3.3 V(s): Value Functions and Bellman Equations
Section Guide
Core content
- : evaluates how much future return policy can obtain on average from state .
- Bellman equation: rewrites “looking through the whole future” as “immediate reward + next-state value”.
- Value table: in finite-state problems, stores each state’s as a set of numbers that can be updated.
- From to : first evaluate a policy, then compare actions, and finally use that comparison to find a better policy.
In the previous section, we built the formal framework of RL: an MDP describes the environment rules, measures the total return of a trajectory, and a policy specifies how actions are chosen at each step. With these symbols, we can already describe how an agent interacts with an environment. But description is not solution. Reinforcement learning ultimately cares about the policy: in the same state, changing the action-selection rule can lead to a completely different future. Therefore, before discussing “how to find a good policy,” we first need to solve a basic problem that serves policy improvement: how do we evaluate the current policy’s performance in each state?
The state-value function is prepared for exactly this problem. It asks: if the agent is currently standing in state , and from this moment onward always acts according to policy , how much total return can it obtain on average in the future? Notice that is not a score that naturally belongs to the state itself. It is the performance of policy in state . In the same CartPole situation, a bad policy may quickly let the pole fall, while a good policy can keep it balanced. The state is the same; the policy is different; therefore the value is different.
Directly computing seems to require enumerating every possible future trajectory starting from , which is usually impossible. The role of the Bellman equation is to break this long-term evaluation into a one-step recursion: first look at the immediate reward, then delegate the remaining future to the value of the next state. In this way, policy evaluation no longer needs to see the entire future at once. It can gradually propagate information backward through relationships between neighboring states.
Given a policy , how do we evaluate its performance in every state? Further, if we want a better policy, how do we move from “evaluating states” to “choosing actions”?
Core concept
The Bellman equation connects “policy evaluation” and “policy improvement”: first use to evaluate a policy, then use or an optimality equation to compare actions, so the policy has a direction for improvement.
Core formulas
State Value and Bellman Equation:
- : the value of policy in state , that is, the average total score obtained by starting from and following policy .
- : the one-step reward obtained at future step .
- : the discount factor (Gamma), which controls how much future rewards matter ().
- : the action space, the set of all actions available in the task. In CartPole, for example, these are usually “push left” and “push right”.
- : the policy, the probability of choosing action in state .
- : the state transition probability, the probability of moving to next state after taking action in state .
This section repeatedly uses the following symbols. Let us first make clear what each one means:
| Symbol | How to understand it first |
|---|---|
| The state at step , such as a board position or robot pose | |
| The action at step , such as moving left or outputting a control value | |
| The action space, the set of all available actions | |
| The immediate reward obtained at step | |
| The probability that the policy chooses action in state | |
| The discount factor; farther rewards receive smaller weights | |
| The total return accumulated from step onward | |
| The average total return from starting in state and following policy |
There is an important distinction here:
- is the immediate reward of the current step. It only looks at one step, and we know it after taking that step.
- is the discounted total return actually obtained along one concrete trajectory starting from step . It looks at a whole trajectory, so different trajectories can have different .
- is not the score of one trajectory. It is the average of over many possible trajectories that start from state and then follow policy .
What is the difference between G and V? A numerical example
Start with the full definition. The original formula for discounted return is:
Expanding the summation gives:
For demonstration, suppose the discount factor is . Starting from the same state , we play twice under the same policy, and in each run only keep the first three rewards. In other words, first look at this three-step truncated version:
The first run goes smoothly, with three rewards . Substitute them into the formula:
The result is:
The second run encounters a bad outcome later, with three rewards . Substituting again:
The result is:
Notice that both runs have the same first-step immediate reward, , but what happens afterward is different, so the trajectory-level differs greatly. The state value is the expectation of these possible values. If we currently only have these two samples, we can use their average as a rough estimate:
So is a one-step score, is the total score actually obtained along one trajectory from a certain moment onward, and answers: if we start many times from the same state , what is the long-run average of those total scores?
State-Value Function: Evaluating a State
In the previous section, we had the MDP tuple to describe the rules of the game, to measure the total score obtained from a certain moment onward along one actual trajectory, and to define how actions are chosen. But when making decisions, you are not facing “an entire episode that has already happened.” You are facing a concrete intermediate situation. What you need is not an after-the-fact summary of “how many points this run finally got,” but a before-the-fact judgment: “if I am now standing in this situation, how good is the future likely to be?”
The word “average” is important here. It is not an average over time steps, nor is it the rewards in one episode simply divided by the number of steps. It is an average over many possible future trajectories that may happen when we start from the same state and continue following the same policy . Because the policy may be random and the environment transition may also be random, even if we always start from the same state , the future may unfold into different trajectories and produce different values.
Using the numbers above: starting from the same state , one future trajectory may have return , while another may have return . Both are “the total score after one actual occurrence.” If, under policy , the first kind of future occurs with probability and the second with probability , then the state value is:
Therefore, is like “the score report produced by this particular run,” while is like “before the run starts, standing in the same state , an average prediction over many possible score reports.”
This naturally leads to the state-value function : it turns from “the total score of one actual occurrence” into “the average prediction of future total score when standing in state .” Formally, it is the expectation of under the condition :
The definition of the state-value function is:
If we expand , we get:
Read this formula in three layers:
- : starting from now, add up future rewards.
- : farther rewards are discounted more. only cares about the present; close to 1 cares more about the long term.
- : the environment and policy may be random, so we look at the average result over many attempts.
Expanding the first few terms makes it clearer:
The meaning of each term is as follows: is the reward obtained immediately (not discounted), is the next-step reward discounted once, is the reward two steps later discounted twice, and so on. The farther away a reward is, the higher the power of in its coefficient, and the smaller its contribution. To feel this with CartPole numbers: if each step has and , then (assuming the policy can survive forever).
In one sentence: is “starting from state , if we keep playing according to policy , how much total score can we obtain on average?”
Why does the superscript have to be ? Because for the same state, different policies have different values. In the same chess position, a master continuing the game and a beginner continuing the game obviously have different final win rates. A good policy has high , and a poor policy has low . The goal of RL is to find the policy that makes value highest.
Bellman Equation
Now return to the computation itself. If we want to evaluate the performance of policy in state , the most direct method seems to be: compute every future trajectory starting from , then average their returns. But future trajectories may be very long and may branch heavily. Fortunately, return itself has a recursive structure: . And the state value is defined as . Put these two facts together, and a natural question appears: since the return of one trajectory can be recursive, can the policy-evaluation quantity also be recursive?
The answer is yes. This is the Bellman equation. It is not a concept invented from nowhere. Starting from the definition of and using the recursive structure of , it rewrites “policy evaluation” as “the current step + evaluation of the next state.” Before deriving it, let us first understand why it is necessary:
We have already defined the state value : it is the expected discounted sum of all future rewards. If we want to know the value of a state, the most intuitive thought is: just follow the policy forward and add the rewards along one long trajectory, right?
But in reality, this faces two huge difficulties:
- The future is too long: some tasks have no clear endpoint (for example, maintaining a robot’s balance). How far would you have to add?
- There are too many possibilities: because both the environment and the policy may be random, states branch exponentially like tree branches. To compute an accurate expectation, you would need to traverse countless trajectories.
Faced with infinite horizons and huge state trees, the American applied mathematician Richard Bellman proposed the famous Principle of Optimality in the 1950s while creating the theory of Dynamic Programming. He discovered that we do not need to see through the entire future at once, because “today’s value” must contain “tomorrow’s value.”
This is like calculating retirement savings. You do not need to separately calculate and add the interest for every day over the next 30 years right now. You only need to know: “today’s total asset = today’s income + the future total asset brought by tomorrow’s principal.” This idea of elegantly decomposing an infinite-horizon large problem into “the current step” and “all remaining steps” is the soul of dynamic programming.
The recursive equality written from this principle is called the Bellman Equation. It transforms policy evaluation from an “infinite summation problem” that is hard to compute directly into a recursive relationship that only depends on neighboring states. Precisely because this recursive relationship exists, later methods such as DP, MC, and TD can estimate value through iteration or sampling.
Next, let us see how this magical “recursive loop” is rigorously derived from the original definition of .
Derivation
We have already understood the recursive relationship of value intuitively. Now we give the rigorous mathematical derivation. The essence of the Bellman equation is that it reveals the recursive relationship between the current state value and future state values. The greatness of this derivation is that it strictly proves mathematically that we can completely replace an infinite enumeration of the future with a recursive computation that only looks at “one step ahead.”
According to the definition of the state-value function, expand it:
Here is the expected immediate reward obtained in state after fixing policy . It has already averaged over action uncertainty:
The next step is the most important one: we do want to rewrite in the form of “next-state value,” but we cannot directly write it as .
That direct equality is mathematically wrong.
Use an analogy to understand the subtle difference:
- is like: today (standing at ) you are predicting how much money you can earn starting tomorrow (). Because tomorrow may land in different states, this number has already averaged out the uncertainty of “where tomorrow will be.”
- is like: tomorrow (already standing in a concrete ) you compute how much money you can earn in the future. But from today’s perspective, has not happened yet, so is still a random variable.
Therefore, the equality we truly cannot write directly is:
The left side is a number that has already been averaged under condition , while the right side still depends on the random next state. The correct target is to put the right side inside the same conditional expectation:
To smoothly move the perspective (that is, the condition in probability theory) from to , we do not need any advanced theorem. We only need three basic mathematical tools: the definition of conditional expectation, marginalization in probability theory, and the most important physical assumption in reinforcement learning, the Markov Property.
Supplementary proof: how do we rigorously push the condition from the current state to the next state?
To avoid introducing dazzling new notation, we use only three variables throughout: (current state), (next state), and (future total return). Our final goal is to prove: .
Before deriving it, let us review a basic probability idea: what is a conditioning variable? How exactly does expectation () expand?
Imagine rolling two dice, and . If no one tells you any information and asks you to guess the average value rolled by (that is, its expectation), how would you compute it? Very simply: multiply every possible die outcome (1 through 6) by its probability (1/6), then add everything. In formula form, . This is ordinary expectation. But if someone secretly tells you, “Hey, rolled a 6.” Then is known information, a condition (conditioning variable). When predicting under the condition , your prediction may change. This is called conditional expectation. In formula form, replace ordinary probability with conditional probability: .
This operation of “expanding the big into a summation multiplied by conditional probabilities ” is the core tool in the derivation below. Remember: the thing after the vertical bar
|is the “given fact” we are standing on at the moment.
Step 1: Expand the expectation of
By definition, is the expectation of future return when is given and policy is followed afterward. Using the formula reviewed above: .
Therefore, the expression on the right side that we want to compute, , is really the expectation of a long expression:
Step 2: Expand the expectation again over the next state
The expression above still has an outer uppercase . Although the thing inside the brackets is long, its essence is tomorrow’s value ().
Because “what tomorrow will be” is random, is an uncertain variable. How do we compute the expectation of this random variable? We use the same move: multiply every possible tomorrow by the probability that tomorrow occurs, then add them.
That is, the outer becomes :
Note: the second line only opens the parentheses and multiplies in the outside term .
Step 3: Inject the Markov property (the most important step!)
Notice the term in the expression above. According to the Markov property, once policy is fixed, the future return only depends on the state at that exact moment, not on the earlier state . This is like rolling dice: the result of the second roll depends only on how the second roll is made, not on the first roll. Therefore, mathematically, we can force into the condition without changing the probability value: . Substitute this into the expression:
Step 4: Probability multiplication rule and marginalization
If you have forgotten the basic probability rule, that is fine; we can derive it briefly. The most basic conditional probability formula is: , meaning that “the probability that A happens given B” equals “the probability that A and B happen together” divided by “the probability that B happens.” Multiplying the denominator across gives the multiplication rule: .
If we add an additional condition as a premise to every event, the formula still holds: .
Now take as , as , and as . Then the product of the two probabilities at the end of the expression can be merged: . Continue simplifying:
Proof complete. Step by step, we have rigorously shown: .
Substitute this conclusion back into the original expression, and we obtain the standard form of the Bellman equation:
The second line is expanded using the definition of discrete conditional expectation. For any discrete random variable and condition :
That is: multiply every possible outcome by the probability of its occurrence under condition , then add everything. Here is , the condition is , and is a discrete random variable. Substituting into the definition:
The intuition for each term is: starting from current state , after acting according to policy , there is probability of jumping to next state , and the value of is . Weighting the values of all possible next states by their probabilities gives “how much the next step is worth on average.”
This is the core charm of the Bellman equation: the value of the current state equals the immediate reward plus the expectation of the next state’s value.
Matrix Form
The Bellman equation above only wrote the value of one state . But an environment has more than one state. CartPole has infinitely many states, and even a simple gridworld has dozens. Every state has its own Bellman equation, and these equations are coupled: depends on , while the equation for may refer back to . This means you cannot solve a single equation in isolation. You must solve all state equations jointly.
To write the equations as a matrix, first fix a policy . After fixing the policy, the uncertainty of action selection can be merged into two quantities:
In other words, is not the original environment transition , but the state-to-state transition probability obtained after “first choosing an action according to the policy, then letting the environment transition.”
When the number of states is finite ( states), these simultaneous equations can be written in matrix form:
Here:
- is an column vector containing the values of all states under fixed policy .
- is an column vector representing the expected immediate reward for each state after fixing policy .
- is an policy-induced state transition matrix, describing the probability of jumping from any state to another state after acting according to the policy.
If you are familiar with linear algebra, you can immediately see that this large system of equations can be compressed into one concise expression:
Why are both sides , yet the right side still represents “next-state” values?
The easiest point to get confused about is this: in the single-state formula above, the left side looks at the current state, while the right side looks at next states:
The left side is , but the right side contains . Why, after writing the matrix form, do both sides appear to become the same ?
The key is that the matrix form does not write only one state. It writes all state equations at the same time. To see this clearly, fix the current state as . The single-state formula becomes:
The correspondence is:
| Symbol in the single-state formula | What it corresponds to in the matrix |
|---|---|
| Current state | Row , the value currently being computed for |
| Next state | Column , the possible next state |
| Matrix entry | |
| The -th component of the value vector, |
Therefore, the right side is not just alone, but:
The column vector merely stores all possible “next-state values”:
What truly determines “which current state we are in, and with what probability each next state appears” is the preceding . The -th row of the matrix multiplication expands to:
This is exactly the next-state expectation on the right side of the single-state formula:
For example, the first row corresponds to starting from :
That is, “starting from , take the probability-weighted average of the next-state values.” If the next step may go to , it uses ; if it may stay in , it also uses . All possible next-state values are stored in the same column , so the right side still uses that same column vector.
In other words:
- The on the left: each current state’s own value.
- The on the right: a table providing the values of all possible next states.
- The preceding : weights that value table according to “where the process may jump from the current state.”
- The product : the expected next-state value from each current state.
The Bellman equation is not saying “the current value equals itself.” It is saying:
Since this is a linear equation in the unknown , we can solve directly by moving terms and factoring:
(Here is the identity matrix.)
At this point, we have obtained the analytic solution of the Bellman equation under fixed policy . This means that as long as the environment rules (rewards and transition probabilities) and policy are fully transparent, we can in theory directly compute the exact value of every state under that policy.
If we have a formula, why learn other algorithms?
Because reality is harsh. Computing the analytic solution requires inverting the matrix , and matrix inversion has computational complexity as high as . If the state space is even slightly large (for example, Go has around board positions), we cannot finish the computation in a lifetime. Therefore, this “God’s-eye-view” direct solution usually exists only in theory and in extremely simple toy environments. For complex problems, we must turn to Dynamic Programming (DP), Monte Carlo (MC), or Temporal Difference (TD) methods, which approximate the true value through repeated iteration.
Action-Value Function Q(s,a)
So far, we have been asking: “Standing in this state, if I continue according to policy , how many points can I obtain on average?” The answer is . It is useful, but it is not enough for making choices. The reason is that only scores the state. It does not separately answer whether a particular action itself is good.
In a more everyday phrasing: you are standing at an intersection, and says something like “this intersection is generally not bad.” But what you actually need to decide is: go left or go right? Knowing only that “this intersection is good” is not enough. You also want to know “if I first go left, about how many points can I get; if I first go right, about how many points can I get.” The same is true in CartPole: when the pole tilts right, the state value only tells you how this situation looks on average under the current policy. It does not directly tell you whether to push left or push right now.
So we ask the question more finely: in state , if I first take action , and then continue according to policy , how many points can I obtain on average in the future? This score is the Q function, also called the action-value function.
Compared with , looks at one additional thing: action . You can remember the difference like this:
Difference between V and Q
| Comparison point | ||
|---|---|---|
| Question asked | Standing in state , following policy , how good is it on average? | Standing in state , first take action , then follow policy , how good is it on average? |
| How actions are handled | No action is specified separately; actions are chosen by policy | The first action is specified |
| Effect of actions | Mixed into the average result of policy | Pulled out and scored separately |
| Suitable for answering | Is this situation good overall? | Which action is better in this situation? |
Thus, is better suited for evaluating “whether the situation is good overall,” while is better suited for comparing “which action is better in this situation.” Policy improvement needs the latter.
The definition of the Q function is:
This formula directly defines : currently in state , first specify action , then continue acting according to policy ; what is the expected future return ?
The relationship between V and Q can first be understood in one sentence: is “how much this state is worth before the action has been decided”; is “how much this choice is worth after a particular action has been specified.”
Consider a concrete state . Suppose there are only two actions: right or left. The current policy does not always choose one action; sometimes it goes right and sometimes it goes left:
| Action | Policy selection probability | Action value | Contribution to |
|---|---|---|---|
| Right | |||
| Left |
Here means: if we first go right, then continue according to policy , we can obtain 10 points on average. means that if we first go left, we can only obtain 4 points on average.
But does not ask “how much is it worth after specifying a particular action.” It asks “how much is this state worth on average when policy chooses the action by itself.” Therefore, we must add the two action values weighted by the policy probabilities:
So in this example:
That is, is not a separate object redefined from scratch. It averages all possible values in the same state according to the policy probabilities:
Similarly, has its own one-step recursive relationship: first look at the immediate reward brought by action , then look at the value of the next state reached after that action.
This says: the value of taking action equals the immediate reward brought by action plus the average value of the next state caused by action .
Bellman Expectation Equation
With the conversion relationship between and , we can continue along the equality and write the full Bellman expectation equation.
That is, first write the relationship between and , then substitute the Bellman expansion of :
The logic of this formula is very clear. It expands in two layers:
| Layer | What is being averaged? | Corresponding formula |
|---|---|---|
| Action layer | The policy may choose different actions | |
| State layer | The same action may reach different next states |
Intuitive example: treasure corridor
Imagine a five-cell corridor, with treasure on the far right. You can only keep walking right. Each step costs 1 unit of stamina, so every step has reward ; after reaching the treasure, the game ends, and the terminal value is recorded as .
Do not rush to inspect the whole path. Start from the easiest position: cell 5 is the treasure, and the episode is already over, so its value is 0.
| Position | Why it is computed this way | Value |
|---|---|---|
| Cell 5 | Already at the treasure; no need to walk | |
| Cell 4 | One step to cell 5: | |
| Cell 3 | One step to cell 4: | |
| Cell 2 | One step to cell 3: | |
| Cell 1 | One step to cell 2: |
So the value table for this corridor is:
This example is meant to explain one thing: the value of the current position can be computed as “the reward for taking one step + the value of the next cell.” This is the most intuitive form of the Bellman equation.
Bellman Optimality Equation
The Bellman expectation equation answers: “If I act according to policy , how many points is state worth?” But the ultimate goal of RL is to find the best policy. We want to know: “If I make the optimal choice at every step, how many points can state be worth at most?”
This introduces the optimal value function and the optimal action-value function . In a state, the optimal choice is to select the action that maximizes :
Similarly, the optimal still follows the Bellman recursion (except that future states are also assumed to act according to the optimal policy):
Substituting into gives the Bellman optimality equation:
Compared with the expectation equation, the only difference is that summation (averaging) becomes maximization ().
- Expectation equation : weighted average according to the policy probabilities.
- Optimality equation : discard probabilities and directly choose the action with the largest value. Once the optimality equation is solved, the optimal policy naturally follows: choose each time.
Look at a small two-step example. Suppose you are currently in state and have two actions: right or left. First write out the paths:
| Current action | Immediate reward | Reaches |
|---|---|---|
| Right | ||
| Left |
The easy-to-confuse part is “after reaching the next state, how do we continue?” An ordinary policy and an optimal policy are different here:
| Reached state | Continue under ordinary policy | From then on, always act optimally |
|---|---|---|
| Can still get on average | Can still get at most | |
| Can still get on average | Can still get at most |
This table means: if the first step goes right and reaches , ordinary policy may still explore afterward and may not choose the best action every time, so it can get on average. But if from onward every step chooses the best action, it can get at most . If the first step goes left and reaches , the ordinary policy can get afterward on average, but if it acts optimally afterward, it can get at most .
Now computing becomes clear. First consider ordinary policy . means: first take action , then continue following policy .
| Action | Reward | Next state | Future value under | |
|---|---|---|---|---|
| Right | ||||
| Left |
If the current policy still explores randomly in state , for example choosing right with probability and left with probability , then its state value is the probability-weighted average of the two values:
Now consider the optimal case. means: first take action , then act optimally at every later step. Therefore, after going right, we use the optimal future value of , which is , not the ordinary-policy value :
| Action | Reward | Next state | Future value under optimal behavior | |
|---|---|---|---|---|
| Right | ||||
| Left |
In the current state, the optimal action value for right is 8 and for left is 4, so the optimal value directly takes the maximum:
The difference between the two computations is:
| Case | Which Q is used? | How the current action is handled | Computed V |
|---|---|---|---|
| Ordinary policy | Average by policy probability: right, left | ||
| Optimal value | Directly choose the maximum: |
The expectation equation evaluates “how good the current policy is on average,” so it uses and averages according to the policy probabilities. The optimality equation searches for “how good things can be if the best choice is made from now into the future,” so it uses and takes the maximum.
Value Tables: From Value Equations to Updatable Tables
At this point, we know the definition of and have derived the Bellman equation. It tells us: if policy is fixed, the true value function must satisfy the recursive relationship “immediate reward + next-state value.”
However, the Bellman equation only gives a constraint. It does not directly give the answer. It says, “the true must make the current-state and next-state values line up with each other.” This is like writing down a system of linear equations: doing so does not mean we have already solved every unknown. Knowing how values should recurse does not mean we already know the concrete number for every .
To turn the equation into an algorithm, we need to assign each state a storage location, fill it initially with some number, and then let the program repeatedly modify it so it approaches the true value. This is the value table.
If the state space is small, the simplest method is to store one number for each state, without introducing a neural network first. For example, in a three-cell corridor with three states , we prepare three rows:
| State | Current estimate | Meaning |
|---|---|---|
| Long-term return estimate from | ||
| Long-term return estimate from | ||
| From the terminal state, usually there is no future return |
This list of “state value estimate” is what this book calls a value table. It is not a new mathematical object, but a representation of . Mathematically, it can be viewed as the value vector in the matrix form above. In a program, it can be a NumPy array, a Python dictionary, a hash table, or a column in a database table.
More generally, this belongs to tabular methods. In the reinforcement learning literature, tabular methods mean that the number of states and actions is small enough that we can store a separate entry for every state or every state-action pair and directly update those entries[1]. Therefore, the “table” does not necessarily have to be drawn as a spreadsheet; the key is that every state has its own storage location.
First separate two things that are easy to confuse:
- Environment rule table: describes the task itself, recording “from where, doing what, to where, and receiving how much reward.” In small discrete problems, it is a tabular representation of the environment model. If the environment is stochastic, the table must also include probabilities of different next states.
- Value table: describes the algorithm’s current judgment, recording “from this state, how much is it probably worth in the long run?”
Textbooks often draw the value table directly on the state space. The following figure comes from Sutton and Barto’s small Gridworld policy-evaluation example. Here GridWorld is a grid environment: cells represent states, movement directions represent actions, and the numbers in cells represent the current estimate of .
The left column shows the value table after rounds of policy evaluation under the same random policy. The right column shows what greedy policy would be obtained if we used these value tables to choose actions.
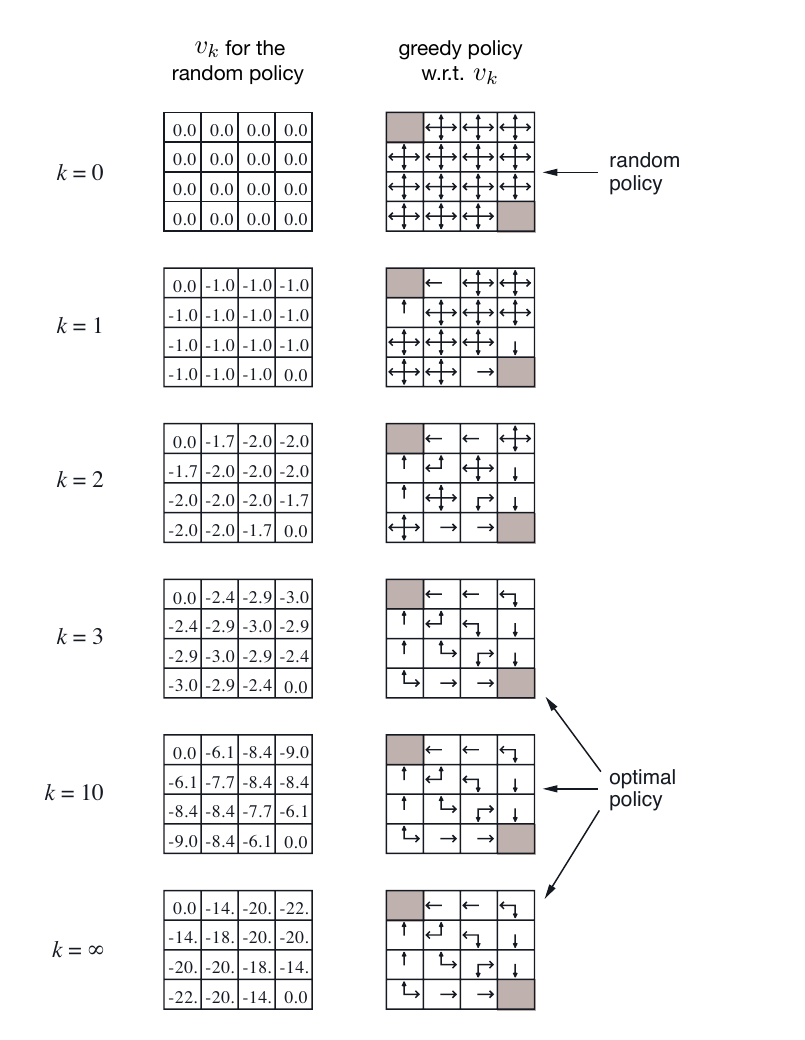
Source: Sutton and Barto, Reinforcement Learning: An Introduction, 2nd ed., Figure 4.1. The original book uses the CC BY-NC-ND 2.0 license.
For now, it is enough to look only at the left column. At , except for terminal states, many cell values start from 0. After several iterations, positions near the terminal states change first, and farther positions are gradually pulled along. The numbers are not “the reward obtained immediately upon entering this cell.” They are “the expected total return from this cell onward under the current policy.”
Consider a minimal example: a three-cell corridor.
Environment rule table: records what happens in one step
| Current state | Action | Next state | Reward |
|---|---|---|---|
| Move right | |||
| Move right | |||
| End | None |
Value table: records how much it is probably worth from here onward
| State | Current estimate | Meaning |
|---|---|---|
| Starting from , two steps are expected | ||
| Starting from , one step is expected | ||
| Already at the terminal state; no future reward |
The first table comes from the environment and tells us “what happens after one step.” In this corridor example, transitions are deterministic, so each row contains only one next state. If the same action may lead to multiple next states, the environment rule table must be written with probabilities, which is exactly . The second table comes from the algorithm and stores the current estimate of long-term return. Reward is one-step; value is long-term. Reward is given by the environment; value must be estimated by the algorithm.
Notice that the in the second table are the results after computation is already correct. At the beginning, the algorithm usually does not know these answers. It may initialize the entire table to 0:
| State | Current estimate |
|---|---|
The 0 here does not mean these states are truly worth only 0 points. It means “we do not know yet, so use 0 as the initial guess.” What later DP, MC, and TD methods do is continuously modify the right-hand column so that it gradually approaches the true .
To summarize: the value table solves a very concrete problem: it gives the abstract value function a carrier that can be repeatedly updated. When the number of states is finite and enumerable, the value table is the most direct representation. When the state space is huge or continuous, this table cannot fit everything, and later we need function approximation and neural networks to replace it.
The same idea naturally extends to action values. A state-value table stores one number for each state; an action-value table stores one number for every “state-action pair,” namely . The Q table in Section 3.5 is essentially the value table here extended from “one cell per state” to “one cell per action under each state.” Classic TD learning can be viewed as using experience to correct state predictions[2]; Q-learning updates action values in a tabular setting with finite states, finite actions, and repeated sampling[3].
From Equation to Update Rule
The previous subsection explained the role of the value table: every state has a location in the table, but the number inside is initially only a temporary estimate. The next real problem is: how should these numbers gradually become estimates closer to the true values?
Look at the Bellman equation from another angle. Earlier, when we wrote it, it looked like an “equality that the correct answer must satisfy”:
Both sides here use the true , so the equation describes the relationship of the final answer. But at the beginning, the algorithm does not have the true . It only has a temporary value table . Therefore, the natural idea is: treat the right-hand side of the equation as a new target value, and use it to rewrite the old table.
Before answering how to rewrite it, distinguish two situations:
- The environment model is known: here “environment model” means the mathematical version of the environment rules: after taking action in state , with what probability will we arrive at each next state , and how much reward will we obtain on average? In other words, we know the transition probability and reward , so we can directly use the Bellman equation to construct an update rule.
- The environment is a black box: we do not know this information. We can only actually take one step, observe one reward and one next state.
First look at the first situation.
For a fixed policy , denote the old table as . Now we no longer pretend that we already know the true . Instead, we use in the old table to estimate the value of next states:
This step means:
- The inner computes “the expected value of the next state after taking action .”
- The outer averages over actions according to the current policy .
- After adding and discount factor , the result is “how much the old table thinks state should now be worth.”
The update rule is then direct:
Doing this computation for all states produces a new round of the value table, . This step is often called a Bellman backup: use the old estimate of the next state to update the current state in reverse.
Sometimes we do not directly replace the old value, but only move a small step toward the target:
Here is the learning rate. means fully adopting the new target; means moving the old value only 10% of the way toward the target. Whether we replace directly or move by a small step, the core idea is the same: the right-hand side of the Bellman equation gives the target, and the value table stores the current estimate.
Use a minimal example to verify this. To avoid being distracted by multiple states, shrink the value table to the minimum: the entire table has only one row, and the only state is .
| State | Current estimate |
|---|---|
Imagine there is only one slot machine A in front of you. Each round, you press the button, receive one reward, and then return to the same state . The policy is fixed: always choose A. Now ask only one question:
Starting from this state and continuing forever, what is the discounted average total return?
The setting is:
- There is only one state, and after playing one round, we return to the same state.
- Always choose machine A.
- Machine A gives reward with probability 60% and reward with probability 40%.
- The discount factor is .
The one-step expected reward is:
Because after each round we are still in the same state, the next-state value still looks up the same cell in the value table, namely . According to the Bellman expectation equation:
Analytic solution: solve the equation directly. , so . This is not a one-step reward. It is the number that the cell for state in the value table should ultimately approach, meaning “from now on, if we keep playing, the discounted average total return.”
Iterative method: if we do not want to, or cannot, solve the equation directly, we can also start from the initial value table and perform one Bellman update each round, changing the cell for state into a new estimate:
Compute the first few rounds by hand:
| Round | Update formula | New value of in the table |
|---|---|---|
| Initial | - | |
| Round 1 | ||
| Round 2 | ||
| Round 3 | ||
| Round 4 | ||
| Round 5 |
Each round uses “immediate expected reward + discounted old value estimate” to obtain a new estimate. Because there is only one state, it looks like we are only updating one number. With multiple states, the same operation updates the whole value table cell by cell. At the beginning it is far from , but it approaches gradually.
R = 0.2
gamma = 0.9
V = 0.0
for i in range(50):
V = R + gamma * V
print(round(V, 6))运行结果
1.998698
This is the basic shape of Bellman iteration: instead of computing the answer all at once, repeatedly apply the Bellman relationship so that the estimate gradually approaches the true value. Under a fixed policy , this corresponds to iterative policy evaluation. If later we replace “averaging according to the policy” with “taking the maximum over actions,” it leads to value iteration in optimal control.
When the Environment Is a Black Box: TD Error
Return to the slot-machine example. There we could write because two things were already known: the average reward each time is , and after pressing the button we definitely return to the same state. In other words, we knew the environment rules, so we could directly compute “what happens next on average.”
Real tasks are usually not this convenient. The agent does not know where each action will lead, nor the probabilities of different outcomes. It can only actually take a step, see a reward, and see which state it lands in. TD error is used in this situation. First understand it as a reconciliation tool: compare “the target given by this one actual experience” with “the old estimate in the value table,” and see how much they differ.
If you do not fully understand this on the first reading, that is fine. The next section compares DP, MC, and TD side by side, and later algorithm chapters will repeatedly return to this concept. For now, grasp one distinction: when the model is known, we compute the average case; TD sees only the one case that just happened.
First look at the known-model form. Suppose we know the complete environment rules. Then we can write the exact Bellman target:
Here is not one realized reward, but an average reward; is not one realized next state, but the probability of each possible next state. The expression means: include all possible actions and all possible next states, then average according to their probabilities.
TD cannot do this. It does not have that probability table. It only knows what truly happened in the most recent step: the reward observed this time was , and the next state reached this time was . Therefore, it first constructs a temporary target from this one experience:
The lowercase and remind us that they are not the average laws of the environment, but one result just observed. This target may be too high or too low, but after many samples, these high and low deviations gradually cancel out.
The comparison is:
| Method | Reward used | Next state used | Nature of target |
|---|---|---|---|
| Exact Bellman update | Expected reward | All possible , weighted by | Exact expectation |
| TD update | This actual reward | This actual next state | Noisy one-sample estimate |
A numerical example makes it clearer. Suppose that after acting according to the current policy in state , the environment has two possible outcomes:
| Next state | Probability | This-step reward | Current value estimate |
|---|---|---|---|
| 70% | |||
| 30% |
Let . If the model is known, we include both possibilities:
This is the exact Bellman update. It is like holding an environment manual: we know what outcomes may happen from and the probability of each, so we can compute the average target at once.
TD is in a different position. It does not have this manual, and it is not actively sampling outcomes with 70% and 30% by itself. “Sampling” only means that the agent actually took one step and the environment gave it one result. If the environment naturally has the pattern “most of the time go to , sometimes go to ,” then when repeatedly starting from , the agent will naturally see more often and occasionally. But in each update, TD uses only the single experience in front of it.
Suppose the value table currently has , and the learning rate is .
If this time it really reached and received reward , TD computes:
Then it adjusts upward a little:
If another time it really reached and received reward , TD computes:
Then it adjusts downward a little:
Put the two cases together:
| What really happened this time | TD Target | TD error | Updated |
|---|---|---|---|
| Reached , reward | |||
| Reached , reward |
There is an important detail here: TD does not guarantee that every single update moves closer to the average target.
In this example, the exact Bellman target is , while the current , so the difference is . If this time we reached , the updated value becomes , which is indeed closer to . But if this time we reached , the updated value becomes , which is farther from .
This is not a contradiction. It is normal TD behavior. TD corrects the value table using only the experience in front of it, so one “bad outcome” pulls the estimate down, and one “good outcome” pushes it up. A single update may move in the wrong direction; what matters is the average direction over many updates.
Combine the two updates according to the environment’s own probabilities:
That is, if we start from , the “average position” after the next TD update is . It still does not jump directly to , but it is already closer to than was.
Similarly, from the TD error perspective:
The average TD error is positive, which means that over the long run, the current is too low and should be adjusted upward. It is just that each actual experience does not necessarily move in that direction.
The point of this table is not that “the agent should sample according to 70% and 30%.” It is that TD only looks at one real experience each time. Common outcomes participate in updates more frequently, and rare outcomes participate less frequently. After many updates accumulate, the average direction gradually approaches the probability-weighted Bellman target above.
This is the Temporal Difference Error, usually called the TD Error. It measures how far the “one-step target” is from the “current estimate”:
Why is it called “temporal difference”? Because it compares prediction differences between two neighboring states in a time sequence: when standing at , we have an old prediction; after moving to , the term gives a new target.
Its meaning is direct:
| TD Error | Meaning | How to adjust |
|---|---|---|
| The target is higher than the current estimate, so we underestimated | Increase | |
| The target is lower than the current estimate, so we overestimated | Decrease | |
| Under this sample, the target and estimate agree | Almost no adjustment needed |
The simplest update formula is:
The and in the two branches above are exactly the results of this formula when .
This is the basic move of TD learning: every time the agent takes a step, it uses “the one step actually experienced + the next-state estimate” to correct the current-state estimate. After many samples, the noise of single samples is averaged out, and the value table gradually approaches the true .
DP, MC, and TD handle different environment conditions and information assumptions. The next section, Classic Methods at a Glance: DP, MC, and TD, compares them specifically.
Section Summary
This page has many formulas, but only one main thread:
- is the average long-term return obtained by starting from state and acting according to policy .
- Return can recurse: .
- Therefore value can also recurse: current value equals immediate reward plus next-state value.
- If the policy is fixed, we obtain the Bellman expectation equation.
- If the best action is chosen at every step, we obtain the Bellman optimality equation.
- In finite-state problems, can be stored as a value table, giving every state an updatable number.
- If we only have sampled data, we use the Bellman target and TD Error to gradually correct in the value table.
can already tell you “whether this situation is good,” but there are still two gaps at this point.
The first gap is: if we do not know the environment model, how do we estimate ? The Bellman expectation equation contains and , but in real tasks we often only obtain sampled trajectories one by one. The next section discusses DP, MC, and TD, which are three ways to estimate value from models or data.
The second gap is: does not directly tell you which action to choose. If , you only know the current situation is good, but you do not know whether to go left, go right, or stay still. A more direct approach is to score each action as well:
There is no need to expand yet. For now, just remember the division of labor between the two tables: the value table scores states, while the action-value table scores “first taking action in state .” If the environment model is known, meaning we know how each action affects the next state and reward, we can use the table for one-step lookahead to compare actions. If the environment model is unknown, directly learning the table is often more convenient, because it stores the long-term consequences of each action directly.
So the next sequence is: first read DP, MC, and TD to solve “how to estimate ”; then enter Action-Value Function to solve “how to use value to choose actions.”
References
Sutton, R. S., & Barto, A. G. (2018). Reinforcement Learning: An Introduction (2nd ed.). MIT Press. Part I of the book is titled “Tabular Solution Methods,” and Chapter 4, Figure 4.1 shows the policy-evaluation process of writing state values directly in Gridworld cells. MIT Press Open Access page: https://mitpress.mit.edu/9780262039246/reinforcement-learning/; author-hosted PDF: http://incompleteideas.net/book/RLbook2020.pdf. ↩︎
Sutton, R. S. (1988). Learning to predict by the methods of temporal differences. Machine Learning, 3(1), 9-44. DOI: https://doi.org/10.1007/BF00115009. ↩︎
Watkins, C. J. C. H., & Dayan, P. (1992). Q-learning. Machine Learning, 8, 279-292. DOI: https://doi.org/10.1007/BF00992698; author page: https://www.gatsby.ucl.ac.uk/~dayan/papers/wd92.html. ↩︎