B.1 RL Training Infrastructure: Rollout, Buffers, and Distributed Systems
Earlier chapters emphasized algorithms: how to write policy gradients, how PPO/GRPO update, and where rewards come from. Once you move into industrial training, there is an additional layer: your training samples are not a fixed dataset sitting on disk. They are produced continuously by the current policy during training.
Supervised learning is like working from a fixed problem set: the program just reads problems batch by batch. RL is different. After some training, the policy changes; once the policy changes, the distribution of collected data changes as well.
In LLM RL, a language model generates multiple candidate answers for a math problem, and then a rule/verifier/judge scores them. In CartPole, the policy outputs an action and the environment returns the next observation and reward. These tasks look different on the surface, but the underlying system question is the same:
Who produces training samples? What unit do samples flow in? Can the training side consume fast enough? Can data from old policies still be used?
That is exactly what RL sampling infrastructure must solve.
This page merges "sampling infrastructure," "asynchronous training architecture," and "distributed parallelism" into one storyline: first we build a producer-buffer-consumer pipeline with weight feedback; then we enter LLM RL and discuss vLLM/SGLang and OpenRLHF/veRL/slime across the inference/rollout layer and training/orchestration layer; then we use non-LLM RL as a contrast for Gymnasium, IMPALA, Sample Factory, and Isaac Gym; finally we discuss how async training and multi-GPU parallelism make this pipeline run at scale. This is the training-system substrate that most later RL engineering reuses. When the model starts calling tools, reading/writing files, running code, or maintaining multi-turn environment state, the additional sandbox, trajectory storage, and tool-scheduling problems are covered in B.2 Agentic RL Infrastructure.
Scope of This Page: The Training Substrate First
B.1 focuses on how samples are produced, queued, consumed, and how weights flow back, and on how to split models across GPUs. It assumes the sampling side is primarily a text-generation engine, a simulator, or actor workers.
| Expanded Here | Only Touched Briefly |
|---|---|
| token generation for LLM rollout engines, KV cache, tail latency | sandboxing for code execution, file I/O, and network access for agents |
| orchestration frameworks like OpenRLHF/veRL/slime | multi-turn tool-call trajectories, dialog trees, environment snapshots |
| async rollout/training, buffers, policy versioning, staleness | intra-trajectory tool waits and within-batch pipelining |
| distributed training and memory optimizations: FSDP/ZeRO/TP/PP/EP | environment interfaces and reproducibility for web/code/multimodal agents |
A simple rule of thumb: if the task is still "generate a completion, then score it with a verifier/reward", focus on B.1. If actions leave the GPU to call tools, modify files, run tests, browse the web, or maintain multi-turn state, that is B.2.
The Data Pipeline of RL Training
The most basic RL dataflow is:
producer generates samples → buffer stores samples → consumer trains the model → new weights flow back to the producerIn LLM RL, producers are usually rollout engines like vLLM/SGLang; consumers are trainers inside orchestration frameworks like OpenRLHF/veRL/slime. In non-LLM RL, producers are environments/simulators/actors; consumers are learners. The system diagrams throughout this page all revolve around this "produce, buffer, consume, feedback" pipeline.
Let's align terminology first:
| Term | Meaning |
|---|---|
| policy | the current model or decision rule being trained; it chooses actions or generates completions |
| environment | the external system that accepts actions and returns observations/rewards (game, simulator, task environment) |
| observation / action / reward | observation is environment state, action is the policy's choice, reward is the score from the environment |
| transition | one interaction step record: state, action, reward, and next state |
| episode | a full interaction from reset to termination |
| trajectory / rollout | a sequence of samples; in non-LLM RL, an environment trajectory; in LLM RL, prompt-to-completion generation |
| token / completion | tokens are the unit of generation; a completion is the full response to a prompt |
| Actor / rollout worker | the worker that produces samples by interacting with the environment or calling the model |
| Learner / Trainer | the worker that consumes samples and updates model parameters |
| Buffer / Queue | where samples are stored temporarily; deeper queues may improve throughput but samples may be staler |
| weight sync | after the Trainer updates the model, new weights are sent back to the sampling side |
| on-policy / off-policy | on-policy means samples come from the current policy; off-policy means samples come from older policies |
| KV cache | intermediate computation results saved during LLM generation, used to avoid recomputing earlier tokens |
Two Paths: LLM RL vs Non-LLM RL
RL sampling infrastructure splits into two categories by training target: LLM RL and Non-LLM RL. The data sources, data units, and primary bottlenecks differ between the two.
| Category | Data Source | Data Unit | Primary Bottleneck |
|---|---|---|---|
| LLM RL | language model generates completions, reward/verifier/judge scores | tokens, completions, rollout batches | token-by-token generation, KV cache, tail output, weight sync, stale samples |
| Non-LLM RL | environment or simulator returns observation/reward | transitions, episodes, trajectories | environment step, simulation throughput, Actor/Learner synchronization |
Each category has two responsibility layers: the inference/sampling layer produces trainable samples, and the training/orchestration layer consumes samples, updates parameters, and syncs new weights back to the sampling side. In LLM RL the first bottleneck is usually completion generation, so the inference/rollout layer comes first; the training/orchestration layer then strings together rollout, reward, buffer, and weight sync.
| Category | Inference/Sampling Tools | Training/Orchestration Tools |
|---|---|---|
| LLM RL | vLLM, SGLang | OpenRLHF, veRL, slime |
| Non-LLM RL | Gymnasium VectorEnv, IMPALA Actor, Sample Factory rollout worker, Isaac Gym simulator | IMPALA Learner, Sample Factory Learner |
LLM RL's inference layer revolves around rollout engines — vLLM and SGLang handle high-throughput token generation; the training/orchestration layer revolves around post-training frameworks — OpenRLHF, veRL, and slime orchestrate rollout, reward, buffer, trainer, and weight sync. Non-LLM RL's sampling layer revolves around environment interfaces, actors, rollout workers, and simulators; the training/orchestration layer usually has a Learner consuming trajectories and updating policies.
Why the Sampling Side Sets the System Ceiling
Supervised learning has a static training loop:
Dataset → DataLoader → Forward → Backward → UpdateRL has a dynamic training loop:
Policy sampling → Environment/generator produces feedback → Collect trajectories → Compute rewards → Update policy → Re-sample with new policyThe DataLoader here is an online system. It does not just read data — it must run the policy, advance the environment, generate text, compute rewards, record trajectories, handle episode termination, and hand data to the learner.
Therefore, RL system throughput is determined by three rates:
- sampling-side data production rate:
steps/s,tokens/s,samples/s - training-side data consumption rate: batch size, backprop, parallelism strategy
- feedback-side reward return rate: rule verification, Reward Model, LLM-as-Judge, code execution, environment step
Any one becoming a bottleneck limits the entire training pipeline. The bottleneck locations for each category are:
| Category | Inference/Sampling Bottleneck | Training/Orchestration Bottleneck | Sample Freshness Issue |
|---|---|---|---|
| LLM RL | token-by-token decode, KV cache, tail completion, batch scheduling | reward/verifier, PPO/GRPO training, buffer, weight sync | rollout batch may be generated by old actor; deeper async queues → more off-policy |
| Non-LLM RL | environment step(), physics simulation, Actor count, CPU/GPU data transfer | Learner backprop, Actor/Learner sync, parameter broadcast | Actors sample with stale policies, trajectories may produce policy lag |
Part I: LLM RL — Solve Inference First, Then Orchestration
LLM RL training data comes from the current language model generating completions for prompts. After the model outputs completions, rules, Reward Models, LLM-as-Judge, or verifiers provide rewards. At this point, the core of the "sampling infrastructure" is no longer environment steps, but text rollout, reward computation, weight synchronization, and policy version management.
LLM RL infrastructure consists of two types of systems:
| Subcategory | Responsibility | Representatives |
|---|---|---|
| Inference/rollout tools | high-throughput token generation, KV cache management, batch scheduling, weight loading | vLLM, SGLang |
| Training/orchestration tools | orchestrate rollout, reward, training, buffer, weight sync, and parallelism | OpenRLHF, veRL, slime |
1.1 The Inference/Rollout Layer: An Inference Engine Inside the Training Loop
In LLM RL, the rollout engine is a "batch generator" oriented toward training. It is not a general-purpose online inference service. Online services serve user requests; RL post-training rollout engines serve the training loop. It must not only generate text but also execute sampling strategies, record policy versions, coordinate with reward computation, receive new weights, and deliver trainable data to downstream buffers and trainers.
The basic data flow of one LLM RL step:
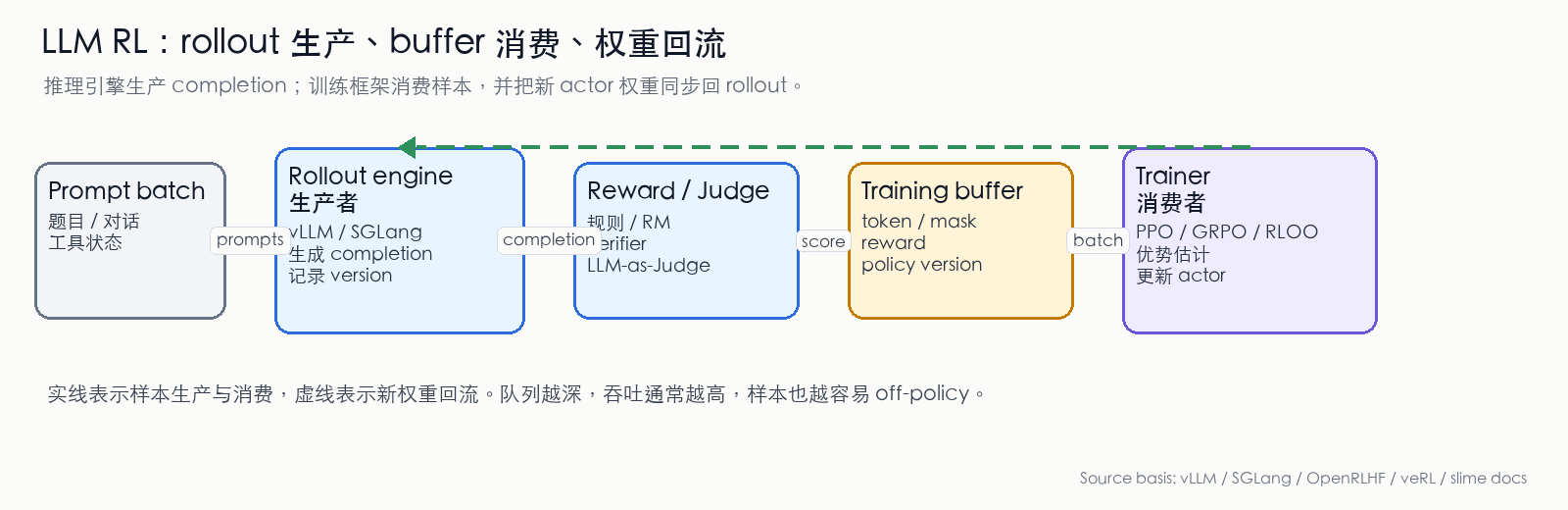
Figure 1: LLM RL producer/consumer pipeline. The rollout engine produces completions, reward/verifier/judge produces scores, the training buffer organizes tokens, masks, rewards, and policy versions into batches, and the trainer consumes batches and syncs new actor weights back to the rollout engine. Solid lines indicate sample flow; dashed lines indicate weight feedback. (Compiled from vLLM, SGLang, OpenRLHF, veRL, slime documentation [1][2][3][4][5])
The rollout engine must produce at least:
- token ids: the completion tokenized into ids; training loss needs per-token alignment
- attention_mask / response_mask: marking which positions are prompt, response, padding, or truncation
- finish_reason: recording whether the completion ended normally, was truncated, hit a stop token, or was interrupted by a tool call
- sampling metadata: recording temperature, top-p, top-k, seed, and how many completions per prompt
- policy_version: recording which actor version generated this batch of samples
- optional logprob: recording the model's probability for each token. Some systems extract old logprobs from the inference side; others recompute on the training side to reduce inconsistencies from inference/training kernel differences
Online inference services deliver answers; LLM RL rollout engines deliver trainable trajectory samples.
1.2 Limits of the Online-Serving Paradigm
LLM serving refers to online chat or API services for users. LLM serving and LLM RL rollout both rely on inference engines, but their optimization targets differ:
| Dimension | Online Serving | RL Rollout Engine |
|---|---|---|
| Primary target | user latency and SLA | trainable samples per unit time |
| Request pattern | user requests arrive randomly | trainer sends batches of prompts, often multiple completions per prompt |
| Output length | constrained by product interaction | often long reasoning, long code, long CoT, tail samples |
| State management | usually fixed weights | weights are periodically updated, version management needed |
| Correctness | text result correctness suffices | tokens, masks, logprobs, version numbers must align with training |
| Scheduling | p50/p99 latency | tokens/s, samples/s, tail latency, GPU utilization |
GRPO's common num_generations=8 or 16 generates multiple completions per prompt. Math, code, and long-reasoning tasks have highly variable completion lengths: short samples finish quickly while long ones continue decoding. A training batch usually must wait for the slowest completion; a few exceptionally long completions create "tail latency" that directly slows training.
1.3 Prefill, Decode, KV Cache, and Tail Output
LLM generation can be decomposed into two phases:
- Prefill: process the prompt and compute the initial KV cache. This is more compute-intensive; long prompts increase cost.
- Decode: generate tokens autoregressively. This is more memory-bandwidth and scheduling intensive; longer outputs are more susceptible to tail latency.
Intuitively, prefill is like reading the entire problem and noting intermediate results; decode is like writing the answer token by token based on those results.
RL rollout amplifies both problems:
- Shared prefixes are common. Prompts in the same batch may share system prompts, few-shot examples, or problem templates; the same prompt may be sampled multiple times. Prefix cache hit rate directly affects prefill cost.
- Heavy-tailed output length distribution. Most completions may be a few hundred tokens; a few will generate thousands. The longest sample in a batch determines when the full rollout batch can be delivered.
- KV cache grows with concurrency and context length. KV cache is the intermediate computation saved during generation; its size depends on model layers, head count, sequence length, and concurrent requests. When memory is insufficient, throughput drops sharply, potentially triggering preemption or recomputation.
- Weights are updated. Serving can use a fixed checkpoint long-term; RL rollout must frequently receive new weights from the trainer. Updating too slowly leaves rollout GPUs idle; updating too fast may cause in-flight samples to span policy versions.
vLLM's PagedAttention manages KV cache in blocks, avoiding the need to reserve large contiguous memory for each request, thereby improving memory utilization and throughput during dynamic batching [6][7].
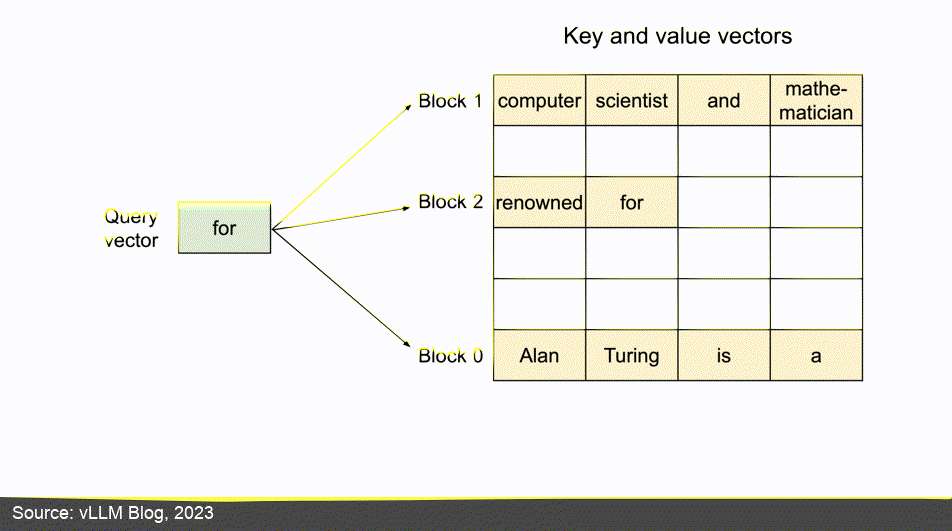
Figure 2: PagedAttention animation from the vLLM blog. For LLM RL, rollout throughput depends heavily on KV cache management, continuous batching, and long-output scheduling. (Source: vLLM blog [7:1])
SGLang also treats these as core capabilities: RadixAttention for reusing shared prefixes, router/gateway for distributing requests across inference instances, PD disaggregation for splitting prefill and decode onto different execution resources, and RL system interfaces directly addressing weight updates, pause generation, deterministic inference, and other training-scene requirements [2:1][8][9].
1.4 Core Responsibilities of the Rollout Layer
In LLM RL systems, the rollout engine typically handles five categories of responsibility.
First, batch generation. The component must organize large numbers of prompts into high-throughput requests while supporting multiple completions per prompt. The key question is not whether it can call generate, but how to organize prefill, decode, padding, stop conditions, and batch scheduling.
Second, KV cache management. PagedAttention, prefix caching, RadixAttention, chunked prefill, KV eviction — all directly impact tokens/s and memory usage. For RL, prompt templates and multi-sample generation create many reusable prefixes, so cache hit rate is not a marginal optimization.
Third, tail latency control. RL rollout typically cannot return results until a complete training-usable batch is formed. A few exceptionally long completions slow down the entire batch delivery. Engineering solutions include max length, early stop, bucket scheduling, partial batch return, and async queues.
Fourth, weight lifecycle. After the Trainer updates the actor, the rollout engine must receive new weights. This process may involve tensor parallelism formats, FSDP/Megatron sharding formats, LoRA adapters, inter-GPU communication, sleep/wake, and pause/resume generation. vLLM documentation specifically discusses RLHF scenarios alongside sleep mode and weight sync [1:1][10].
Fifth, versioning and consistency. Whether the rollout side generates samples with the old or new policy must be recorded. Under strict on-policy, old data is discarded; under async training, old data can be retained but staleness, importance sampling, KL, or clipped weights must control risk. The "Asynchronous Training Architecture" section below continues this discussion.
1.5 vLLM and SGLang
vLLM and SGLang can both serve as LLM RL rollout engines, but their engineering emphases differ:
| System | Standout Capabilities | Significance in RL Rollout |
|---|---|---|
| vLLM | PagedAttention, continuous batching, parallel sampling, prefix caching, sleep mode, RLHF integration | General-purpose high-throughput rollout engine, easy integration with OpenRLHF/veRL |
| SGLang | RadixAttention, structured generation, router/gateway, PD disaggregation, RL system interfaces | Suited for long contexts, multi-turn interaction, MoE, SGLang-native post-training systems |
OpenRLHF commonly uses Ray + vLLM + DeepSpeed; veRL supports vLLM, SGLang, and HF Transformers as rollout backends; slime uses SGLang as its native rollout layer. In this layering, vLLM/SGLang sit at the generation engine layer, while TRL/OpenRLHF/veRL/slime sit at the training orchestration layer.
1.6 The Training/Orchestration Layer: TRL as a Single-Machine Research Prototype
TRL (Transformer Reinforcement Learning) is an RL training library within the HuggingFace ecosystem [11]. The DPO (Chapter 2) and GRPO (Chapter 9) experiments in earlier chapters all use TRL. Its positioning differs from the three frameworks above: TRL is not a distributed orchestration system — it does not do Ray scheduling, does not separate rollout engine and trainer into separate processes, and does not handle cross-GPU weight sync. It wraps DPO/PPO/GRPO/REINFORCE++ training loops into DPOTrainer, GRPOTrainer, and other Trainer classes that run on a single machine or a small number of GPUs [11:1].
This means TRL's internal data flow is much simpler than OpenRLHF/veRL/slime:
model generates completions → reward/verifier scores → Trainer computes loss → backprop updates parametersNo independent rollout workers, no cross-process buffer queues, no weight sync. Generation and training happen within the same Python process. The advantage is low barrier to entry — earlier chapters demonstrated this. The cost is that throughput is limited by a single machine, and generation/training scheduling cannot be decoupled.
TRL fits two scenarios: (1) algorithm research and rapid validation — modifying reward functions, trying new loss designs, verifying data quality; (2) small-scale production — single-GPU or few-GPU SFT/DPO/GRPO training. When training requires multi-node scale, or rollout and training need to be scheduled separately, you enter the domain of OpenRLHF/veRL/slime.
ms-swift (ModelScope Swift) has a similar positioning to TRL but targets the domestic model ecosystem [12]. It packages the full SFT/DPO/GRPO/RLHF pipeline into a CLI tool, loading models and datasets directly from ModelScope Hub, with one-click deployment to ModelScope inference services. Suited for scenarios where you want an out-of-the-box pipeline without assembling it yourself.
| Framework | Ecosystem | Distributed Capability | Scale | Typical Use |
|---|---|---|---|---|
| TRL | HuggingFace | single machine / accelerate | single ~ few GPUs | algorithm research, rapid validation, teaching |
| ms-swift | ModelScope | single machine / few GPUs | single ~ few GPUs | out-of-the-box pipeline, domestic model support |
| OpenRLHF | Ray + vLLM | Ray cluster | multi-node multi-GPU | mid-scale PPO/GRPO production training |
| veRL | composable backends | FSDP / Megatron | multi-node multi-GPU | customizable training flow, swappable rollout backends |
| slime | Megatron | Megatron + SGLang | large-scale clusters | large-scale MoE, tail rollout optimization |
| Miles | Megatron | Megatron + SGLang | large-scale clusters | enterprise-grade long-running MoE post-training |
1.7 The Training/Orchestration Layer: OpenRLHF, veRL, slime
OpenRLHF, veRL, and slime sit at the same system layer. They typically call vLLM or SGLang for rollout, but are not themselves pure inference engines. They are more like pipeline controllers, responsible for stringing together generation, scoring, training, sample caching, and weight sync:
- Rollout workers: batch-generate completions, connecting to vLLM, SGLang, or other inference backends
- Reward/Judge workers: score completions from rules, reward models, LLM-as-Judge, or code execution
- Training workers: compute loss via PPO/GRPO/RLOO/REINFORCE++, perform backprop and parameter updates
- Buffer/Queue: cache samples, record policy versions, control old data ratio
- Weight sync: sync the trainer's new weights to the rollout side
PPO/GRPO in algorithm formulas mainly appear as loss, advantage estimation, and constraint terms. In real systems, post-training framework differences primarily show up on four planes:
| Plane | Problem to Solve |
|---|---|
| Rollout plane | which inference engine, how to batch/truncate/retry, concurrency, handle tail latency |
| Reward plane | whether rewards come from rules, RM, Judge, or verifier; whether scoring becomes a bottleneck |
| Training plane | DeepSpeed, FSDP, Megatron-LM, or custom training stack for large-model training |
| Data/Weight plane | how samples enter the queue, streaming vs batch, weight sync, old sample handling |
The HybridFlow paper's framework comparison table compares DeepSpeed-Chat, OpenRLHF, NeMo-Aligner, and HybridFlow across these dimensions: parallelism, actor weights, model placement, and execution pattern [13].
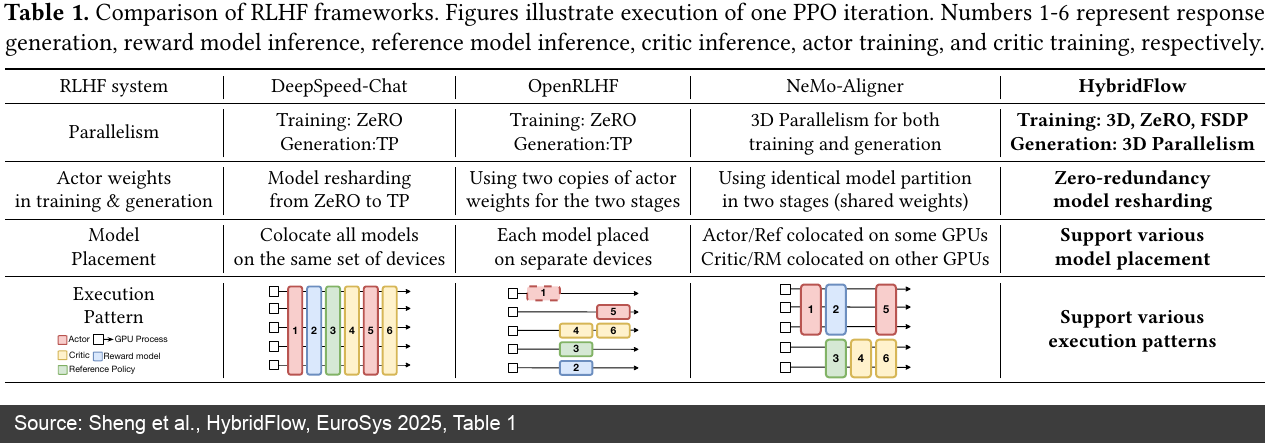
Figure 3: HybridFlow paper's comparison of RLHF framework execution patterns. OpenRLHF uses separate devices and two copies of actor weights to enable generation/training parallelism; HybridFlow further emphasizes zero-redundancy model resharding and flexible placement. (Source: HybridFlow paper [13:1])
1.8 OpenRLHF: Ray + vLLM + DeepSpeed
OpenRLHF's technical report and README describe it as a Ray + vLLM distributed architecture: Ray schedules different workers across machines and GPUs; vLLM handles rollout inference; DeepSpeed trains and serves Actor/Critic/Reward/Reference models; Transformers handles model format and state bridging; NCCL/CUDA IPC provides fast GPU communication [14][3:1].
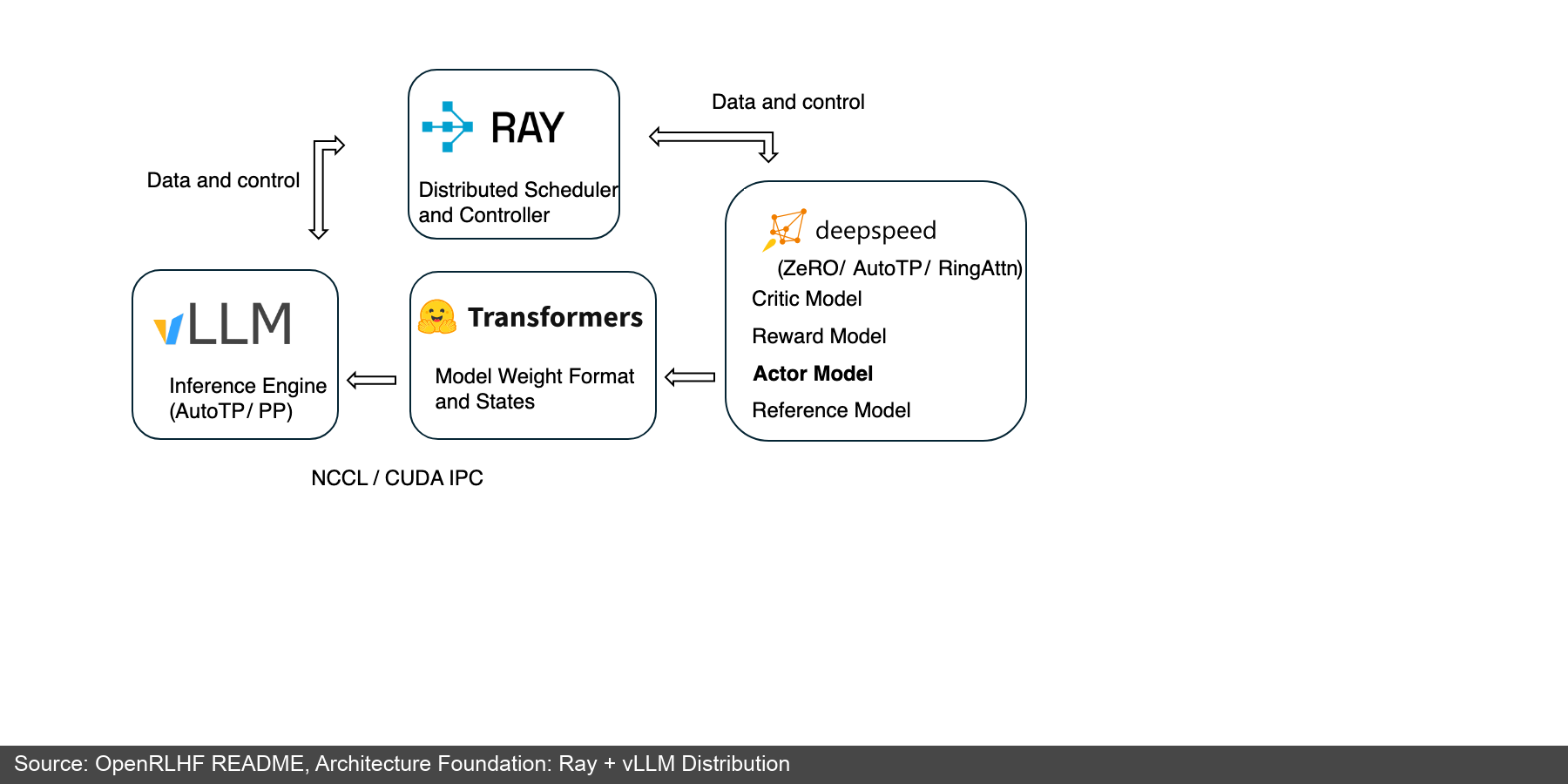
Figure 4: OpenRLHF README's Ray + vLLM architecture diagram. It shows the typical decomposition of LLM RL: scheduling layer, inference engine, training engine, model weight format, inter-GPU communication. (Source: OpenRLHF README [3:2])
Key boundaries shown in Figure 4:
- Ray schedules Actor, Critic, Reward, Reference, and vLLM engine components to different GPUs
- vLLM handles high-throughput generation as the rollout core
- DeepSpeed handles training-side memory optimization and distributed backprop
- Transformers bridges weight formats and model states
- NCCL/CUDA IPC handles weight sync and inter-GPU transfer
OpenRLHF's practical value lies in making several common deployment patterns explicit parameters. "Colocated" means generation and training share the same GPU set; "async" means generation and training run concurrently.
| Mode | Typical Parameters | Engineering Meaning | Risk |
|---|---|---|---|
| Hybrid Engine / colocated | --train.colocate_all, --vllm.enable_sleep | same GPU set switches between generation and training, saves GPUs | strictly serial, throughput limited by rollout tail |
| Async Training | --train.async_enable, --train.async_queue_size | rollout and training run concurrently, larger queue → higher throughput | deeper queue → more off-policy samples |
| Async + Partial Rollout | --train.partial_rollout_enable | uses vLLM pause/resume, weight sync doesn't fully block generation | in-flight samples may mix old/new weights |
These three modes correspond to the core tension in industrial training: saving GPUs, strict on-policy, and high throughput are hard to satisfy simultaneously. OpenRLHF tends to expose these choices to the user. During research, colocated mode ensures stability; for throughput optimization, enable async; if you can tolerate more complex off-policy correction, try partial rollout with importance sampling correction [15].
1.9 veRL: HybridFlow Execution Flow
veRL is the open-source implementation of the HybridFlow paper. It emphasizes single-controller orchestration, composable model engines/rollout engines, and queue-based decoupling of rollout and training [13:2][4:1].
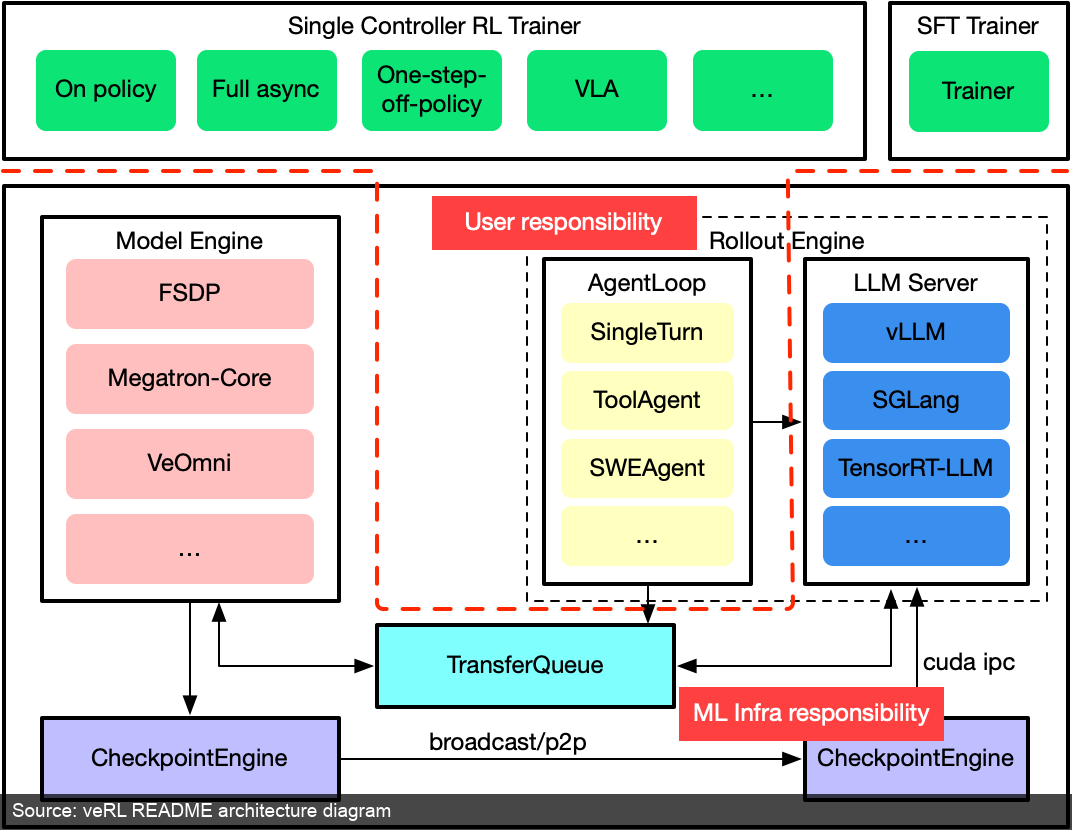
Figure 5: veRL README's architecture diagram. TransferQueue, Rollout Engine, Model Engine, and CheckpointEngine correspond to the data flow, inference flow, training flow, and weight sync of the LLM RL system. (Source: veRL README [4:2])
Figure 5 shows veRL's decomposition of the LLM RL execution flow. The Rollout engine may connect to vLLM, SGLang, or TensorRT-LLM; the Model engine may connect to FSDP, Megatron-Core, or other training backends; TransferQueue streams generated samples to the training side; CheckpointEngine saves and broadcasts new weights.
veRL's key contribution is abstracting RL training into a set of composable workers. The README emphasizes the hybrid-controller programming model, flexible device mapping, and modular integration with FSDP/FSDP2, Megatron-LM, vLLM, SGLang, and HF Transformers [4:3]. These names can first be understood as two types of components: training backends handle splitting large models across GPUs for training; rollout backends handle high-throughput text generation. This means:
- Training side can choose FSDP or Megatron-style sharding based on model size
- Inference side can choose vLLM, SGLang, or HF Transformers based on scenario
- Rollout, reference logprob, actor update, critic update steps can be composed under a unified controller
- Async, off-policy, multimodal/robotics experimental directions can plug into the same execution flow
Compared to OpenRLHF's focus as a "Ray + vLLM + DeepSpeed engineering RLHF framework," veRL emphasizes abstraction of the RL training flow and backend composability. It suits scenarios requiring training flow modification, rollout engine replacement, custom reward insertion, VLM/multi-turn/tool calling support, or new algorithm research.
1.10 slime: Megatron + SGLang + Data Buffer
slime is more focused on large-scale RL scaling. Its README summarizes its core capabilities as: high-performance training via Megatron + SGLang, and flexible rollout through custom data generation interfaces and a server-based engine [5:1]. Megatron primarily serves the training side; SGLang primarily serves the rollout side.
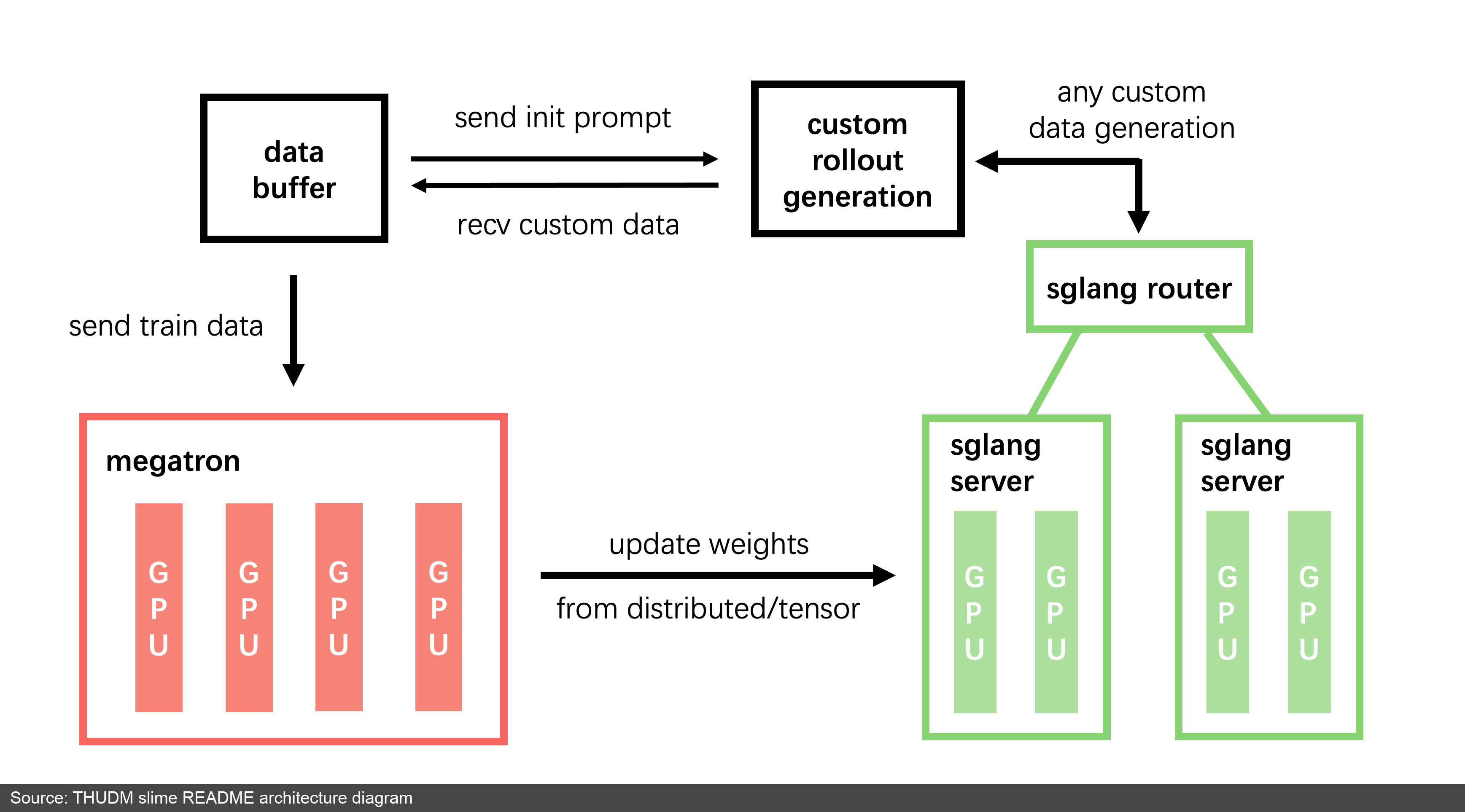
Figure 6: slime README's architecture diagram. Training side is Megatron, inference side is SGLang server/router, with a data buffer managing prompts, rollout data, and custom generation logic. (Source: slime README [5:2])
slime's system structure is relatively clear:
- training (Megatron): reads training data from the Data Buffer, syncs new parameters to the rollout module after training
- rollout (SGLang + router): generates new data including reward/verifier output, writes back to Data Buffer
- data buffer: manages prompt initialization, custom data, and rollout generation methods
Compared to OpenRLHF/veRL, slime more explicitly uses SGLang as the native inference layer rather than a general-purpose replaceable plugin. slime documentation emphasizes: SGLang is launched internally in server mode, SGLang parameters can be passed directly via --sglang-*, and --debug-rollout-only is provided for debugging rollout performance alone [16]. The training side also supports Megatron parameter passthrough covering TP/PP/EP/CP model parallelism strategies, with --debug-train-only for debugging the training portion [16:1].
The downstream projects listed in slime's README also indicate its positioning: APRIL specifically optimizes rollout tail latency; TritonForge, RLVE, P1, and others use slime for code generation, verifiable environments, and physics reasoning tasks [5:3]. These projects reuse the same substrate discussed on this page: rollout engine, training backend, data buffer, weight sync, and parallel training. How Agentic RL frameworks add sandboxing, multi-turn trajectories, and tool scheduling on top of this substrate is covered in B.2.
slime's release notes also discuss typical systems engineering problems: RL inference latency cannot be solved simply by adding GPUs, because training still waits for the longest completion to finish decoding; oversized inference batches introduce off-policy issues [17]. Therefore, slime focuses on KV cache space, MoE fp8 rollout, DeepEP, Megatron offload, NCCL group rebuild, and other low-level optimizations. These problems go beyond single-machine PPO loops and are fundamental infrastructure issues for industrial RL training systems.
Miles (radixark/miles) is slime's enterprise-grade fork, maintained by the LMSYS team [18]. It inherits slime's Megatron + SGLang architecture, targeting stable and controllable RL for large-scale MoE post-training scenarios. While slime focuses on pushing the limits of algorithm and system performance, Miles adds fault tolerance, operational monitoring, and production-grade reliability for long-running training tasks lasting days or even weeks [19].
1.11 LLM RL Summary
LLM RL system boundaries revolve around "text rollout." Data comes from the current language model, rewards come from rules/models/verifiers, and the training system must also manage weight sync and policy versions.
| Category | System | Positioning | Data Unit | Primary Bottleneck |
|---|---|---|---|---|
| Inference/rollout tools | vLLM | general LLM rollout engine | token / completion | KV cache, continuous batching, tail decode, sleep/weight sync |
| Inference/rollout tools | SGLang | rollout engine for complex generation & RL systems | token / completion / structured output | RadixAttention, router, PD disaggregation, weight updates |
| Training/orchestration tools | OpenRLHF | Ray + vLLM + DeepSpeed post-training framework | rollout batch | PPO/GRPO/RLOO training orchestration, colocated/async tradeoffs |
| Training/orchestration tools | veRL | composable-backend RL training flow framework | sample stream / rollout batch | rollout, model engine, TransferQueue, checkpoint composition |
| Training/orchestration tools | Seer | extreme synchronization: in-context learning eliminates tail | rollout batch | divided rollout, context-aware scheduling, speculative decode |
| Training/orchestration tools | slime | SGLang-native + Megatron post-training framework | data buffer / rollout batch | large-scale rollout, Megatron parallelism, MoE fp8 rollout & DeepEP |
| Training/orchestration tools | Miles | slime enterprise fork, large-scale MoE post-training | data buffer / rollout batch | long-running training fault tolerance, operational monitoring, production reliability |
| Training/orchestration tools | ms-swift | ModelScope ecosystem all-in-one training framework | rollout batch | SFT/DPO/GRPO/RLHF pipeline, out-of-the-box, domestic model hub integration |
| Training/orchestration tools | TRL | single-machine research prototype, HuggingFace ecosystem | rollout batch | DPO/PPO/GRPO Trainer wrapping, rapid validation, no distributed orchestration |
Part II: Non-LLM RL — Environment Interaction and Simulation Throughput
Non-LLM RL covers traditional control, games, robotics simulation, and similar tasks. Training data comes from the environment: the policy outputs actions, the environment returns the next observation, reward, and terminated/truncated flags. The core goal of the sampling infrastructure is to maximize environment interaction throughput and minimize waiting between CPU environments, GPU policy networks, and the learner.
The inference/sampling layer produces trajectories by advancing environments, and the training/orchestration layer consumes trajectories and updates policies. Gymnasium and Isaac Gym are typical systems in the sampling layer; IMPALA and Sample Factory demonstrate how the inference/sampling layer and training/orchestration layer are decoupled.
2.1 The Inference/Sampling Layer: Gymnasium VectorEnv
Gymnasium is first and foremost an environment interface, not a distributed training framework. It defines basic interaction patterns: reset(), step(action), observation, reward, terminated/truncated. CartPole, LunarLander, Atari, and MuJoCo experiments typically start from this interface.
When a single environment is too slow, the GPU spends most of its time waiting for CPU env.step(). Gymnasium therefore provides synchronous and asynchronous vector environments, wrapping multiple environment instances into one batched environment [20].
from gymnasium.vector import SyncVectorEnv, AsyncVectorEnv
envs = SyncVectorEnv([lambda: gym.make("CartPole-v1") for _ in range(8)])
obs, info = envs.reset() # shape: (8, obs_dim)
actions = policy(obs) # one inference for 8 actions
obs, rewards, terms, truncs, infos = envs.step(actions)Here obs is short for observation, terms and truncs indicate which environments have ended. The vector environment combines 8 environments into one batch, letting the policy network process 8 observations at once.
| Type | Principle | Use Case |
|---|---|---|
SyncVectorEnv | sequential step in main process | lightweight environments like CartPole, some Atari experiments |
AsyncVectorEnv | parallel step across processes | environments where step itself is heavy, like physics simulation |
Engineering focus at this stage is on correctly handling batch shapes, episode resets, termination conditions, and logging. All components typically run within a single machine.
2.2 Inference/Sampling + Training/Orchestration: IMPALA
When tasks expand to Atari, DeepMind Lab, ViZDoom, MuJoCo, or robotics simulation, the bottleneck shifts from "single environment too slow" to "how to sustain trajectory production across many environments." Simply adding learner-side GPUs usually cannot improve overall throughput because the learner still lacks sufficient new data.
Distributed RL systems typically split roles into Actor and Learner: Actors interact with the environment and generate trajectories; the Learner consumes trajectories and updates parameters.
IMPALA is the representative of this approach. Many Actors generate trajectories in parallel and send data to a central Learner; Actors no longer send gradients back to a parameter server but instead send full trajectories for the Learner to continuously consume batches on the GPU. Since Actors may sample with slightly stale policies, IMPALA uses V-trace for off-policy correction — a "stale sample correction" method that reduces bias from policy lag [21]. This established the basic shape for many subsequent systems: decouple sampling and training, prioritize throughput, then handle data staleness algorithmically.
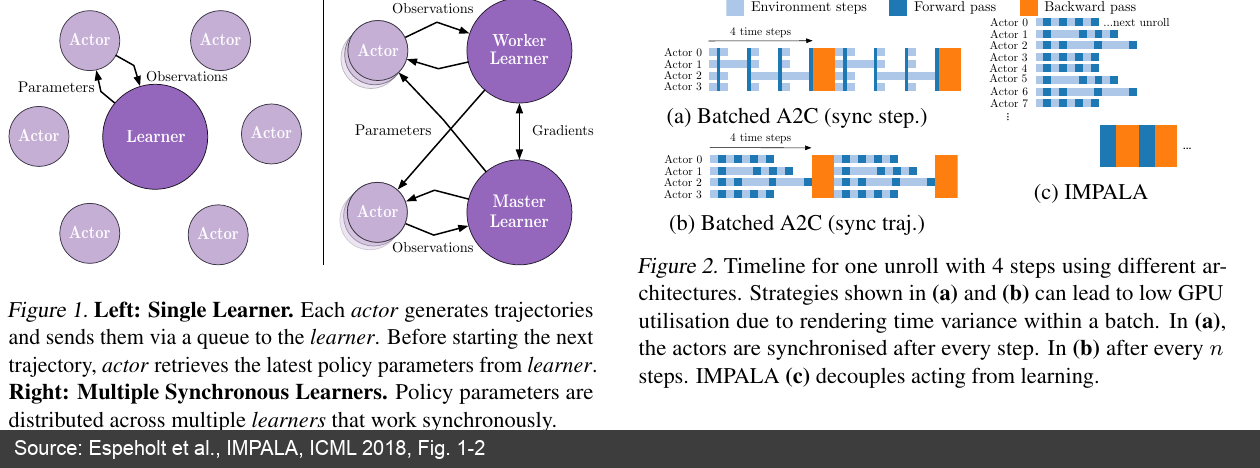
Figure 7: IMPALA paper's Actor-Learner architecture and timeline. Left: Actors only generate trajectories and pull parameters from the Learner. Right: IMPALA does not wait for all Actors to synchronize, but decouples acting and learning. (Source: IMPALA paper [21:1])
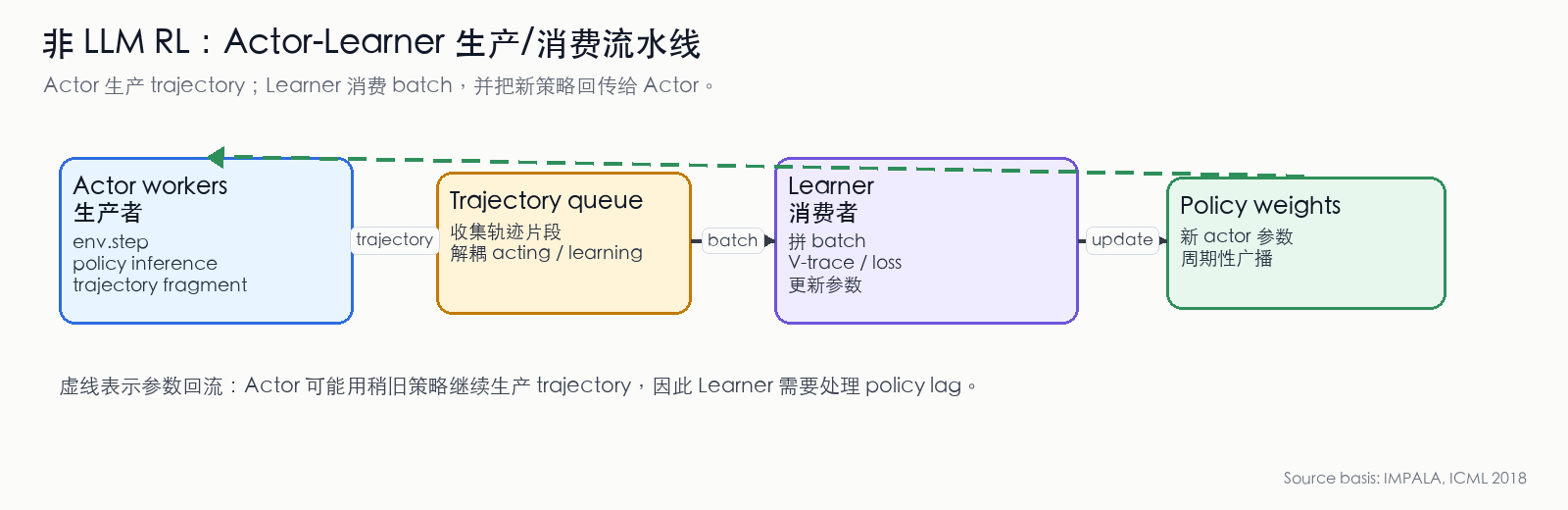
Figure 8: IMPALA Actor-Learner architecture from the producer/consumer perspective. Actors are trajectory producers; Learner is the batch consumer. Dashed lines indicate new policy weights flowing back to Actors. This feedback may not be strictly synchronized with sampling, creating policy lag. (Compiled from IMPALA paper [21:2])
2.3 Inference/Sampling + Training/Orchestration: Sample Factory
Sample Factory pushes Actor-Learner decoupling toward single-machine high-throughput implementation: async Actor-Learner, shared memory, batched inference, and less Python overhead enable Atari/3D control tasks at 100K+ fps [22]. It does not just add more environments but splits work into specialized components:
- Rollout worker: CPU-side only runs the environment, does not hold a policy copy, so it can be heavily parallelized
- Policy worker: GPU-side batched action generation, merging observations into larger forward batches
- Learner: consumes full trajectories for backprop, writes new parameters to shared GPU memory
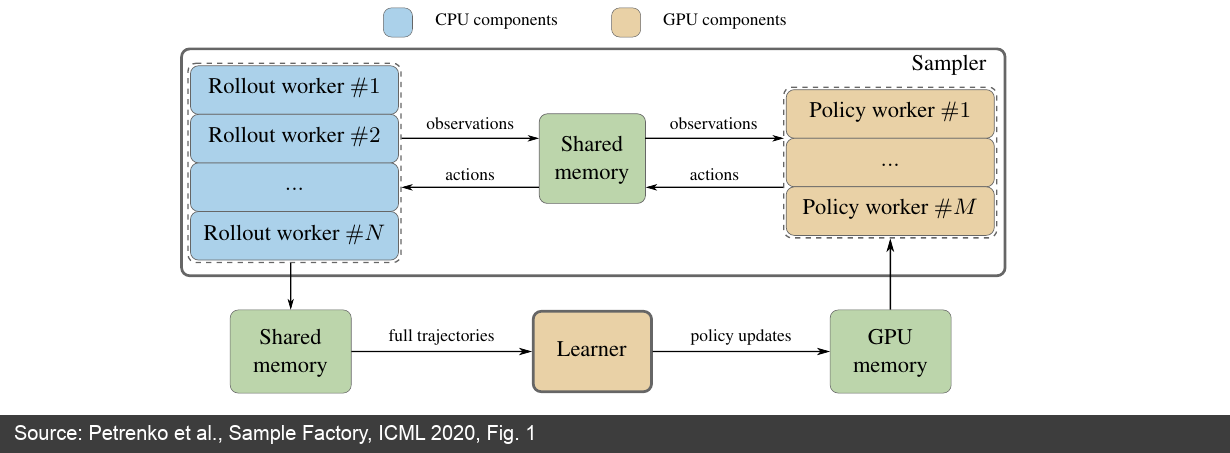
Figure 9: Sample Factory paper's system architecture. It separates environment simulation, policy forward pass, and backward training into independent components, using FIFO queues and shared memory to reduce communication costs. (Source: Sample Factory paper [22:1])
The architecture's key point is data flow: observations go from rollout workers via shared memory to policy workers; actions go back to rollout workers; complete trajectories enter the learner; updated parameters enter GPU memory and are picked up by policy workers.
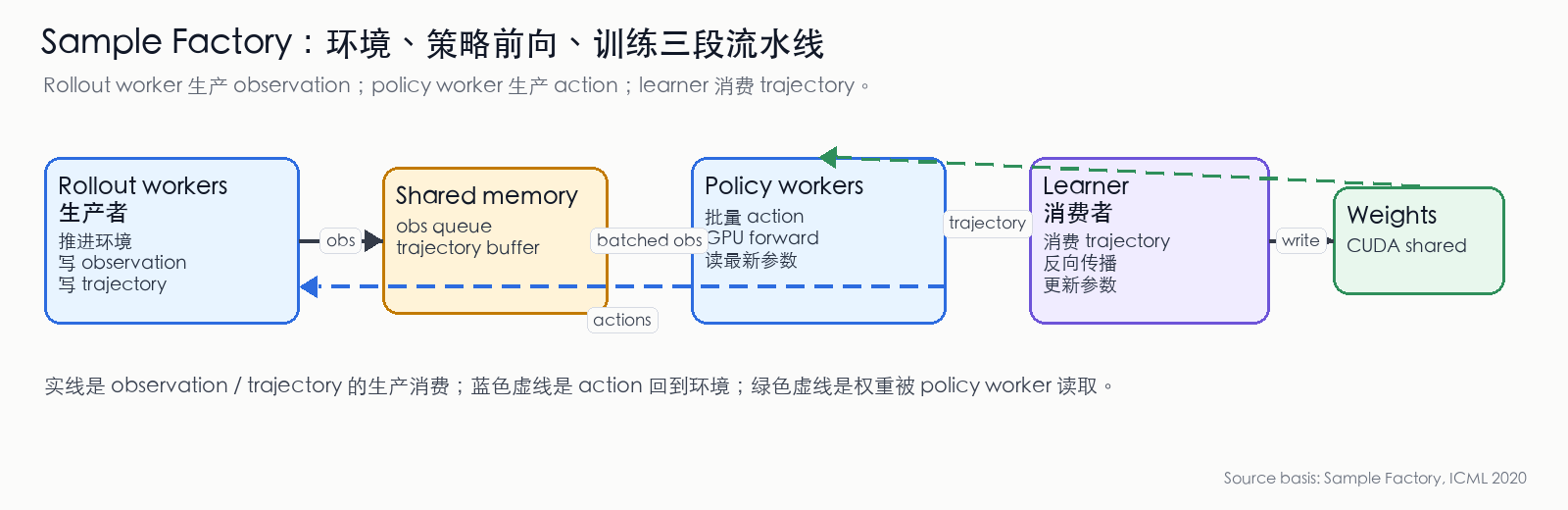
Figure 10: Sample Factory producer/consumer pipeline. Rollout workers produce observations and trajectories; policy workers consume observations and produce actions; the Learner consumes trajectories and updates shared weights. Shared memory lets the three pipeline stages minimize inter-process copies. (Compiled from Sample Factory paper [22:2])
2.4 The Inference/Sampling Layer: Isaac Gym GPU Simulation
Robotics and physics control tasks encounter another bottleneck: physics simulation itself is heavy, and traditional CPU physics engines require frequent state transfers to the GPU for policy inference.
NVIDIA Isaac Gym moves physics simulation directly onto the GPU, with tens of thousands of parallel environments. The core benefit is eliminating the step-by-step data movement between CPU physics engines and GPU policy networks [23].
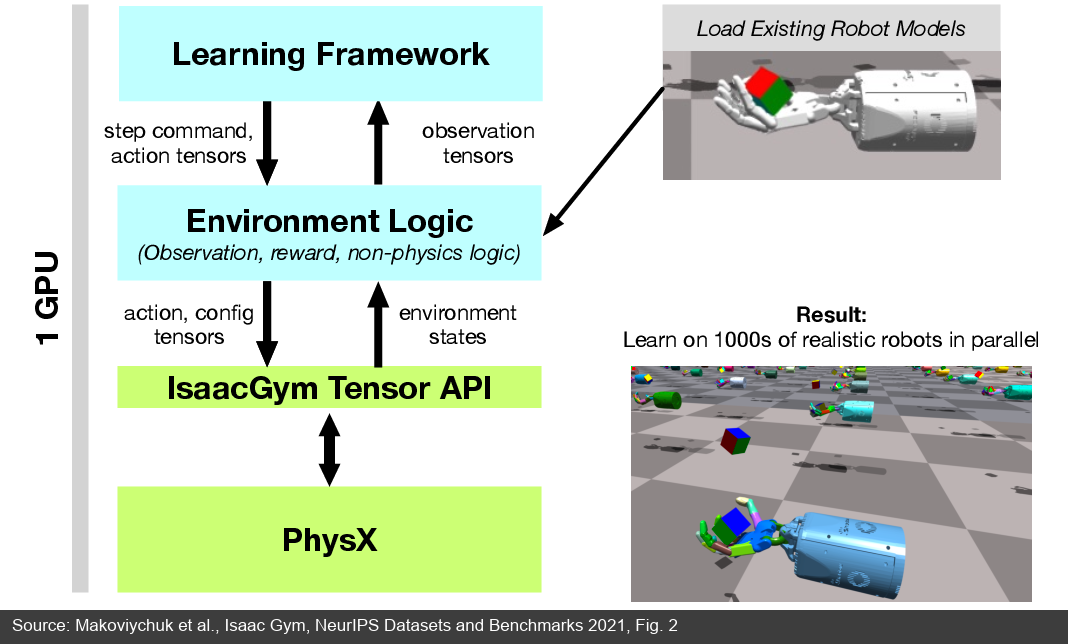
Figure 11: Isaac Gym paper's GPU pipeline. Learning Framework, Environment Logic, IsaacGym Tensor API, and PhysX all exchange states, actions, and configurations around GPU tensors, avoiding CPU/GPU copies at every step. (Source: Isaac Gym paper [23:1])
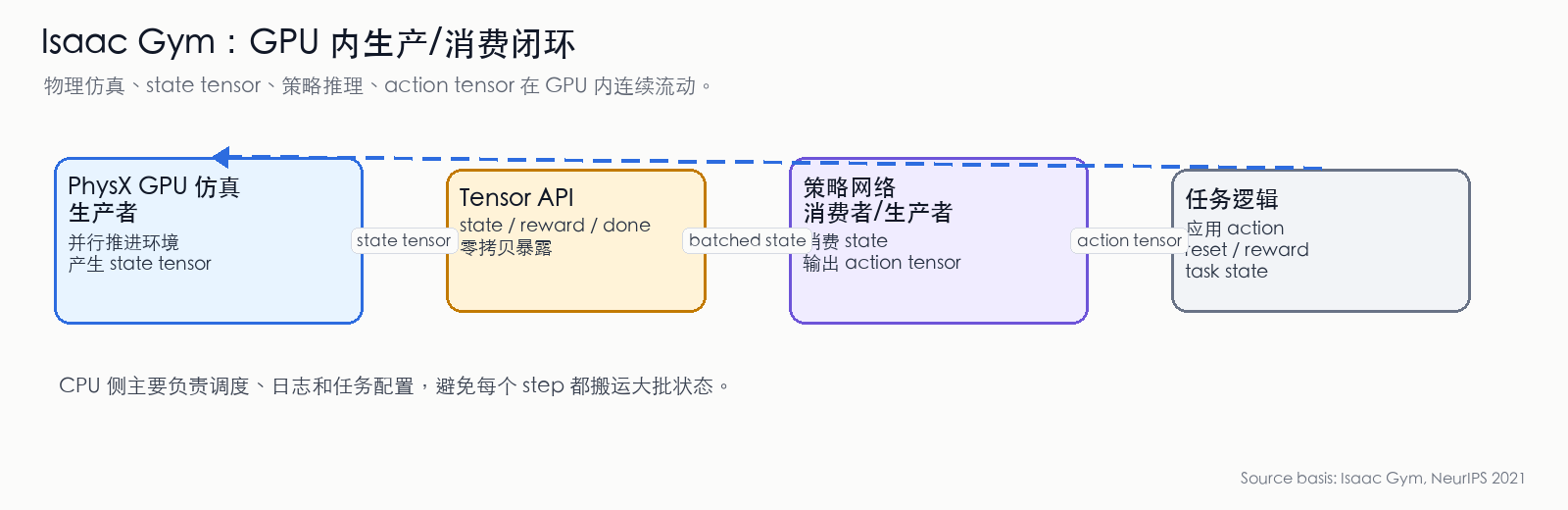
Figure 12: Isaac Gym's GPU-internal producer/consumer loop. PhysX produces state tensors on GPU; the policy network directly consumes state tensors and produces action tensors; task logic writes actions back to the next round of physics simulation. The core benefit is avoiding CPU/GPU round-trip copies at every step. (Compiled from Isaac Gym paper [23:2])
Traditional: CPU physics engine × 64 environments → GPU policy inference
Isaac Gym: GPU physics simulation × 4096 environments + GPU policy inference| Comparison | CPU Parallel (MuJoCo × 64) | GPU Parallel (Isaac Gym × 4096) |
|---|---|---|
| Sampling speed | ~10K fps | ~1M fps |
| Data transfer | CPU→GPU per step | zero-copy |
| Use case | low-DoF robots | humanoids, dexterous hands |
2.5 Non-LLM RL Summary
Non-LLM RL system boundaries revolve around "environment interaction." Data comes from external environments or simulators, with transitions, episodes, and trajectories as the main data units.
| Category | System | Positioning | Data Unit | Primary Bottleneck |
|---|---|---|---|---|
| Inference/sampling tools | Gymnasium VectorEnv | environment interface / single-machine batched env | transition / episode | Python env.step() |
| Inference/sampling tools | IMPALA Actor | distributed environment interaction component | trajectory | Actor count, network transfer, policy lag |
| Training/orchestration tools | IMPALA Learner | centralized training component | trajectory batch | Learner throughput, parameter broadcast, V-trace correction |
| Inference/sampling tools | Sample Factory rollout worker / policy worker | single-machine high-throughput sampling components | trajectory buffer | CPU rollout, GPU policy worker, shared memory |
| Training/orchestration tools | Sample Factory Learner | single-machine async training component | trajectory batch | learner/sampling mutual wait, parameter sync |
| Inference/sampling tools | Isaac Gym | GPU physics simulation platform | GPU tensor state | CPU/GPU data transfer and physics simulation throughput |
Part III: Asynchronous Training Architecture — Overlap Generation and Training
LLM RL training has a core tension: generation is slow, training is relatively fast, and serializing both wastes GPU time. In GRPO, for example, one training step often requires the model to generate hundreds of completions before computing loss and updating parameters. During generation, training GPUs wait; during training, rollout GPUs wait. Longer outputs make this more pronounced.
A typical GRPO step looks like:
① Generate rollout batch ← inference slow, training side waits
② Compute reward / advantage
③ Backprop and update actor ← training fast, inference side waits
④ Sync new weights back to rolloutThree common deployment patterns:
| Mode | Resource Organization | Overlap? | Use Case |
|---|---|---|---|
| Synchronous | one GPU group, generation and training serial | No | learning, small experiments, strict on-policy |
| Colocated | one GPU group, rollout and training alternate | No, but faster switching | medium-scale training with limited GPU budget |
| Decoupled | rollout GPUs and training GPUs separated, connected by buffer | Yes | large-scale production training |
Synchronous mode is easiest to understand: generate, then train, then generate. Simple but poor throughput. Colocated mode switches the same GPU group between inference format and training format (e.g., FSDP sharding → vLLM tensor parallel → back to training format). Saves GPUs but generation and training still cannot truly run simultaneously.
Decoupled mode is the standard for large-scale RL training: rollout GPUs continuously generate samples, writing tokens, masks, rewards, and policy versions into a buffer; training GPUs continuously consume samples from the buffer; weight updates are synced back to the rollout engine.
Rollout GPU: [gen b0] [gen b1] [gen b2] [gen b3] ...
↓ ↓ ↓
Buffer: [b0] [b1] [b2]
↓ ↓ ↓
Training GPU: [train b0] [train b1] [train b2] ...
↑ ↑
weight sync weight syncDecoupled mode introduces two new problems: how to sync new weights to the inference side and whether data from old policies can still be used.
Weight Synchronization
After the Trainer updates the actor, the rollout engine must receive new weights. Different systems use different transfer methods:
| Method | Transfer Content | Characteristics |
|---|---|---|
| NCCL full broadcast | all parameters | general-purpose, common in multi-GPU clusters |
| Packed transfer | all parameters | reduces small-tensor transfer overhead |
| Direct GPU memory transfer | all parameters | depends on high-bandwidth interconnect |
| Sync only LoRA adapter | adapter parameters | small data volume, suited for LoRA post-training |
| Write checkpoint then load | file | simple cross-node, but slow |
If training LoRA adapters, weight sync is much lighter: the rollout side only needs to receive adapters, not the full base model. This is why LoRA + async training are often used together.
When weights arrive, the rollout engine may be in the middle of generating long completions. Common handling approaches: don't interrupt generation, wait for current requests to finish before switching, immediately interrupt and restart requests, or wait for the full batch to complete before switching. More aggressive → higher throughput; more conservative → better consistency.
Handling Old Data
Deeper async queues mean training-side data is more likely from older policies. Strict on-policy training discards these samples; throughput-priority systems allow some lag, using both engineering and algorithmic constraints to manage risk.
| Approach | Method | Tradeoff |
|---|---|---|
| Version filtering | each sample records policy version, discard if too old | simple and reliable, but wastes samples |
| Limit buffer depth | keep queue to a few batches max | use system constraints to bound staleness |
| Importance sampling correction | weight samples by old/new policy probability ratio | no wasted data, but implementation more complex |
| Combined | queue depth + version filter + truncated correction | common in production systems |
A commonly used safety boundary in practice: first make the buffer shallow to avoid overly stale samples; then record policy versions; finally use KL, clipping, or truncated importance sampling at the algorithm layer to suppress large deviations. Async training is not simply "the more async the better" — it balances throughput, sample freshness, and training stability [24].
Part IV: Distributed Parallelism and Memory Optimization — Split the Model Across GPUs
RL post-training is more memory-intensive than ordinary fine-tuning. PPO may simultaneously involve Actor, Critic, Reference, and Reward Model; even though GRPO drops the Critic, it still needs actor, reference, rollout engine, and reward/verifier components working together. When the model doesn't fit on one GPU, computation and state must be split across multiple GPUs.
Four Parallelism Strategies
| Strategy | What Is Split | Communication Characteristics | Applicable Scope |
|---|---|---|---|
| DP (Data Parallelism) | different GPUs handle different batches | gradient AllReduce | model fits on one GPU |
| TP (Tensor Parallelism) | split matrices within layers | communication every forward/backward | within-node multi-GPU, requires NVLink |
| PP (Pipeline Parallelism) | split model by layers | activations pass between adjacent stages | cross-node large models |
| EP (Expert Parallelism) | MoE experts distributed across GPUs | tokens routed to experts | MoE models |
70B dense models commonly use DP + TP + PP hybrid parallelism; MoE models also need EP. TP is better suited for within-node high-bandwidth interconnects; PP for cross-node layer-wise splitting; DP for scaling batch size and synchronizing gradients.
FSDP and ZeRO
The parallelism strategies above answer "how to compute"; FSDP and ZeRO answer "how to save memory for states."
FSDP (Fully Sharded Data Parallel) shards parameters, gradients, and optimizer states across GPUs, temporarily gathering them during computation. It is PyTorch's native solution with good generality.
DeepSpeed ZeRO also shards in stages across optimizer states, gradients, and parameters. ZeRO-3 can shard all three state types, minimizing memory pressure but maximizing communication overhead.
In practice, FSDP/ZeRO are commonly combined with TP/PP: the former saves state memory; the latter splits model computation.
Mixed Precision and RL-Specific Challenges
| Precision | Use | Recommendation |
|---|---|---|
| BF16 | training | preferred; usually more stable than FP16 |
| FP16 | training | usable, but watch for overflow and loss scaling |
| FP32 | critical compute | stable but slow, high memory |
| FP8 | frontier training/inference | high performance, but stability and framework support need verification |
| INT8/INT4 | inference | suited for serving/rollout compression; not for direct training precision |
RL training has additional challenges because rollout and training phases have different resource demands: rollout is inference-intensive, especially affected by KV cache, tail output, and concurrency scheduling; training is backprop-intensive, affected by model parallelism, optimizer states, and communication. Decoupled architectures let each GPU type optimize independently but introduce weight sync and sample staleness; colocated architectures save GPUs but require frequent switching between inference and training formats.
Common memory optimization techniques:
| Technique | Principle | Applicable Point |
|---|---|---|
| Reference model sharing | Reference isn't trained, can share some weights with Actor | PPO / GRPO |
| LoRA Rollout | rollout side loads base + adapter | LoRA post-training |
| Gradient Checkpointing | trade compute for activation memory | long-sequence training |
| Sequence packing & load balancing | reduce padding and cross-rank waiting | variable-length output |
MoE and PRM further amplify system complexity. MoE needs expert load balancing and training/inference routing consistency; PRM may introduce additional step-level scoring GPUs, making reward computation a new bottleneck [25].
Selection Principles
| Task Type | Primary Question | Category | Inference/Sampling Choice | Training/Orchestration Choice |
|---|---|---|---|---|
| LLM RL prototype | inference throughput for generating completions | LLM RL | vLLM / SGLang | TRL / OpenRLHF / veRL |
| 7B-70B LLM PPO/GRPO/RLOO | how to orchestrate rollout, reward, training, buffer, weight sync | LLM RL | vLLM / SGLang | OpenRLHF / veRL / slime |
| CartPole / LunarLander / small control experiments | environment interface and batched environments | Non-LLM RL | Gymnasium VectorEnv | single-machine PPO/DQN training loop |
| Atari / ViZDoom / DeepMind Lab high-throughput | how to reduce mutual waiting between CPU env, policy forward, learner | Non-LLM RL | IMPALA Actor / Sample Factory rollout worker | IMPALA Learner / Sample Factory Learner |
| Robotics simulation, dexterous hand, humanoid control | how to reduce copies between physics simulation and policy network | Non-LLM RL | Isaac Gym | PPO/SAC and other learners |
When selecting, first determine whether the task falls under LLM RL. For LLM RL, prioritize evaluating inference/rollout throughput, then evaluate how reward, training, buffer, and weight sync are orchestrated. For non-LLM RL, primarily optimize environment interaction and simulation throughput. Within each category, choose the corresponding system based on the specific bottleneck.
If you only remember one decision sequence: first determine LLM RL vs non-LLM RL; then find the sampling bottleneck; then decide synchronous, colocated, or decoupled; finally choose parallelism strategies like FSDP, ZeRO, TP, PP, or EP based on model size. If the task involves multi-turn interaction, tool calling, code execution, web browsing, or multimodal environment state management, stop treating it as "a more complex rollout batch" and move to B.2 Agentic RL Infrastructure.
References
vLLM Documentation, Reinforcement Learning from Human Feedback, 2026. ↩︎ ↩︎
SGLang Documentation, SGLang for RL Systems, 2026. ↩︎ ↩︎
OpenRLHF Project, Architecture Foundation: Ray + vLLM Distribution, README. ↩︎ ↩︎ ↩︎
veRL Project, README and architecture diagram, 2026. ↩︎ ↩︎ ↩︎ ↩︎
THUDM slime Project, slime: An LLM post-training framework for RL Scaling, README. ↩︎ ↩︎ ↩︎ ↩︎
Kwon W, Li Z, Zhuang S, et al. Efficient Memory Management for Large Language Model Serving with PagedAttention, 2023. (vLLM / PagedAttention) ↩︎
vLLM Team, vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention, 2023. ↩︎ ↩︎
SGLang Documentation, PD Disaggregation, 2026. ↩︎
SGLang Documentation, SGLang Router, 2026. ↩︎
vLLM Documentation, Sleep Mode, 2026. ↩︎
HuggingFace TRL Project, TRL: Transformer Reinforcement Learning, 2025. ↩︎ ↩︎
ModelScope Swift Project, ms-swift: ModelScope Framework for LLM/AIGC Training & Inference, 2025. ↩︎
Sheng G, Zhang C, Ye Z, et al. HybridFlow: A Flexible and Efficient RLHF Framework, 2024. veRL GitHub. ↩︎ ↩︎ ↩︎
OpenRLHF Team, OpenRLHF: An Easy-to-use, Scalable and High-performance RLHF Framework, 2024. GitHub. ↩︎
OpenRLHF Documentation, Async Training & Partial Rollout, 2026. ↩︎
slime Documentation, Introducing slime: SGLang-Native Post-Training Framework for RL Scaling, 2025. ↩︎ ↩︎
slime Documentation, v0.1.0: Redefining High-Performance RL Training Frameworks, 2025. ↩︎
LMSYS Blog, Introducing Miles, 2025. ↩︎
radixark Miles Project, Miles: Enterprise-ready RL Framework for LLM/VLM Post-Training, README, 2025. ↩︎
Gymnasium Documentation, Vector Environments (SyncVectorEnv / AsyncVectorEnv). ↩︎
Espeholt L, Soyer H, Munos R, et al. IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures, ICML 2018. ↩︎ ↩︎ ↩︎
Petrenko A, Huang Z, Kumar T, Sukhatme G S, Koltun V. Sample Factory: Egocentric 3D Control from Pixels at 100000 FPS with Asynchronous Reinforcement Learning, ICML 2020. ↩︎ ↩︎ ↩︎
Makoviychuk V, Wawrzyniak L, Guo Y, et al. Isaac Gym: High Performance GPU Based Physics Simulation For Robot Learning, NeurIPS 2021 (Datasets and Benchmarks). ↩︎ ↩︎ ↩︎
HuggingFace Blog, Async RL Training Landscape — 16 Open-Source Libraries Compared, 2026. ↩︎
DeepSeek-AI, DeepSeek-V3 Technical Report, 2024. ↩︎