间应该怎样递推,也不等于已经知道每个 的具体数值。
要把方程变成算法,我们需要给每个状态分配一个存储位置,初始随便填个数,然后让程序反复修改它、逼近真实值——这就是价值表。
如果状态空间很小,最朴素的做法就是为每个状态保存一个数字,不需要先上神经网络。比如三格走廊里有三个状态 ,我们就准备三行:
| 状态 | 当前估计 | 含义 |
|---|---|---|
| 从 出发的长期回报估计 | ||
| 从 出发的长期回报估计 | ||
| 从终点出发,通常没有后续回报 |
这张“状态 价值估计”的清单,就是本书说的价值表。它不是新的数学对象,而是 的一种表示方式。数学上,它可以看成前面矩阵形式里的价值向量 ;程序里,它可以是 NumPy 数组、Python 字典、哈希表,或者数据库表中的一列。
更一般地说,这属于表格方法(tabular methods)。在强化学习文献中,表格方法指的是:状态和动作数量足够小,可以为每个状态或每个状态-动作对保存一个独立条目,并直接更新这些条目[1]。所以“表”不一定真的画成电子表格;重点是每个状态都有一个单独的存储位置。
这里先把两个容易混淆的东西分开:
- 环境规则表:描述任务本身,记录“从哪里、做什么、到哪里、拿到多少奖励”。在这种小型离散问题里,它就是环境模型的一种表格表示;如果环境有随机性,表里还要写出到不同下一状态的概率。
- 价值表:描述算法当前的判断,记录“从这个状态出发,长期来看大概值多少”。
教材里经常把价值表直接画在状态空间上。下面这张图来自 Sutton 和 Barto 的小型 Gridworld 策略评估例子。这里的 GridWorld 是一个网格环境:格子表示状态,移动方向表示动作,格子里的数字表示当前对 的估计。
左列展示同一个随机策略经过 轮策略评估后的价值表;右列展示如果拿这些价值表去做贪心选择,会得到怎样的策略。
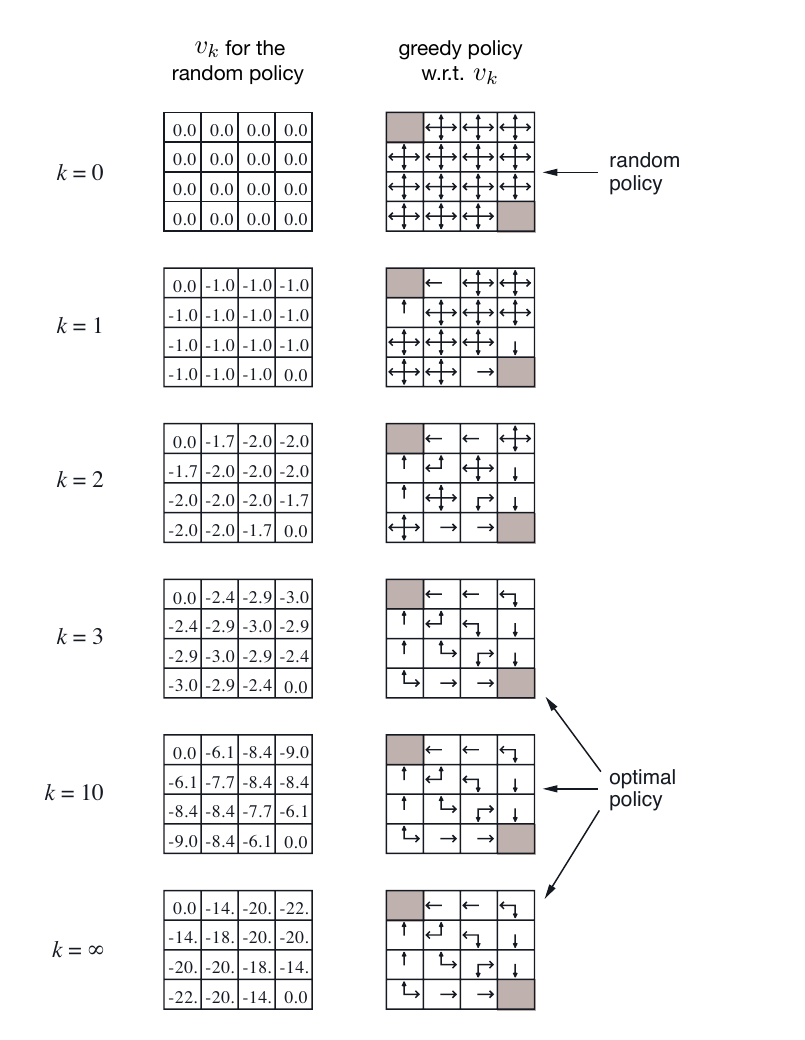
图源:Sutton and Barto, Reinforcement Learning: An Introduction, 2nd ed., Figure 4.1。原书采用 CC BY-NC-ND 2.0 许可。
先只看左列就够了。 时,除了终点,许多格子的价值估计都从 0 开始;迭代几轮以后,靠近终点的位置先发生变化,更远的位置再慢慢被带动。这里的数字不是“走进这一格立刻得到的奖励”,而是“从这一格出发,之后按当前策略走,预期总共会得到多少回报”。
换个最小例子看,考虑一个三格走廊:
环境规则表:记录一步会发生什么
| 当前状态 | 动作 | 下一状态 | 奖励 |
|---|---|---|---|
| 右走 | |||
| 右走 | |||
| 结束 | 无 |
价值表:记录从这里出发以后大概值多少
| 状态 | 当前估计 | 含义 |
|---|---|---|
| 从 出发预计还要走两步 | ||
| 从 出发预计还要走一步 | ||
| 已经到终点,没有后续奖励 |
第一张表来自环境,告诉我们“走一步会发生什么”;在这个走廊例子里转移是确定的,所以每一行只写一个下一状态。如果同一个动作可能通向多个下一状态,环境规则表就要写成带概率的形式,也就是 。第二张表来自算法,保存当前对长期回报的估计。奖励是一步的,价值是长期的;奖励由环境给出,价值需要算法估计。
注意,第二张表里的 是已经算对之后的结果。算法一开始通常不知道这些答案,它可能先把整张表初始化为 0:
| 状态 | 当前估计 |
|---|---|
这里的 0 不是说这些状态真的只值 0 分,而是说“现在还不知道,先用 0 作为初始猜测”。后面的 DP、MC、TD 要做的,就是不断修改右边这一列,让它逐渐接近真实的 。
总结一下:价值表解决的是一个很具体的问题——给抽象的价值函数一个可以反复更新的载体。当状态数量有限且能枚举时,价值表就是最直接的表示;当状态空间巨大或连续时,这张表装不下,后面才需要用函数近似和神经网络来代替。
同一个思想也会自然扩展到动作价值。状态价值表只给每个状态存一个数;动作价值表则给每个“状态-动作对”存一个数,也就是 。第 3.5 节看到的 Q 表,本质上就是把这里的价值表从“每个状态一格”扩展成“每个状态下每个动作一格”。经典 TD 学习可以看成用经验修正状态预测值[2];Q-learning 则是在有限状态、有限动作并反复采样的表格设定下更新动作价值[3]。
从方程到更新规则
上一小节已经说明了价值表的作用:每个状态都在表里有一个位置,但里面的数字一开始只是临时估计。接下来真正要解决的是:这些数字应该怎样一步步变成更接近真实价值的估计?
先把贝尔曼方程换个角度看。前面写它时,它像一个“正确答案必须满足的等式”:
这里左右两边都是真正的 ,所以它是在描述最终答案的关系。但算法一开始没有真正的 ,只有一张临时价值表 。于是自然的做法是:把方程右边当成一个新的目标值,用它来改写旧表。
回答怎么改写之前,先区分两种情况:
- 环境模型已知:这里的“环境模型”,指的是环境规则的数学版本:在状态 做动作 后,会以什么概率到达各个下一状态 ,以及平均会拿到多少奖励。也就是我们清楚转移概率 和奖励 ,可以直接用贝尔曼方程构造更新规则。
- 环境是黑盒:我们不知道这些信息,只能实际走一步,观察到一个奖励和一个下一状态。
先看第一种情况。
对固定策略 ,把旧表记作 。现在我们不再假装已经知道真实的 ,而是拿旧表里的 去估计下一状态的价值:
这一步的含义是:
- 内层的 ,是在算“做动作 后,下一状态价值的期望”。
- 外层的 ,是在按当前策略 对动作再取平均。
- 加上 和折扣因子 后,得到的是“旧表认为状态 现在应该值多少”。
于是更新规则就很直接:
对所有状态都做一次这样的计算,就得到新一轮价值表 。这一步常被称为一次 Bellman backup(贝尔曼备份):用下一状态的旧估计,反过来更新当前状态。
有时我们也不直接替换,而是只往目标值移动一小步:
这里 是学习率。 表示完全采用新目标; 表示只把旧值往目标方向挪 10%。不管是直接替换,还是小步移动,核心思想都一样:贝尔曼方程右边给出目标,价值表负责保存当前估计。
用一个最小的例子来验证这件事。为了不被多个状态分散注意力,先把价值表缩到最小:整张表只有一行,唯一的状态是 。
| 状态 | 当前估计 |
|---|---|
想象你面前只有一台老虎机 A,每一轮按下按钮得到一次奖励,然后又回到同一个状态 。策略固定:永远选择 A。现在只问一个问题:
从这个状态开始,一直玩下去,折扣后的平均总回报是多少?
设定如下:
- 只有一个状态,玩完一轮还是回到同一个状态。
- 永远选择 A 机器。
- A 机器 60% 概率奖励 ,40% 概率奖励 。
- 折扣因子 。
单步期望奖励是:
因为每一轮之后还是同一个状态,所以下一状态价值仍然要查价值表里的同一格,也就是 。根据贝尔曼期望方程,有:
解析解:直接解方程,,得到 。这个 不是单步奖励,而是价值表里状态 这一格最终应该接近的数字,表示“从现在开始一直玩下去,折扣后的平均总回报”。
迭代法:如果我们不想(或者不能)直接解方程,也可以从初始价值表 开始,每轮执行一次贝尔曼更新,把状态 这一格改成新的估计:
先手算前几轮:
| 轮次 | 更新公式 | 表中 的新值 |
|---|---|---|
| 初始 | - | |
| 第 1 轮 | ||
| 第 2 轮 | ||
| 第 3 轮 | ||
| 第 4 轮 | ||
| 第 5 轮 |
每一轮都用“即时期望奖励 + 折扣后的旧价值估计”来得到新的估计。因为这里只有一个状态,所以看起来只是在更新一个数;换成多个状态时,同样的操作就是逐格更新整张价值表。刚开始离 很远,但会一点点靠近。
R = 0.2
gamma = 0.9
V = 0.0
for i in range(50):
V = R + gamma * V
print(round(V, 6))运行结果
1.998698
这就是贝尔曼迭代的基本形状:不是一次把答案算出来,而是反复应用贝尔曼关系,让估计值逐步接近真实价值。在固定策略 下,它对应的是迭代策略评估;如果以后把“按策略平均”换成“对动作取最大值”,就会走向最优控制里的价值迭代。
当环境是黑盒 与 TD 误差
先回到刚才的老虎机例子。那里我们能写出 ,是因为两件事都已经知道:平均每次奖励是 ,按完按钮以后一定回到同一个状态。换句话说,我们知道环境规则,所以可以直接算“平均来说下一步会怎样”。
真实任务通常没有这么方便。智能体不知道每个动作之后会去哪里,也不知道各种结果各有多大概率。它只能真的走一步,看到一个奖励,再看到自己落在哪个状态。TD 误差就是在这种情况下用的:先把它理解成一个对账工具,比较“这一步实际经历给出的目标”和“价值表里原来的估计”差了多少。
如果第一次读到这里还没有完全理解,没有关系。下一节会把 DP、MC、TD 放在一起对比,后面讲具体算法时也会反复回到这个概念。现在先抓住一个区别:模型已知时,我们算的是平均情况;TD 看到的是刚刚发生的这一种情况。
先看模型已知的写法。假设我们知道完整环境规则,就可以写出精确的 Bellman target:
这里的 不是某一次奖励,而是平均奖励; 也不是某一次下一状态,而是到每个下一状态的概率。这个式子的意思是:把所有可能动作、所有可能下一状态都算进去,再按概率平均。
TD 做不到这一点。它没有那张概率表,只知道刚才这一步真实发生了什么:这次拿到的奖励是 ,这次到达的下一状态是 。于是它先用这一条经验拼出一个临时目标:
这里用小写的 和 ,就是在提醒我们:它们不是环境的平均规律,而是刚刚看到的一次结果。这个 target 可能偏高,也可能偏低;但样本多了以后,这些高高低低会逐渐互相抵消。
对比起来就是:
| 方法 | 用到的奖励 | 用到的下一状态 | target 的性质 |
|---|---|---|---|
| 精确 Bellman 更新 | 期望奖励 | 所有可能的 ,按 加权平均 | 精确期望 |
| TD 更新 | 这一次实际奖励 | 这一次实际到达的 | 带噪声的一次样本估计 |
用一组数值看会更清楚。假设在状态 按当前策略行动后,环境有两种可能:
| 下一状态 | 概率 | 这一步奖励 | 当前价值估计 |
|---|---|---|---|
| 70% | |||
| 30% |
令 。如果模型已知,我们会把两种可能都算进去:
这就是精确 Bellman 更新:它像是手里有一张环境说明书,知道从 出发可能发生哪些结果,也知道每种结果的概率,所以可以一次算出平均目标 。
TD 的处境不一样。它没有这张说明书,也不是自己主动按 70% 和 30% 去抽结果。所谓“采样”,只是说:智能体真实走了一步,环境给了它一个结果。如果这个环境本来就有“多数时候到 、少数时候到 ”的规律,那么反复从 出发时,智能体自然会更常看到 ,偶尔看到 。但在每一次更新时,TD 只使用眼前这一条经历。
假设现在价值表里 ,学习率 。
如果这一次真的到了 ,拿到奖励 ,TD 会算:
于是把 往上调一点:
如果另一次真的到了 ,拿到奖励 ,TD 会算:
于是把 往下调一点:
把两种情况放在一起看:
| 这一次真实发生的事 | TD Target | TD 误差 | 更新后 |
|---|---|---|---|
| 到了 ,奖励 | |||
| 到了 ,奖励 |
这里有一个很重要的细节:TD 不保证每一次更新都更接近平均目标。
在这个例子里,精确 Bellman target 是 ,而当前 ,两者差 。如果这一次到了 ,更新后变成 ,确实更接近 ;但如果这一次到了 ,更新后变成 ,反而离 更远了。
这不是矛盾,而是 TD 的正常现象。TD 每次只根据眼前这一条经历修正价值表,所以一次“坏结果”会把估计往下拉,一次“好结果”会把估计往上推。单次更新可能走偏,关键看很多次之后的平均方向。
把两种更新按环境本来的概率合在一起看:
也就是说,如果从 开始,下一次 TD 更新后的“平均位置”是 。它仍然没有直接跳到 ,但已经比 更靠近 了。
同样地,也可以从 TD 误差看:
平均 TD 误差是正的,说明从长期看,当前的 偏低,应该往上调。只是每一次真实经历不一定都朝这个方向走。
这张表要表达的不是“智能体要按 70% 和 30% 去抽样”,而是:TD 每次只看真实发生的一条经历。常发生的结果会更频繁地参与更新,少发生的结果会更少参与更新。很多次更新累积起来,平均方向才会逐渐接近前面那个按概率加权的 Bellman 目标。
这里的 就是时序差分误差(Temporal Difference Error,简称 TD Error)。它衡量的是“一步目标”和“当前估计”之间差了多少:
为什么叫“时序差分”?因为它比较的是时间序列上相邻两个状态之间的预测差异:站在 时有一个旧预测,走到 后又用 给出一个新目标。
它的含义非常直接:
| TD Error | 说明 | 应该怎么调 |
|---|---|---|
| target 比当前估计高,说明低估了 | 上调 | |
| target 比当前估计低,说明高估了 | 下调 | |
| 这次样本下 target 和估计一致 | 基本不用调 |
最简单的更新公式就是:
上面两个分支里的 和 ,就是用这个公式在 时算出来的结果。
这就是 TD 学习的基本动作:每走一步,就用“现实走出来的一步 + 下一状态估计”修正当前状态估计。多次采样之后,单次样本的噪声会被平均掉,价值表就会逐步靠近真正的 。
DP、MC、TD 三种方法分别处理不同的环境条件和信息假设,下一节 经典方法速览:DP、MC 与 TD 会专门对比。
本节总结
这一页公式很多,但主线只有一条:
- 是从状态 出发,按策略 行动的平均长期回报。
- 回报可以递推:。
- 所以价值也可以递推:当前价值等于眼前奖励加下一状态价值。
- 如果策略固定,就得到贝尔曼期望方程。
- 如果每步都选最好的动作,就得到贝尔曼最优方程。
- 在有限状态问题里,可以把 存成价值表,让每个状态都有一个可更新的数字。
- 如果我们只有采样数据,就用 Bellman target 和 TD Error 来一点点修正价值表中的 。
已经能告诉你“这个局面好不好”,但到这里还有两个缺口。
第一个缺口是:如果不知道环境模型,怎么估计 ? 贝尔曼期望方程里有 和 ,但真实任务里我们往往只拿得到一条条采样轨迹。下一节会讲 DP、MC、TD,它们就是三种从模型或数据中估计价值的方法。
第二个缺口是: 不直接告诉你该选哪个动作。 如果 ,你只知道当前局面不错,却不知道该向左、向右,还是保持不动。更直接的办法是给每个动作也打分:
先不用急着展开 。这里只要记住两张表的分工:价值表 给状态打分,动作价值表 给“在状态 下先做动作 ”打分。若环境模型已知,也就是知道每个动作会怎样影响下一状态和奖励,我们可以用 表做一步前瞻来比较动作;若环境模型未知,直接学习 表通常更方便,因为它把每个动作的长期后果直接存了下来。
所以接下来的顺序是:先看 DP、MC 与 TD,解决“怎么估计 ”;再进入动作价值函数,解决“怎么用价值选动作”。
参考文献
Sutton, R. S., & Barto, A. G. (2018). Reinforcement Learning: An Introduction (2nd ed.). MIT Press. 该书 Part I 题为 “Tabular Solution Methods”,第 4 章 Figure 4.1 展示了把状态价值直接写在 Gridworld 格子中的策略评估过程。MIT Press Open Access 页面:https://mitpress.mit.edu/9780262039246/reinforcement-learning/;作者官网 PDF:http://incompleteideas.net/book/RLbook2020.pdf。 ↩︎
Sutton, R. S. (1988). Learning to predict by the methods of temporal differences. Machine Learning, 3(1), 9-44. DOI: https://doi.org/10.1007/BF00115009. ↩︎
Watkins, C. J. C. H., & Dayan, P. (1992). Q-learning. Machine Learning, 8, 279-292. DOI: https://doi.org/10.1007/BF00992698;作者页面:https://www.gatsby.ucl.ac.uk/~dayan/papers/wd92.html. ↩︎