A Brief History of Reinforcement Learning
If you asked an AI researcher in the early 2010s, "What is reinforcement learning?", they would probably draw a feedback loop of an agent interacting with an environment, and tell you it is mostly used for robotics control and board games.
But if you rewind the clock by a century, or fast-forward to today's era of large models, you will find that reinforcement learning (RL) has gone through a dramatic evolution. It began with behavioral experiments in psychology, and gradually grew into a core engine behind some of the most advanced AI systems we have today.
Before we jump into code, it is worth spending a few minutes on this timeline. These milestones explain why modern RL algorithms look the way they do.
1. Origins and Foundations: From Psychology to Mathematical Frameworks (1890s-1950s)
The earliest ideas behind RL did not come from computer science. They came from psychology and neuroscience.
In 1898, psychologist Edward Thorndike proposed the Law of Effect based on his famous "puzzle box" experiments with cats: behaviors that lead to satisfying outcomes tend to be reinforced; behaviors that lead to unpleasant outcomes tend to be weakened. This is the root of trial-and-error learning.
Half a century later, the rise of cybernetics and control theory pushed these instincts into rigorous mathematics. In 1957, Richard Bellman introduced the Markov Decision Process (MDP) and the Bellman equation. He used a 5-tuple to turn sequential decision problems into a precise mathematical object:
- : the state space
- : the action space
- : transition probabilities
- : the reward function
- : the discount factor
Under this framework, an agent seeks a policy that maximizes the expected discounted return:
To measure how good a policy is, Bellman introduced value functions. denotes the expected return starting from state and following policy . Among all policies, the best one corresponds to the optimal value function , which satisfies the Bellman optimality equation:
This equation is profound: the optimal value at the current state equals immediate reward plus the discounted expectation of future optimal values. It transforms an apparently infinite-horizon decision problem into a solvable recursion. This is the conceptual foundation of dynamic programming, and it gave RL a solid theoretical base.
2. Theory Takes Shape: Temporal-Difference and Model-Free Learning (1980s-1990s)
Bellman's dynamic programming is mathematically clean, but it has two fatal practical limitations.
- It assumes you know the environment dynamics: you must have and in advance. In the real world, a robot does not know what lies behind a door, and a game-playing agent does not know the opponent's next move.
- It suffers from the curse of dimensionality: solving Bellman equations requires enumerating states, but the number of states often grows exponentially with problem complexity. For Go, the number of possible board positions is about , far beyond any explicit table.
To learn in unknown environments without full state tables, researchers developed new ideas.
In 1988, Richard Sutton proposed temporal-difference learning (TD). TD combines Monte Carlo sampling with the bootstrapping nature of dynamic programming. Its core update rule is simple:
The TD error measures how the new estimate differs from the old one. If the next step turns out better than expected (), increase the current value; otherwise decrease it. This "learn while you act" mechanism is one of the core ideas of modern RL.
In 1989, Chris Watkins introduced Q-learning, one of the most widely taught model-free, off-policy RL algorithms. Its update rule is:
The key is the term: Q-learning learns the optimal action-value function directly, without needing a model of the environment.
In 1995, Gerald Tesauro demonstrated the practical power of these ideas with TD-Gammon, a backgammon program trained with TD learning that reached (and arguably exceeded) expert human level. This was one of the first widely recognized successes of RL with function approximation.
3. The Deep Learning Era: From DQN to AlphaGo (2013-2018)
Classic RL algorithms like Q-learning assume you can store values in a table. Deep learning changed the game by letting us approximate value functions and policies with neural networks.
In 2013, DeepMind introduced DQN (Deep Q-Network), combining Q-learning with deep convolutional networks to learn directly from pixels. DQN achieved human-level performance on many Atari 2600 games with the same algorithm and architecture, marking a turning point: RL could scale to high-dimensional inputs with minimal hand-engineering.
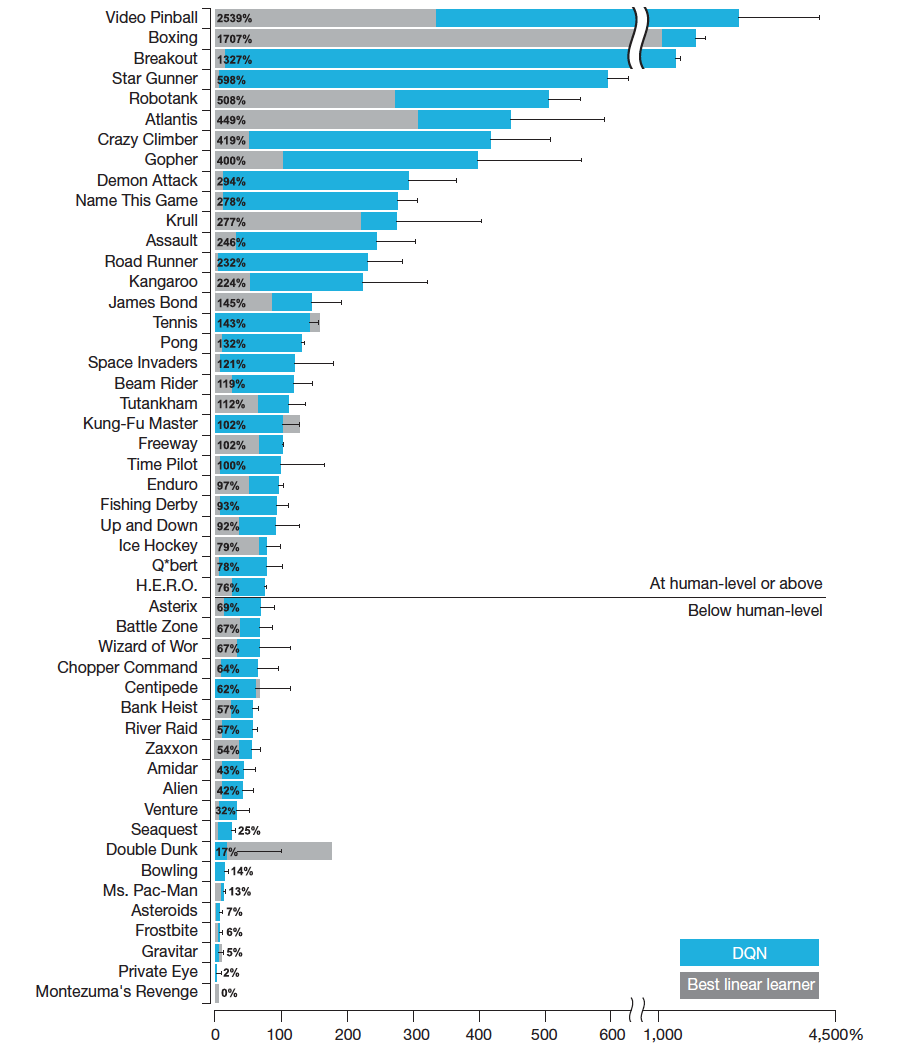
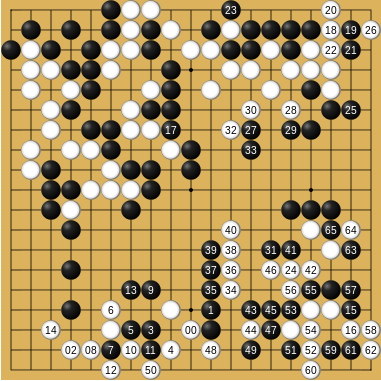
In 2016, DeepMind's AlphaGo combined deep RL with Monte Carlo Tree Search and defeated world champion Lee Sedol 4:1. This event brought RL into the public spotlight with an unmistakable impact.
In 2017, OpenAI introduced PPO (Proximal Policy Optimization). Compared to early policy-gradient methods, PPO found a practical balance between training stability and sample efficiency. Its central idea is to limit the size of each policy update via clipping, preventing the infamous "step too large, training collapses" failure mode:
Here, the ratio compares the new policy against the old one, is an estimate of the advantage function, and is typically 0.1 to 0.2. The clipping behaves like a guardrail: each update is allowed to move, but not too far. PPO quickly became a default workhorse in industry, and OpenAI later used large-scale PPO-based systems (for example, OpenAI Five) to reach world-champion level in Dota 2.
4. The LLM Era: New Paradigms for Alignment and Reasoning (2020s-Present)
Just when it seemed RL might stay mostly within games and robotics, large language models (LLMs) gave RL a new mission: alignment and reasoning.
In 2022, OpenAI released ChatGPT. A key ingredient behind its instruction-following behavior was RLHF (Reinforcement Learning from Human Feedback). The standard RLHF recipe trains a reward model to approximate human preference, then uses PPO to optimize a language-model policy:
The KL penalty term keeps the policy from drifting too far away from a reference model, which is essential for preventing reward hacking.
In 2023, researchers introduced DPO (Direct Preference Optimization). The key insight is that you can bypass the explicit reward-model training step and directly fine-tune the policy on preference pairs using a simple classification-like loss. DPO can be derived from the RLHF objective:
Here, (winner) and (loser) are the preferred and dispreferred completions, and is the sigmoid function. DPO significantly lowers the engineering barrier of RLHF and became widely adopted in open-source post-training workflows.
From 2024 to 2025, reasoning-focused models (e.g., OpenAI o1 and DeepSeek-R1) brought another shift. In tasks with objective rules (math correctness, code compilation), it became increasingly clear that you can sometimes skip a supervised warm start and train with pure RL directly from a base model.
In particular, DeepSeek-R1-Zero demonstrated that with verifiable reward signals, pure RL can lead to the emergence of long chains of thought and even distinct "a-ha" moments. Their GRPO (Group Relative Policy Optimization) approach removes the critic network used in PPO, and instead uses group-normalized relative rewards to build an advantage-like signal. For a prompt , sample a group of responses and normalize rewards:
Then optimize a clipped objective similar in spirit to PPO:
This lightweight design avoids training a separate critic network and uses the relative ranking within a group to drive learning, making large-scale reasoning RL more practical on clusters.
Takeaway
From Thorndike's puzzle box, to Bellman's equations; from DQN on Atari, to today's fast-iterating post-training pipelines with DPO and GRPO: the history of RL is the story of agents that learn from environments, evolve from feedback, and scale from small systems to giant models.
RL is no longer a niche theoretical toy. It is one of the most direct roads toward generally capable AI systems. In the chapters ahead, we will follow this history from the first line of code and implement these algorithms ourselves.