4.3 Hands-On: LunarLander
Goal of this section: start from a reproducible experiment, train DQN on
LunarLander-v3, and use evaluation curves, replay GIFs, and failure diagnosis to answer the only question that matters: what did the policy actually learn?
Code for this section: dqn_gym_sb3.py · export_dqn_curves.py · render_lunarlander_split.py · requirements.txt
4.3.1 Run the LunarLander Training
The previous sections explained the three key components that make DQN work: represent with a network, break sample correlation with replay, and stabilize bootstrapped targets with a target network.
Now we stop adding concepts and instead run a full task end-to-end.
LunarLander is intuitive: a lander falls from the sky, and the agent must use the main engine and side thrusters to land smoothly between two flags. Compared to CartPole, it is closer to a real control problem, because the agent must control position, velocity, angle, fuel use, and the landing condition at the same time.
This experiment can run on CPU. It is slower than CartPole because Box2D physics and replay-buffer updates add overhead, but 100k environment steps is still a reasonable classroom scale.
If you only want to sanity-check that the pipeline runs, reduce --total-timesteps. If you want a stable learning trend, keep 100k or more.
First install the dependencies for this chapter:
pip install -r code/chapter04_dqn/requirements.txtThen run the training:
python code/chapter04_dqn/dqn_gym_sb3.py \
--env-id LunarLander-v3 \
--total-timesteps 100000 \
--learning-rate 0.0005 \
--buffer-size 100000 \
--learning-starts 1000 \
--batch-size 64 \
--target-update-interval 1000 \
--exploration-fraction 0.4 \
--exploration-final-eps 0.05 \
--eval-freq 10000 \
--eval-episodes 5 \
--checkpoint-freq 25000 \
--log-dir output/dqn_gym_runs \
--no-swanlabThe goal is not "make loss small". The goal is to see the deterministic evaluation return rise above a random-policy baseline.
During training, the script evaluates the policy every 10000 environment steps (5 episodes per evaluation), and writes artifacts into:
output/dqn_gym_runs/LunarLander-v3/
The most useful outputs are:
| File / dir | Meaning | Why you care |
|---|---|---|
final_model.zip | final DQN model | render replays, run evaluation |
eval/eval_metrics.csv | periodic evaluation results | check whether returns improve |
eval/eval_curve.png | an evaluation curve image | quick training trend scan |
checkpoints/ | intermediate checkpoints | compare behavior across stages |
To view training metrics in TensorBoard:
tensorboard --logdir output/dqn_gym_runs/LunarLander-v3/tbTo export the local evaluation CSV into images used in the notes:
python code/chapter04_dqn/export_dqn_curves.py --run lunarlander4.3.2 Read Curves First, Then Watch Replays
After training, look at the curve first, then watch the replays.
This order matters:
- curves answer: "is it improving on average?"
- replays answer: "what is it doing, concretely?"
If you only watch a single GIF, it is easy to mistake a lucky success or unlucky failure as the overall algorithm behavior.
Here is an example evaluation record for a 100k-step run:
timesteps mean_reward std_reward
10000 -225.79 23.73
20000 -124.22 11.11
30000 -82.83 31.28
40000 50.68 101.36
50000 25.80 79.58
60000 109.07 130.97
70000 85.07 41.98
80000 -45.77 12.47
90000 -6.32 12.60
100000 253.12 15.37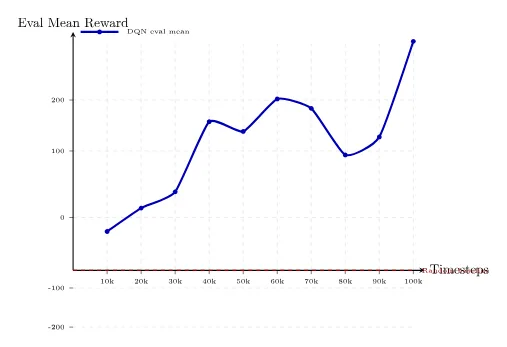
The final evaluation reached 253.12, showing that this training run learned an effective control policy. An independent post-training evaluation scored 175.30 +/- 64.79, indicating the policy has not yet reached "consistently high scores every episode." When reading such curves, you should not only look at the last point, but also consider the mean, variance, and replays together.
To re-render replays:
python code/chapter04_dqn/render_lunarlander_split.py \
--model output/dqn_gym_runs/LunarLander-v3/final_model.zip \
--output-dir output/lunarlander_episodes \
--episodes 3 \
--seeds 9 10019 171 \
--max-steps 1000 \
--max-frames 150 \
--fps 30This script loads the trained final_model.zip, runs the environment with the deterministic policy under the specified seeds, and saves each episode as an independent GIF. --max-steps 1000 limits the environment to at most 1000 steps; --max-frames 150 limits only the number of frames saved to the GIF. That is, the animation will be compressed to under 150 frames, but the step count in parentheses still records the actual environment steps of the original episode.
4.3.3 Criteria for a Successful Landing
Before interpreting replays, we must clarify what counts as success. LunarLander's goal is not simply "the lander eventually touches the ground," but landing smoothly between two flags. A high-quality landing typically satisfies several conditions simultaneously:
- The lander approaches the center of the landing zone, not drifting to the edges or flying out of frame.
- Horizontal and vertical speeds are low enough at contact; it does not slam into the ground.
- The body angle is close to vertical, with angular velocity not increasing further.
- Both legs make normal contact with the ground, not the body or a single leg hitting first.
- The episode terminates normally as a landing, not as a crash, flying out of zone, or timeout truncation.
A single-episode return above 200 usually qualifies as a high-quality successful landing; 100 to 200 indicates the policy is generally effective but has issues with action efficiency, fuel consumption, or stability; significantly below 100 usually means problems with landing position, speed, attitude, or termination mode. At the environment level, "solving" cannot be judged from a single episode; typically you need to see whether the multi-episode average return stably exceeds 200.
The reward is not based solely on the last frame. Gymnasium's LunarLander considers position, velocity, angle, leg contact, fuel consumption, and termination mode comprehensively. Attitude matters of course -- body tilt is penalized -- but the final total return is the cumulative result over the entire trajectory. If the lander progressively approaches the target, reduces speed, and ultimately does not crash during most of the episode, it may still receive a moderate positive return even with a few unattractive corrections in between. Conversely, if attitude control is lost and the lander drifts away from the landing zone or makes a hard landing, the low score does not come from a single penalty item but from multiple factors combining.
First establish a baseline with a random policy. The following code does not train a model; it just has the agent randomly choose actions:
import gymnasium as gym
import numpy as np
env = gym.make("LunarLander-v3")
rng = np.random.default_rng(0)
returns = []
for ep in range(50):
obs, _ = env.reset(seed=ep)
total_reward = 0.0
for step in range(1000):
action = int(rng.integers(env.action_space.n))
obs, reward, terminated, truncated, _ = env.step(action)
total_reward += reward
if terminated or truncated:
break
returns.append(total_reward)
print(f"Random policy mean return: {np.mean(returns):.1f}")
print(f"Best episode: {np.max(returns):.1f}")
print(f"Worst episode: {np.min(returns):.1f}")A typical run yields:
Random policy mean return: -210.2
Best episode: 8.3
Worst episode: -460.8This baseline tells us: if DQN's evaluation return stays around -200 for a long time, we cannot say it has learned to land. Only when the evaluation mean stably leaves the random level and the replays show behavior like decelerating, correcting attitude, and approaching the landing zone can we conclude the policy is forming.
4.3.4 Typical Replays: High Score, Medium, and Failure
Now let us look at three replay segments. During testing, exploration should be disabled; the agent should act purely according to the highest Q-value action. Otherwise, the evaluation results are contaminated with random actions, making it impossible to judge how well the network itself has learned. The three GIFs below come from the same post-training model but use different reset seeds, showing the same policy's performance under different initial perturbations.
Episode 1 (return 313.7, 263 steps) is a high-scoring successful landing. The lander quickly enters a controlled descent state, reduces speed before approaching the ground, and finally contacts the ground within the landing zone. Its highest score comes mainly from good performance across landing position, speed, attitude, and termination mode.
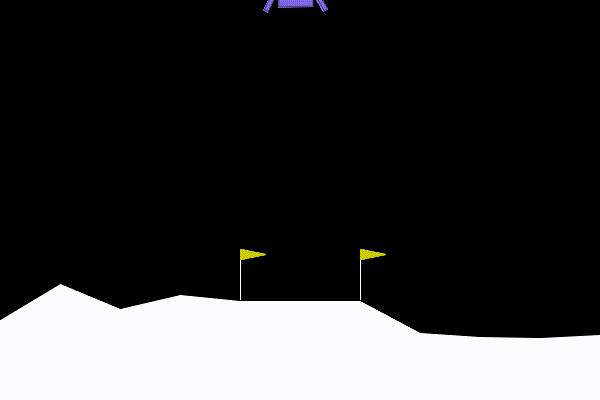
Episode 2 (return 173.2, 676 steps) is a medium success. The lander eventually lands, but the process is longer, requiring repeated attitude and position corrections in between. It is clearly better than failure episodes because it does not crash at the end; but scoring only about 100 points indicates issues with action efficiency, fuel consumption, and stability compared to the high-scoring example.
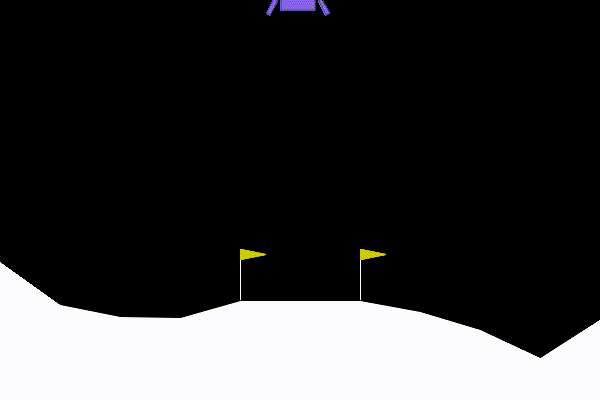
Episode 3 (return 5.9, 104 steps) is a clear failure. After deviating from the stable descent path, the lander does not recover attitude; both legs do not make normal contact on landing. This is closer to "drifting out and crashing/hard landing" rather than hovering until the maximum step timeout.
These three replays illustrate exactly why you cannot judge from a single episode. Episode 1 proves the policy can complete a high-quality landing; Episode 2 shows the same policy may still use a longer path and more corrections for a medium-quality landing; Episode 3 reminds us that training to 100k steps does not mean the policy is stable for all initial states. Reading curves and replays together, the conclusion should be: this DQN has clearly learned LunarLander's control patterns, but it is not yet a fully robust landing controller.
4.3.5 States, Actions, and Training Fluctuations
LunarLander's state is an 8-dimensional continuous vector; actions are 4 discrete choices. The 8 state components can be understood as:
| Component | Meaning | What the agent needs to judge |
|---|---|---|
x, y | Position relative to landing zone | How far from center, how much altitude remains? |
vx, vy | Horizontal and vertical velocity | Is it descending too fast, drifting sideways? |
angle | Body tilt angle | Is attitude deviating from vertical? |
angular | Angular velocity | Is the body spinning faster and faster? |
left_leg | Whether left leg contacts ground | Has partial landing occurred? |
right_leg | Whether right leg contacts ground | Have both legs made contact? |
The 4 actions are: no fire, left side thruster, main engine, right side thruster. The main engine can reduce descent speed but consumes fuel and may push the lander back up; side thrusters can correct angle but in the wrong direction or timing can make things worse.
Therefore, DQN does not learn a single rule in this task, but a set of action preferences that vary with state. Early in training, the network's Q-values for the 4 actions have no reliable meaning; epsilon-greedy causes the agent to explore extensively. After passing learning_starts=1000, the replay buffer starts providing training samples, and the network gradually learns rough patterns: the main engine is more valuable when descending too fast; side thrusters are more valuable when the body is tilted; firing randomly near the ground may actually reduce return.
The curve is not monotonic for this reason. DQN's Q-value estimates affect action selection, which in turn determines the data collected subsequently. At some point the policy has just learned to decelerate, but in the next phase it may hover or drift away due to overusing the main engine; a checkpoint that performs well on 5 evaluation episodes does not mean it is stable for all initial states. "Getting better" in reinforcement learning is often not a smooth line, but a trend that gradually forms through oscillation among exploration, replay, and function approximation.
This is exactly where experience replay and the target network truly matter. Experience replay ensures each update draws from different phases of descent and landing; the target network keeps next-state value estimates stable long enough that the Q-network can actually move toward them. Without these two mechanisms, a task like LunarLander with physical continuity can easily be pulled along by the most recent string of failure trajectories.
4.3.6 Common Failures and a Debugging Order
If your run performs poorly, do not start by concluding "DQN cannot solve LunarLander". DQN is a reasonable baseline for this task, but it is sensitive to experiment setup. Diagnose in order.
First, make sure evaluation disables exploration. Training uses epsilon-greedy exploration; evaluation should act greedily. If evaluation still samples random actions, returns will look unstable and artificially low.
Second, confirm you have passed learning_starts. If learning_starts=1000, the first 1000 steps primarily fill the buffer. Short runs may end before meaningful learning happens.
Third, confirm you have enough evaluation episodes. LunarLander has high variance due to randomized initial conditions. One-episode evaluation is misleading; use 5 to 10 at minimum for trend judgement.
Fourth, then tune hyperparameters. Common starting points:
| Parameter | This section | If wrong |
|---|---|---|
learning_rate | 0.0005 | too high: Q-values oscillate; too low: learning is slow |
buffer_size | 100000 | too small: dominated by recent experience; too large: stale experience persists |
learning_starts | 1000 | too early: learns from tiny buffer; too late: short run shows no learning |
target_update_interval | 1000 | too frequent: target network ineffective; too rare: targets too stale |
exploration_fraction | 0.4 | too fast: premature exploitation; too slow: prolonged randomness |
eval_episodes | 5 | too small: noisy trends |
Also note the maximum step limit. Gymnasium's LunarLander episodes can be truncated at 1000 steps; if the lander never terminates normally, it is truncated. A timeout is not a success; it merely means the policy failed to complete the task decisively. The failure example in this section is not a timeout case: Episode 3 ends at 104 steps, and the problem is crashing or hard landing after deviating from the stable descent path, not hovering to the maximum duration.
4.3.7 Why LunarLander Is the First Full DQN Lab
We can now explain why this chapter uses LunarLander as the first end-to-end DQN lab: CartPole saturates too easily, making DQN look easier than it is; MountainCar has sparse rewards and a minimal DQN baseline can get stuck in the failure zone for a long time; LunarLander sits in the middle: still low-dimensional vectors and discrete actions, but a richer reward structure and more realistic control dynamics.
In other words, LunarLander is not just a visually appealing game environment, but an appropriate pedagogical bridge. It makes DQN's components tangible rather than abstract nouns: experience replay corresponds to mixing landing experience from different phases; the target network corresponds to a relatively stable learning target; epsilon-greedy corresponds to early trial-and-error with engine and thruster actions.
Next: The DQN family
Section Summary
LunarLander-v3is a suitable continuation for this chapter's DQN hands-on: low-dimensional continuous states, discrete actions, and a richer reward structure than CartPole.- The training entry point is
code/chapter04_dqn/dqn_gym_sb3.py; curve export usesexport_dqn_curves.py; replay GIFs userender_lunarlander_split.py. - During evaluation, first check whether multi-episode average return has departed from the random baseline, then use replays to verify whether the policy actually completes deceleration, attitude correction, and landing zone control.
- A single episode above
200usually indicates a high-quality successful landing;100to200is mostly a medium success; significantly below100requires examining replays to determine the failure cause. - Curve fluctuation in LunarLander is normal; to judge whether training is effective, consider the mean, variance, checkpoints, and replays across different seeds simultaneously.