VLM Reinforcement Learning
In earlier chapters, we pushed RL from classic control to LLM post-training:
- DQN learns from pixels in Atari,
- PPO stabilizes policy updates,
- DPO/GRPO optimize language models with preference signals or verifiable rewards.
Most of those settings share a simplifying assumption: there is only one input modality (state vectors, pixels, or text tokens).
The real world is not text-only. You see images, screenshots, charts, videos, and 3D scenes. Before you can reason and act, you must first understand visual evidence. Vision-language models (VLMs) bring images and language into a single model. RL then asks a harder question:
Can we use outcome feedback to make the model not only describe images, but see more accurately, reason more reliably, and answer more truthfully?
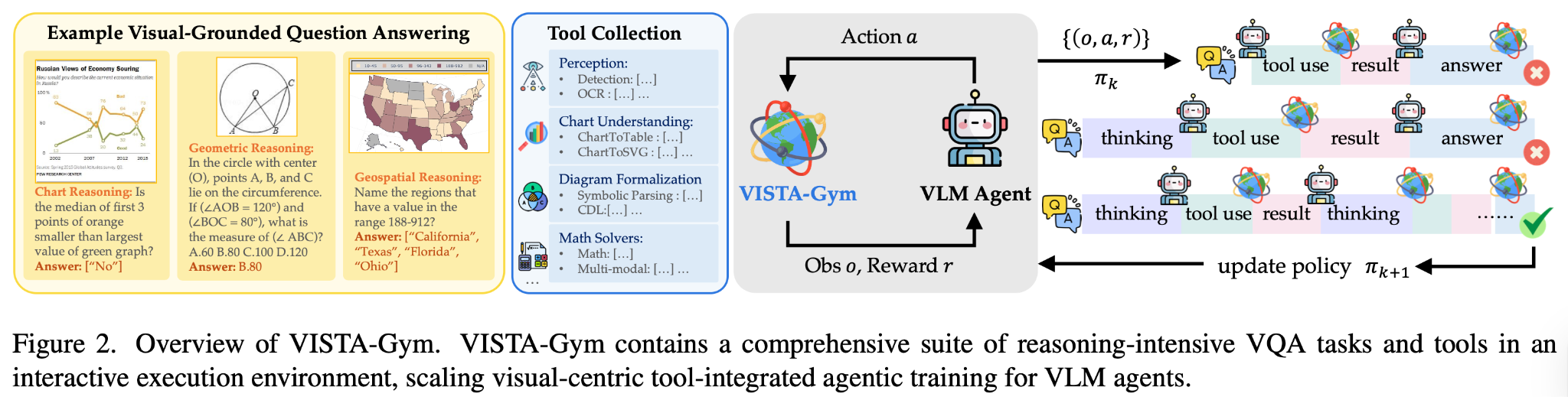
Moving RL from text to multimodal models is not "just add image tokens." Once you train seriously, you run into a set of problems that do not appear in text-only RL:
- Who is responsible for an error? If the answer is wrong, was the vision encoder wrong, or was the language reasoning wrong?
- Should the vision encoder be updated by RL? Update too aggressively and you can degrade vision (the model "goes blind"); freeze it completely and you cannot improve visual ability.
- Will the model pretend it saw the image? If guessing can get reward, RL can reinforce visual hallucinations.
- How does vision connect to action? In driving, robotics, and GUI agents, visual outputs affect real decisions. Safety and latency become training constraints.
This chapter opens these issues in a progressive way: first a minimal GRPO experiment to build intuition, then the special challenges of VLM RL, then frameworks that connect experiments to real applications, and finally RL post-training for visual generation models.
Prerequisites
- GRPO: group-based optimization without a critic
- Reward model design: rules vs model rewards, hacking risks
- PPO-RLHF loop: KL penalty, clipping, reference model
VLM RL vs Text-Only RL
In text-only RL, inputs and outputs are tokens. If an answer is bad, we usually ask one question: did the generated tokens match the reward target?
In VLM RL, there is a visual pipeline:
image -> vision encoder -> visual tokens -> multimodal fusion -> language reasoning -> output.
So training becomes "see correctly, then reason correctly." A single scalar reward does not automatically tell you where the failure came from. This is the core credit-assignment problem in multimodal RL.
Learning Path
This chapter is organized as: run something minimal -> see the new problems -> understand systems -> extend to generation.
| Section | Question it answers |
|---|---|
| 11.1 Hands-On: GRPO for a VLM | How do we train a VLM to "look then reason" under verifiable rewards? |
| 11.2 Challenges | How do we assign reward across vision vs language? How do we reduce visual hallucination? |
| 11.3 Frameworks | What systems bridge experiments to applications (tools, environments, self-play)? |
| 11.4 Visual Generation RL | How does RL apply to diffusion/video generation, and what does "policy" mean there? |
| 11.5 Hands-On: EasyR1 GeoQA | How do we run an industrial-style VLM GRPO training loop on a real dataset? |
Learning Goals
After this chapter, you should be able to:
- map VLM RL back to the same RL primitives you already know (policy, trajectory, reward, KL constraints),
- explain why multimodality changes reward design and credit assignment,
- identify the typical failure modes (visual hallucination, encoder collapse, mis-grounding),
- and evaluate whether a VLM is truly using visual evidence rather than language priors.