11.4 RL Post-Training for Visual Generation Models
In the preceding chapters, we started from LLM text post-training: the model reads text, generates an answer, and RL's goal is to make it better aligned with human preferences, better at reasoning, and less prone to format and factual errors. In this chapter, we extended the input from pure text to images and text, discussing the understanding side of VLM: the model looks at an image and answers a question, with RL's goal being to make it see more accurately and answer more robustly.
Now we take another step forward, moving to the other side of visual AI: generation. Given a text prompt, the model must generate an image or a video.
This may seem like "making the model draw prettier pictures." But in real applications, users rarely want just "pretty." Users truly want: the subject to be correct, the count to be right, spatial relationships to be accurate, details to be precise, and the overall style to be natural.
For example, the prompt might say:
Three red umbrellas in a glass corridor, with a blue sign on the right wall.
The model generates a beautiful glass corridor, but with only two umbrellas, and the sign is not blue. Should this image get a high or low score? By aesthetics alone, it might be excellent; by instruction-following, it clearly fails.
Therefore, the core question of visual generation RL is:
Can "generating well" be decomposed into feedback signals that can be learned, compared, and optimized?
This section follows a complete generation trajectory: first understanding why visual generation is harder to write rewards for than visual QA, then translating Diffusion's denoising process into MDP language, and finally arriving at DDPO's policy gradient, training steps, and reward model design.

The algorithm storyline corresponding to this image comes from the DDPO paper; the subsequent exposition of writing Diffusion as MDP and then using policy gradients to update denoising trajectories also uses this paper as the core reference[1].
From LLM to VLM, to Visual Generation: What Changes When RL Transfers?
A better way to understand the progression is not "can VLM directly transfer to generation," but to first look at a longer path:
LLM Text RL → VLM Understanding RL → Visual Generation RL
All three use the same basic RL language: the model is the policy, model outputs form trajectories, rewards evaluate trajectories, and training uses KL, clipping, or advantage to stabilize updates. But with each step forward, the optimized object changes.
First, LLM. The input is a text context, and the output is also text. One response can be viewed as a token trajectory:
Each step's action is "choose the next token." Rewards can come from human preference models, rule checks, math verifiers, code execution results, or format constraints. Methods like PPO, DPO, and GRPO differ in details but mostly revolve around "how to make text responses better match rewards."
Moving to VLM understanding, the input gains images:
But many tasks still output text, options, coordinates, or bounding boxes. That is, the model has more visual evidence, but actions still often fall on tokens or structured answers. Rewards are also relatively easy to write: is the answer correct, is the box well-aligned, is the IoU high enough, does the reasoning format meet requirements. This is the core of work like VLM-R1 / VISTA-Gym from previous sections: teaching the model to leverage visual information rather than relying on language priors to guess answers.
Then visual generation is where things truly shift to a different level. The model's goal is no longer "look at an image and answer," but "create a new visual result based on a prompt." The output is no longer a string of answer tokens, but an image, a video, or more precisely, a latent / denoising trajectory. The reward no longer mainly asks "does the answer equal the ground truth," but asks:
- Does the image match the prompt?
- Are counts, colors, and spatial relationships correct?
- Do humans prefer this result?
- Is the image natural, clear, and stylistically consistent?
- Are consecutive video frames coherent?
We can put these three stages in a table:
| Stage | Input | Output | Action in RL | Reward Resembles |
|---|---|---|---|---|
| LLM text post-training | Text prompt | Text response | Next token | Preference, rules, verifier |
| VLM understanding post-training | Image + text question | Text, options, boxes, coordinates | Mostly tokens or structured answers | Answer correctness, IoU, tool verification |
| Visual generation post-training | Text / image condition | Image, video, latent trajectory | Each denoising transition | Preference, alignment, quality, fine-grained constraints |
So visual generation RL does not overturn what came before; it applies the same RL language to a harder object.
What can be inherited includes: policy gradient, advantage, KL regularization, PPO-style clipping, reward models, and judge models. What truly needs rewriting is state, action, trajectory, and reward.
This is why work like DDPO first does something seemingly simple but very important: translating Diffusion's denoising process into states, actions, trajectories, and rewards[1:1]. Only when this translation is clear do we know what policy gradients are actually updating.
Starting from Diffusion's Sampling Process
A diffusion model's generation process can be understood as "starting from noise, progressively denoising."
Initially, the model has a latent close to random noise, denoted . Then the model generates step by step:
Here is the latent corresponding to the final image. After passing through a decoder, the user sees the image.
At each denoising step, the model looks at three things:
| Symbol | Meaning |
|---|---|
| Current noisy latent | |
| Current denoising timestep | |
| Prompt or conditioning information |
The model decides the next latent:
This formula means: given the current noisy state , timestep , and prompt , the model defines a probability distribution using parameters and samples the next step from it.
Why does this resemble a policy? Because in RL, a policy is defined as:
"Given current state , the probability distribution for choosing action ."
In LLMs, we are familiar with this form:
Given preceding tokens and context , the model chooses the next token . So tokens are actions, and text context is the state.
Diffusion's denoising distribution has the same shape:
Given the current noisy latent, timestep, and prompt, the model chooses the next latent. So can be viewed as the state, and or the equivalent denoising direction as the action.
Of course, this statement only means "it can formally be viewed as a policy." It does not yet constitute RL. Only when we define a reward for the final image and use it to update does this sampling process truly become a reinforcement learning problem.
Translating Diffusion into MDP Language
DDPO (Denoising Diffusion Policy Optimization)'s key observation is: Diffusion's sampling process can be viewed as a finite-length MDP. Black et al.'s DDPO paper explicitly treats denoising as a multi-step decision-making problem, then uses policy gradients to directly optimize downstream rewards[1:2].
This translation is very important. Let's examine each component:
| RL Concept | Diffusion Counterpart |
|---|---|
| State | Current latent, timestep, and prompt: |
| Action | Sampling the next latent, or predicting the denoising direction |
| Trajectory | The complete denoising chain: |
| Reward | Score given by a reward model on the final image |
| Policy | The diffusion model's denoising distribution |
Thus, one generation is like an episode:
In RL, an episode refers to one complete interaction: starting from an initial state, the agent continuously chooses actions, the environment continuously provides the next state, until the task terminates. For example, in CartPole, from when the cart and pole are initialized until the pole falls or the maximum steps are reached, that is one episode. In text generation, from the start token to the end token can also be viewed as an episode.
The significance of an episode is to define the boundary of a "result." It tells us which states and actions belong to the same attempt, and which sequence of decisions should be reviewed for the final outcome. For image generation, looking at any single intermediate latent makes it hard to judge whether it is a "good image." What can truly be scored by human preference models, CLIP scores, aesthetic models, or task rewards is usually the final . So we treat the entire chain from pure noise through step-by-step denoising to as one episode, with the terminal state being the final image.
After the episode ends, the reward model sees the final image and gives a score:
Note that here is not the generation model itself, but a separate scoring model. Its parameters are , while the generation model's parameters are .
With this, the generation model's objective can be written as:
This reads: we want the average reward of the final image, sampled from the model's own trajectories, to be as high as possible.
DDPO: Updating the Denoising Policy with Policy Gradients
With the MDP translation above, DDPO is no longer mysterious. It essentially applies policy gradients on Diffusion sampling trajectories.
Let's first give this derivation a paper coordinate. The table below maps what we are about to do to its classic reference:
| What We Do | Paper Reference |
|---|---|
| Treat one denoising generation as an episode / MDP | DDPO: Black et al., 2024[1:3] |
| High-score samples increase probability, low-score samples decrease it; mathematically called policy gradient | REINFORCE: Williams, 1992[2] |
| Use old/new logprob ratio and clipping to keep each update small | PPO: Schulman et al., 2017[3] |
| Use KL constraint to limit deviation from the reference model | DPOK: Fan et al., 2023[4] |
| Train reward models using human or aesthetic preferences | Pick-a-Pic / HPS v2[5][6] |
The most terminology-intimidating row is the second one. Its plain-language version is simple:
If a denoising trajectory ultimately generates a high-scoring image, make the model more likely to sample the steps in that trajectory in the future; if the final score is low, make those steps less likely to be sampled.
The problem is, training a model requires more than just saying "make it more likely to happen." We need a computable gradient direction. The log-derivative trick in REINFORCE is exactly the step that converts this statement into a trainable formula.
Let's first align the symbols that will appear:
| Symbol | How to Understand It |
|---|---|
| Diffusion model parameters — what training modifies | |
| Prompt | |
| A complete generation trajectory, from denoising to | |
| Probability that the current model samples this trajectory | |
| Score for the final image generated by this trajectory | |
| Average score of the current model; training objective is to make it larger | |
| "Which direction to change parameters so increases" — the gradient |
Let's first write out the probability of one denoising trajectory. To simplify notation, we assume prompt is given:
This formula has two implications. First, the initial noise is usually sampled from a standard Gaussian distribution and does not depend on model parameters . Second, what is truly controlled by the model is each denoising step's distribution .
This product is also intuitive: for the full trajectory to occur, step must sample , step must sample , and so on until is sampled. So the probability of the entire trajectory is the product of each step's probability.
The generation model wants to maximize the final reward:
where , the reward model's score on the final image.
Let's first understand this with a small discrete example. Suppose under the same prompt, the model can only produce three denoising trajectories:
| Trajectory | Probability of model sampling it | Final reward |
|---|---|---|
Then the average reward is:
If 's reward is high, we naturally want to increase. In other words, the intuition behind RL updates is not "directly push image pixels in some direction," but "change the model's sampling probability": increase the probability of high-scoring trajectories and decrease the probability of low-scoring ones.
Real Diffusion has not just three trajectories, but a continuous, enormous number of possible trajectories. Writing the above weighted average as an integral:
This integral need not be too intimidating. It is just "multiply all possible trajectories' probabilities by their scores and add them up." In the discrete case it is ; in the continuous case it is written as an integral.
Now take the gradient with respect to , asking: in which direction should we change model parameters so that average reward increases?
Now the problem: this expression contains , meaning "how does the probability of this complete trajectory change when model parameters change." But during training, we get a batch of trajectories sampled by the model — we cannot enumerate all trajectories. We want to rewrite the gradient as a "mean over sampled trajectories" form, so we can estimate it using actual samples.
Here we use a small identity called the log-derivative trick, also known as the score-function trick. It is the core technique behind REINFORCE-style policy gradient methods[2:1]:
This identity simply rewrites as . The reason is:
Multiplying both sides by :
It sounds like a trick, but it is essentially just an algebraic rearrangement. Its benefit is that reappears in the formula, and this exactly represents "sampling trajectories from the current model." So we can estimate the gradient using actually sampled trajectories.
Substituting back:
That is:
This step is critical because it converts an intractable problem into one that can be estimated by sampling. During training, we only need to do three things:
- Sample a trajectory using the current Diffusion model;
- Score the final image using the reward model to get ;
- Look at this trajectory's log probability under the model, , and increase or decrease it based on the reward.
So policy gradient does not require differentiating through the reward itself. The reward model can be non-differentiable or a black-box scorer; we only need to know "what score did this trajectory get." DDPO exploits exactly this property: rewards can come from aesthetic models, compression rates, VLM feedback, or other objectives that cannot be directly backpropagated[1:4].
Next, expand the trajectory's log probability:
Why take log? Because the original trajectory probability is a product of probabilities. Products are hard to handle when long; taking log converts multiplication into addition:
So the log probability of the entire trajectory equals the sum of each step's log probability.
Since does not depend on , it vanishes when taking the gradient:
So the most basic policy gradient is:
This is REINFORCE applied to Diffusion trajectories[2:2]: if a denoising trajectory receives a high reward, increase the probability of each step's sampled action along that trajectory; if the reward is low, decrease their probability. Black et al.'s DDPO paper applies exactly this approach to Diffusion denoising trajectories[1:5].
Why Can We Subtract a Baseline and Use Advantage?
Updating directly with will have high variance. One prompt may naturally tend to produce high-scoring images, while another is inherently harder. We care more about: is this sample better or worse than similar samples?
Therefore, we can subtract a baseline :
Here is called the advantage. It does not ask "what is this image's absolute score," but "how much better is it than the reference level." If the reward is 8 and the baseline is 6, the advantage is +2, meaning this generation is better than expected; if the reward is 5 and the baseline is 6, the advantage is -1, meaning this generation is worse than expected.
Why can we subtract a baseline? The intuition is: if we subtract the same constant from all scores in a group, the relative ranking doesn't change. What training truly needs is "relatively better" or "relatively worse."
Mathematically, we can verify it does not change the expected gradient. We only need to show: the baseline term that was subtracted averages to zero.
Here is moved outside because it is a fixed number under the same prompt and does not depend on the specific sampled action. Using the same log-derivative trick:
Why is the last line 1? Because means "sum of probabilities over all possible trajectories," which must equal 1. The gradient of 1 with respect to parameters is 0. So subtracting a baseline that does not depend on specific actions does not change the average update direction — it only makes updates more stable.
In practice, can be computed in several common ways:
| Advantage Method | Meaning |
|---|---|
| Subtract the batch mean reward | |
| Subtract the prompt-level historical mean reward | |
| Subtract the value model's prediction for the current state | |
| Normalized reward | Standardize batch rewards for more stable scale |
With advantage, the commonly used DDPO policy gradient becomes:
If using only the terminal reward, each step can share the same . If a value model is trained, different timesteps can have different .
How Does This Match Diffusion's Log Probability?
In many Diffusion implementations, each reverse transition step can be written as a Gaussian distribution:
Here is the denoising mean predicted by the model, and is the noise scale at this step. DDPO's implementation needs to record each step's log probability, which is essentially taking logprob on this reverse transition distribution[1:6]. The log probability of this action is approximately:
This formula has a straightforward interpretation: if the actually sampled is close to the model's predicted mean , the squared distance is small and the log probability is high; if it is far away, the squared distance is large and the log probability is low.
This explains what step.logprob means in pseudocode: it is not an abstract RL symbol, but the log probability that the current model sampled this particular at step .
From Maximizing Objective to Minimizing Loss
Deep learning frameworks typically minimize loss, while policy gradient maximizes . So implementations write it with a negative sign:
Minimizing this loss is equivalent to maximizing the policy gradient objective. Intuitively:
| Case | What the loss pushes |
|---|---|
| Increase the log probability of this step's sampled action | |
| Decrease the log probability of this step's sampled action | |
| Essentially no update at this step |
This is completely consistent with Chapter 5's REINFORCE, except the action has changed from "choosing a token" to "choosing the next latent."
Why Still Need a KL Constraint?
If we only maximize reward, the model easily goes astray. The reason is simple: the reward model itself is not perfect. The model may find patterns that the reward model likes but humans do not truly prefer.
So practical training often keeps a reference model and penalizes the current model for deviating too far from it. DPOK also uses "policy optimization + KL regularization" as the core structure for text-to-image diffusion RL fine-tuning[4:1]:
This formula can be understood in two parts:
| Term | Role |
|---|---|
| Policy gradient term | Makes high-reward sampling trajectories more likely |
| KL term | Prevents the model from straying too far from the original model in pursuit of reward |
This is the same idea as in RLHF, DPO, and GRPO: make the model better, but don't let it fly off.
DDPO's Minimal Training Flow
The derivation above explains "why we can update." Now let's unpack the training process to see clearly: in one DDPO update, how does data flow from prompt to loss.
One sentence to remember:
DDPO does not do supervised learning on existing images. It has the current model generate images itself, uses rewards to judge which generation results are good or bad, and then propagates the good/bad signal back to the sampling trajectories[1:7].
This is its core difference from ordinary diffusion fine-tuning. Ordinary supervised fine-tuning shows the model "what it should generate"; DDPO shows the model "among the results you generated, which ones are more worth becoming more likely."
Step 1: Take a Batch of Prompts
The first step is not to take images, but prompts:
where is the batch size and is the -th prompt.
Prompt data quality directly affects training direction. If prompts are too simple, the model may only learn to improve general aesthetics; if prompts contain fine-grained constraints on count, color, position, and relationships, the reward model has the opportunity to train the model's instruction-following ability.
In practice, a good prompt batch often mixes several types:
| Prompt Type | Training Role |
|---|---|
| Simple scene prompts | Stabilize base generation quality |
| Multi-attribute prompts | Train details like color, material, count |
| Spatial relationship prompts | Train left/right, up/down, occlusion, relative position |
| Long instruction prompts | Train instruction-following under complex conditions |
| Benchmark-style prompts | Align training objectives with final evaluation |
This step may seem ordinary but is critical: RL can only optimize the model's behavior on the distribution of these prompts. If the prompt distribution is too narrow, the model may only improve in narrow scenarios.
Step 2: Rollout with the Current Model
The second step is generating images with the current Diffusion model. In RL, this step is typically called rollout, meaning letting the policy run a trajectory.
For each prompt , the model starts from noise and samples a complete denoising chain:
There is a detail easily overlooked: during training, we cannot just save the final image — we must also save key information from each denoising step.
| What to Save | Why |
|---|---|
| Later need to recompute this step's log probability | |
| This is the actual action sampled at step | |
| For PPO-style updates, need old logprob | |
| Final image or decoded image | Reward model needs to score the final result |
Why does appear? Because the model used for sampling is the pre-update model. By the time we do the gradient update, model parameters are about to change. To know "how much the new model changed the action probability relative to the old model," we often need to save old logprobs.
If doing only the most basic REINFORCE update, we can directly use the logprobs from sampling. But in real training, to improve sample utilization, we typically do multiple update epochs on the same rollout batch, and old logprobs become important. This old/new policy ratio idea comes from PPO[3:1], and DDPO's importance-sampling variants also follow this "fix rollout, then use probability ratio to correct updates" approach[1:8].
Step 3: Score Final Results with Reward Model
The third step hands the generated images to the reward model:
Important note: the reward model only scores — it does not necessarily participate in backpropagation. Policy gradient needs "what score did this trajectory get," not the gradient of reward with respect to pixels or latents.
This is also an advantage of DDPO over differentiable reward backpropagation: rewards can come from very complex systems, such as VLM judges, human preference models, rule checkers, or even combinations of multiple models. As long as a scalar score can be produced, it can serve as a policy gradient signal. In contrast, work like DRaFT and VADER uses differentiable reward gradients to directly backpropagate into image or video diffusion models[7][8].
A common reward computation flow:
- Decode latent into an image.
- Use a text-image alignment model to check prompt compliance.
- Use a preference or aesthetic model to score visual quality.
- Use rules or VLM to check hard constraints like count, color, and spatial relationships.
- Combine to get the final reward .
The biggest risk at this step is unstable reward scales. For example, some rewards are in , others in ; directly adding them may let one term dominate training. Therefore, practical training often applies clipping, normalization, or hierarchical filtering.
Step 4: Convert Rewards to Advantages
The fourth step computes advantages from rewards. The simplest approach is batch-level centering:
For even more stable scaling, divide by standard deviation:
After this, means the -th image is better than the batch average, and means it is worse.
Why not use directly? Because absolute scores are often hard to interpret. One prompt may be inherently difficult, where generating a 0.6 score is already good; another prompt may be simple, where 0.8 is only average. Advantage cares about "relative performance," so training is more stable.
In more complete implementations, a value model can also be trained:
Then used as:
This way different timesteps can have different advantages. But for introductory understanding of DDPO, batch mean baseline is sufficient to grasp the core.
Step 5: Compute Policy Gradient Loss
The fifth step is where the Diffusion model is actually updated.
First, the minimal REINFORCE loss. It does one thing: multiply "this trajectory's log probability" with "how good this trajectory is."
This formula can be read at three levels:
| Formula Part | Meaning |
|---|---|
| Log probability that the model sampled this denoising action at step | |
| How much better the -th image is than average | |
| Leading negative sign | Because the optimizer minimizes loss by default, and we want to maximize good trajectory probability |
If , this image is better than average; minimizing loss increases the log probability of each action along this trajectory. If , this image is worse than average; minimizing loss decreases the log probability of these actions.
Many implementations also use PPO-style importance ratios. This ratio and the subsequent clip objective correspond to PPO's core stabilization design[3:2]:
This represents: how much the new model increased the probability of the same denoising action relative to the old model. For example, means the new model makes this action approximately 20% more likely; means it makes it less likely. In implementation, logprob subtraction followed by exp is used because logprobs are more stable and easier to save during sampling.
Then the clipped objective:
The clip limits overly aggressive updates. Assuming , the ratio is typically constrained to around . Even if an image has a very high reward, the new model is not allowed to drastically increase any single action's probability in one step.
The min in this formula can also be read as: when the update direction is favorable, only allow limited benefit; beyond the clip range, further increasing the ratio does not improve the objective. This prevents the model from suddenly shifting due to a small batch of high-scoring samples. Applied to Diffusion, this means don't let one reward update push the denoising distribution too far from the original model; both KL regularization and ratio clipping control this[3:3][4:2].
Step 6: Add KL Regularization and Update Parameters
The final step combines the policy gradient loss, KL regularization, and other stabilization terms:
where:
is typically the base Diffusion model from before RL started. It serves as an anchor, preventing the model from drifting too far in pursuit of the reward model's preferences.
The KL term can be understood as "the distance between two probability distributions." If the current model's denoising distribution at a step is close to the reference model's, KL is small; if the current model gives a very different distribution to chase reward, KL is large. controls the penalty weight: large means the model is more conservative; small means the model more aggressively pursues reward.
At this point, standard backpropagation is executed:
- Compute total loss.
loss.backward()to get gradients.- Clip gradients to prevent explosion.
optimizer.step()to update the Diffusion model.- Move to the next batch of prompts and repeat rollout and update.
Combining the six steps above, we get pseudocode closer to real training. It is not a line-by-line reproduction of any specific repository, but places DDPO's rollout/reward update[1:9], PPO's clipped objective[3:4], and DPOK's KL constraint[4:3] in the same minimal training framework:
for prompts in prompt_loader:
# Step 1-2: rollout with the current policy
with torch.no_grad():
trajectories = diffusion.sample_trajectories(
prompts,
return_states=True,
return_actions=True,
return_logprobs=True,
)
old_logprobs = trajectories.logprobs
images = decoder(trajectories.final_latents)
# Step 3: score final images
with torch.no_grad():
rewards = reward_model(prompts, images)
# Step 4: turn rewards into advantages
advantages = (rewards - rewards.mean()) / (rewards.std() + 1e-6)
# Step 5-6: update the diffusion policy
for _ in range(update_epochs):
logprobs = diffusion.logprob(
states=trajectories.states,
actions=trajectories.actions,
prompts=prompts,
)
ratio = torch.exp(logprobs - old_logprobs)
unclipped = ratio * advantages[:, None]
clipped = ratio.clamp(1 - eps, 1 + eps) * advantages[:, None]
policy_loss = -torch.minimum(unclipped, clipped).mean()
kl_loss = diffusion.kl_to(reference_model, trajectories, prompts)
loss = policy_loss + beta * kl_loss
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(diffusion.parameters(), max_norm)
optimizer.step()This code has one more engineering detail than the earlier math formulas: sampling and updating are separated. Sampling uses the old model, so old_logprobs must be saved; updating recomputes logprobs with the current model, then uses the ratio to determine how much the new model changed relative to the old model.
If we compress DDPO into one engineering intuition:
For the same batch of prompts, let the model generate its own samples; rank the generation results by reward; increase the probability of good samples' denoising trajectories, decrease the probability of bad samples' trajectories, while using KL and clipping to prevent the model from shifting too aggressively.
Reward Model: The Real Bottleneck in Generation RL
At this point, the algorithm is in place. But the difficulty of generation RL often lies not in "can we write policy gradients," but in "is the reward actually trustworthy?"
If the reward model is too weak, it provides no useful direction; if it is biased, the generation model learns the bias; if the reward is too complex, different objectives may pull against each other.
Visual generation rewards typically come from three types of signals.
Type One: Human Preference
The most common form of human preference data is pairwise comparison. Given the same prompt, users choose which of two candidate images they prefer. Pick-a-Pic is a representative publicly collected text-to-image user preference dataset, and HPS v2 further provides a human-preference-oriented evaluation benchmark and reward model[5:1][6:1].
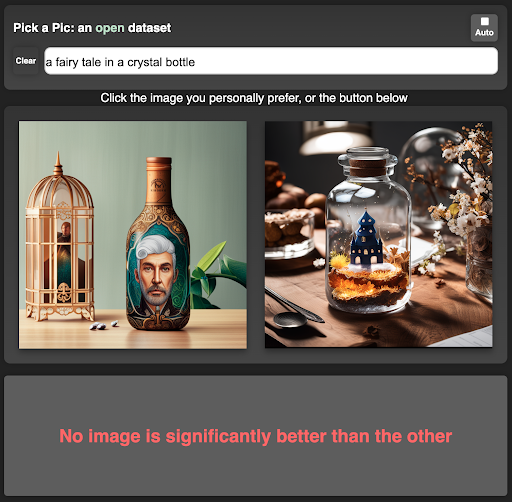
Pick-a-Pic's contribution is not just providing UI screenshots, but organizing large-scale text-to-image pairwise preference data into trainable, evaluable public resources[5:2].
Such data can be written as:
where is the user-preferred image and is the rejected image. The reward model's training objective typically makes 's score higher than 's:
This is Bradley-Terry style preference modeling. It does not require humans to give absolute scores — only to compare which of two images is better. Datasets like Pick-a-Pic use exactly this pairwise preference to train or evaluate image preference models[5:3].
This signal's advantage is proximity to real user preferences. The disadvantage is high cost, and preference data inherits the aesthetics, culture, and task distribution of the annotator population.
Type Two: Text-Image Alignment
Text-image alignment checks whether the image truly matches the prompt. This can be decomposed from coarse to fine:
| Level | Example | Possible Check Methods |
|---|---|---|
| Global semantics | Does it roughly generate the specified scene | CLIP Score, VLM judgment |
| Object presence | Do key objects from the prompt appear | Detectors, VLM QA |
| Attribute matching | Are colors, materials, sizes correct | Fine-grained caption then item-by-item comparison |
| Relationship matching | Are left/right, up/down, occlusion, interaction correct | Relationship extraction, VLM judge |
| Count matching | Is the specified count correct | Counting models, object detection, VLM check |
This level connects directly with the VLM RL from previous sections. A VLM trained to better understand images can serve as a captioner, judge, or reward model, helping the generation model judge "was it drawn correctly."
Type Three: Visual Quality
Visual quality checks whether the image itself is natural, clear, with good composition and lighting. Common signals include aesthetic scores, no-reference image quality assessment, and human ranking. Benchmarks like HPS v2 attempt to make "which generation results humans prefer" into reproducible evaluation and model signals[6:2].
It is very useful, but cannot be used alone. Visual quality models typically reward images that "look premium" rather than "strictly follow the prompt." A generation model chasing only this score may become prettier but less obedient.
Reward Is Not Better Just Because the Formula Is More Complex
Weighted-summing all rewards is natural:
But this formula is only a starting point, not an answer. The biggest problem with multi-component rewards is: each component can be exploited by the model, and components may conflict with each other.
A more stable engineering approach is to use rewards hierarchically:
- First use rules or VLM to check hard constraints, such as count, color, and object satisfaction.
- Then use preference models to rank passing samples.
- Finally use manual spot-checks or offline benchmarks to find the reward model's blind spots.
This way, reward is no longer a universal score, but a filtering and calibration pipeline.

Two Ways to Use Reward: During Training or During Inference?
Having a reward model does not mean immediately doing RL fine-tuning. There are two common usage patterns.
The first is inference-time use, also called reward-guided sampling or reranking. For example, generate images for the same prompt, rank them with the reward model, and select the highest-scoring one. This method is simple, safe, and suitable for first validating whether the reward model is reliable.
The second is training-time use, which is RL fine-tuning like DDPO and DPOK[1:10][4:4]. The model is not just filtered — its parameters are actually updated, internalizing preferences into the generation policy.
| Method | What It Does | Advantage | Disadvantage |
|---|---|---|---|
| Best-of- / reranking | Generate more, then select with reward model | Simple to implement, no model changes | High inference cost, capability not internalized |
| Reward-guided sampling | Use reward to guide direction during sampling | More active than pure reranking | Still requires extra evaluation per generation |
| RL fine-tuning | Use reward to update model parameters | Can internalize preferences | More expensive training, more prone to instability |
In practice, reranking is often done first. If the reward model cannot even rank well, it should not be used directly for RL.
Video Generation: Same Problem, One More Time Axis
Video generation can be viewed as an extension of image generation, but cannot be simply understood as "generating more images." Video adds a time axis, so rewards need an additional layer. Work like Emu Video separates image conditioning and video generation[9]; subsequent video alignment work explores using reward gradients or MLLM feedback to optimize video generation results[8:1][10].
A video must simultaneously satisfy three things:
- Every frame must be clear, natural, and match the prompt.
- Adjacent frames must be coherent; the subject cannot suddenly change.
- The entire video must express the event sequence in the prompt.
Therefore, video rewards are often written in a hierarchical form. This is not a fixed formula from any particular paper, but abstracts three common evaluation signals — single-frame quality, temporal consistency, and overall event alignment — into one reward:
These three components correspond to:
| Component | What It Checks |
|---|---|
| Single-frame quality and single-frame text alignment | |
| Inter-frame consistency and motion naturalness | |
| Whether the entire video completes the prompt's events |
Video RL's difficulties also increase:
| Challenge | Why Harder | Common Mitigation |
|---|---|---|
| Temporal consistency | Individual frames being good doesn't mean they're coherent together | Optical flow consistency, trajectory consistency, video VLM evaluation |
| Long horizon | Video token and latent counts far exceed images | Segmented optimization, short-clip reward shaping |
| Computational cost | Each sampling and scoring is more expensive | Latent-space training, low-frame-rate evaluation, candidate reranking |
| Text-video alignment | Prompt may include sequential order | Segmented captions, event-level rewards |
Intuitively, image generation errors are often "something was drawn wrong"; video generation errors are often "continuity was broken." This is why video rewards rely more on segment-level and overall-level evaluation.
On-Policy Distillation: Solidifying RL-Acquired Capabilities
A model after RL fine-tuning may better match preferences, but it may also be slower, more expensive, or only suited for a specific sampling setup. On-policy distillation's goal is to turn the high-quality samples produced by the RL-trained model on the current distribution back into cheaper supervised learning signals.
This can be understood in three steps:
- Use the RL-trained teacher model to generate samples online.
- Use the reward model or rules to filter and keep high-quality samples.
- Have the student model learn from these samples, reproducing the teacher's behavior at lower cost.
This is consistent with the distillation idea from Chapter 8: the strong model handles exploration and filtering, the weak model compresses capabilities into cheaper inference paths. The difference is that visual generation distillation typically occurs in latent, denoising trajectory, or video token space, rather than ordinary text token space.
Connections to Previous Chapters
Visual generation RL may seem far from VLM QA, but it reuses several main threads from earlier in the book.
| Earlier Chapter | Correspondence in Visual Generation RL |
|---|---|
| Chapter 5 REINFORCE | DDPO treats denoising chains as policy trajectories, updating each step's sampling with terminal reward |
| Chapter 7 Reward Hacking | Generation models may please the reward model while sacrificing real user intent |
| Chapter 8 RLVR | Fine-grained attributes, counts, relationships can become locally verifiable signals |
| Chapter 10 Agentic RL | Long-horizon credit assignment, multi-component rewards, and KL constraints reappear |
| Sections 11.1-11.3 VLM RL | VLMs can in turn serve as judges, captioners, and reward models for generation models |
The last point is especially important. Understanding models and generation models are not two completely separate threads. After VLMs learn to see images better, they can check whether generated images match prompts; generation models can synthesize richer data to train VLMs in turn. In the multimodal post-training stage, "seeing" and "generating" will increasingly form a closed loop.
Summary
Visual generation RL's goal is not simply to make the model "draw prettier," but to decompose user intent into learnable feedback signals, enabling the generation model to continuously improve under preferences, rules, and multimodal evaluation.
This section's four most important conclusions:
- Diffusion can be viewed as an MDP: denoising trajectories are episodes, the final image receives a reward, and policy gradients distribute the reward back to each step.
- DDPO's core is a translation problem: treating denoising probabilities as policies and final image scores as rewards enables the use of policy gradients.
- Reward models are the bottleneck of generation RL: human preferences, text alignment, and visual quality are all important, but reward hacking must be prevented.
- Rewards can be used at both training and inference time: reranking is safer, RL fine-tuning better internalizes capabilities, and video generation further amplifies temporal and computational challenges.
With this, we have covered both understanding and generation directions of VLM RL training. The next chapter enters broader frontier trends: Embodied Intelligence, Self-Play, and Offline RL.
References
Black, K., Janner, M., Du, Y., et al. (2024). Training Diffusion Models with Reinforcement Learning. ICLR. https://arxiv.org/abs/2305.13301 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Williams, R. J. (1992). Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine Learning. https://doi.org/10.1007/BF00992696 ↩︎ ↩︎ ↩︎
Schulman, J. et al. (2017). Proximal Policy Optimization Algorithms. https://arxiv.org/abs/1707.06347 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Fan, Y., Watkins, O., Du, Y., et al. (2023). DPOK: Reinforcement Learning for Fine-tuning Text-to-Image Diffusion Models. NeurIPS. https://arxiv.org/abs/2305.16381 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Kirstain, S. et al. (2023). Pick-a-Pic: Open Dataset of Human Preferences for Text-to-Image Generation. NeurIPS. https://arxiv.org/abs/2305.01569 ↩︎ ↩︎ ↩︎ ↩︎
Wu, X. et al. (2023). Human Preference Score v2: A Benchmark for Evaluating Human Preferences of Text-to-Image Synthesis. NeurIPS. https://arxiv.org/abs/2306.09341 ↩︎ ↩︎ ↩︎
Clark, K. et al. (2024). Directly Fine-Tuning Diffusion Models on Differentiable Rewards. ICLR. https://arxiv.org/abs/2309.17400 ↩︎
Prabhudesai, M. et al. (2024). Video Diffusion Alignment via Reward Gradients. https://arxiv.org/abs/2407.08737 ↩︎ ↩︎
Girdhar, R. et al. (2024). Emu Video: Factorizing Text-to-Video Generation by Explicit Image Conditioning. ECCV. https://arxiv.org/abs/2311.10709 ↩︎
Wu, X. et al. (2024). Boosting Text-to-Video Generative Model with MLLMs Feedback. NeurIPS. https://neurips.cc/virtual/2024/poster/96722 ↩︎