5.5 Hands-On: Policy Gradient with a Baseline
Goal of this section: On
CartPole-v1, compare vanilla REINFORCE against REINFORCE + Value Baseline, and observe how can make policy-gradient training faster and more stable.
Code for this section: reinforce_with_baseline.py · render_cartpole_baseline.py · reinforce_cartpole.py · requirements.txt
In the previous two sections, we (1) ran vanilla REINFORCE end-to-end, and (2) derived, mathematically, why introducing a baseline reduces variance. In this section, we put them side by side and look at the practical effect of replacing with .
Run The Comparison Experiment
pip install -r code/chapter05_policy_gradient/requirements.txtpython code/chapter05_policy_gradient/reinforce_with_baseline.pyThis script trains two policies:
| Experiment | Update Signal | Extra Network | Intuition |
|---|---|---|---|
| Vanilla REINFORCE | None | Only cares about how many points this episode actually got | |
| REINFORCE + Value Baseline | Value Network | Cares about how much better than “expected from this state” |
Both versions use the same CartPole environment and the same policy network. The only difference is the update target. The vanilla variant uses the full return . The Value Baseline variant first trains a value network to estimate , then uses the advantage to update the policy.
After the script finishes, it will produce two figures:
| Output File | Description |
|---|---|
output/reinforce_baseline_reward_comparison.png | Episode-reward curves for both methods |
output/reinforce_baseline_variance_comparison.png | Variance curves of the gradient estimator |
If you also want to export replay GIFs:
python code/chapter05_policy_gradient/render_cartpole_baseline.py \
--episodes 500 \
--seed 0Read The Reward Curve
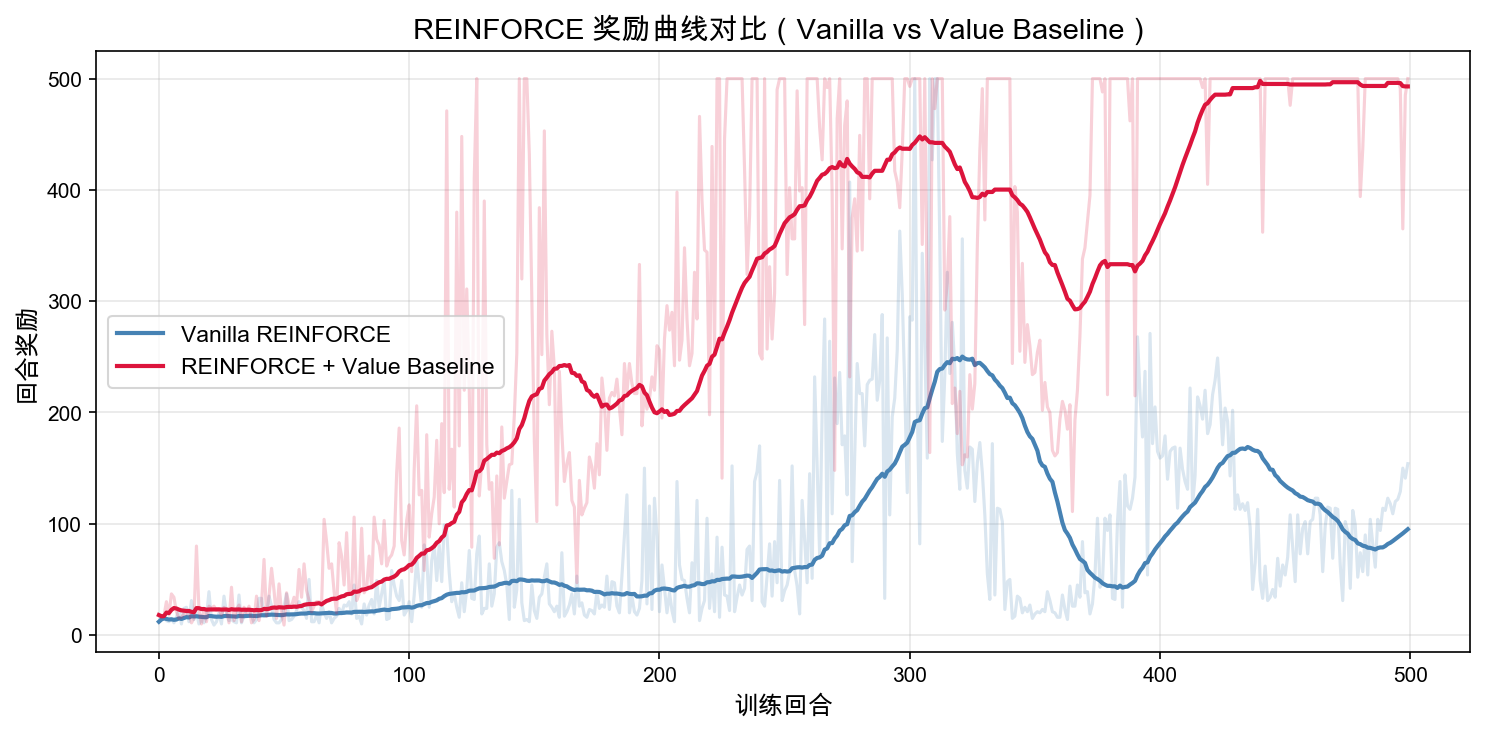
In the plot, the light line is the raw return of each episode, and the dark line is a moving average.
In this run, vanilla REINFORCE achieved an average return of about 95.1 over the last 50 episodes. It is learning, but it learns slowly, and there is a clear drop midway through training. After adding the value baseline, the average return over the last 50 episodes is about 493.0, already very close to CartPole’s 500-step cap.
This gap is the key message: the value baseline is not a decorative mathematical term. On the same task, it can move the policy more quickly into the regime where it can “basically keep the pole upright”, and it reduces the chance that performance suddenly collapses late in training.
Watch The Replays
The reward curve tells you the average trend; replays tell you what the policy is actually doing.
Vanilla REINFORCE: it can hold for a while, but it still drifts off and over-corrects easily. In this rendering, the return is 166. The policy is no longer random, but once the pole deviates, the corrections are not stable enough.
REINFORCE + Value Baseline: it pulls the pole back toward the center more consistently. In this rendering, the return is 355. The corrective actions are visibly more coherent; when the pole deviates, it is more likely to be brought back.
Read The Variance Curve
The reward curve answers “does the policy get better?” The variance curve answers another question: why does the value baseline make training more stable?
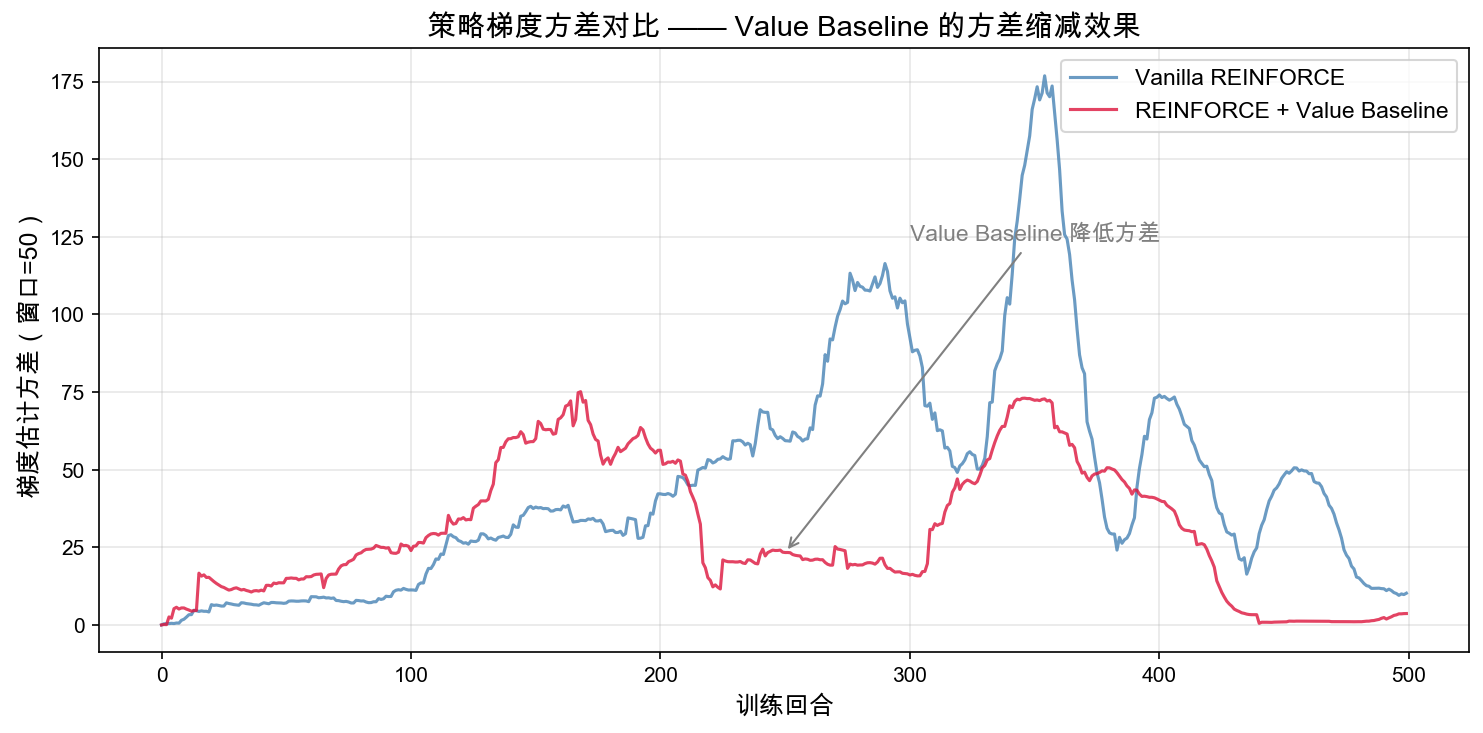
This figure plots the variance of the gradient estimator within a sliding window. A larger value means different episodes suggest very different update directions; a smaller value means each policy update is more consistent.
In this run, the gradient-estimator variance is about 100.41 for vanilla REINFORCE and about 38.27 for the Value Baseline version. That is roughly 38.1% of the original. This matches what we saw in the reward curve: when the update signal is steadier, the policy can keep moving in the direction of “keeping the pole upright”.
What Exactly Changed In The Code
The core update in vanilla REINFORCE is:
returns_t = torch.FloatTensor(returns)
log_probs = torch.log(action_probs + 1e-8)
loss = -(log_probs * returns_t).mean()Here returns_t is . If an episode happens to last a long time, then every action on that trajectory is reinforced with a large weight, including many actions that merely “didn’t cause trouble by chance”.
After adding a value baseline, the script introduces an additional value network:
values = value_net(states_t)
value_loss = nn.MSELoss()(values, returns_t)The value network learns: starting from state , how many points do we typically get? Then the policy network no longer uses directly; it uses the advantage instead:
with torch.no_grad():
values_pred = value_net(states_t)
advantages = returns_t - values_pred
policy_loss = -(log_probs * advantages).mean()If advantages is positive, the outcome following this step is better than expected, so the corresponding action should become more frequent. If it is negative, the outcome is worse than expected, so the action should become less frequent.
Because the value baseline does not depend on the current action, it does not change the expected direction of the policy gradient. What it changes is the amount of noise in the estimator. That is what “variance reduction” means here.
Re-Interpret It Back In The Scene
Suppose the cart has already brought the pole close to vertical. If, from that state, the agent can typically last for a long time, then lasting a few more steps does not mean the last action was magically correct. It is simply the natural result of being in a good state. In such a situation, is large, and subtracting it prevents the advantage from being exaggerated.
Conversely, if the pole is already leaning substantially, but the cart executes a correct action and “saves the situation”, then the realized return may be clearly above the value network’s expectation. Now is positive, and the policy receives a sharper, more decisive reinforcement signal for that corrective action.
The baseline makes learning “finer-grained” than looking only at the total score. Getting 100 points in a dangerous state and getting 100 points in an easy state do not mean the same thing.
Common Misreadings
Misreading 1: A value baseline makes the reward larger. The value baseline does not alter environment rewards. In CartPole, each step still gives +1. What changes is how training interprets and uses these rewards.
Misreading 2: The larger the baseline, the better. If the baseline estimate is poor, the advantage will also be noisy. We use a value network to learn precisely because different states have different reasonable average returns. A fixed constant baseline can only handle very simple, stateless problems.
Misreading 3: With a value baseline, it is already Actor-Critic. This section is still REINFORCE with a Value Baseline. It waits until an entire episode ends, then uses the Monte Carlo return for updates. In the next chapter, Actor-Critic will go further by replacing the full return with a TD target, enabling updates at every step.
Exercises
- Change
num_episodesto200, and see which method learns a usable policy earlier. - Change the learning rate from
1e-3to5e-4or2e-3, and compare whether the value baseline is still more stable. - Print
advantages.mean()andadvantages.std()in the script, and observe whether the advantage signal fluctuates around 0. - Change the hidden size of the Value Network from
128to32, and see whether weakening the baseline estimate makes the training curve noisier.