4.1 Why DQN Is Needed
Section Guide
Core ideas
- Review how tabular Q-Learning updates action values using a TD target.
- Understand the hidden assumption behind a Q-table: "states can be enumerated."
- See why DQN represents with a neural network, and why a naive replacement creates new stability problems.
Key formulas
Q-Learning update rule
- : the old estimate stored in the table for the state-action pair.
- : the TD target built from immediate reward plus next-state optimal value.
- : learning rate controlling how far we move toward the TD target.
TD target
- : the observed immediate reward.
- : the estimated best discounted return from the next state.
TD error
- : the old estimate is too small, push it up.
- : the old estimate is too large, push it down.
- : the old estimate matches this target.
Q-Learning, Revisited (as a Table)
Chapter 3 introduced the action-value function and tabular Q-Learning. Here we focus on its implementation form: the algorithm stores one value per state-action pair, and updates one entry per step.
The update rule is:
Read it as: "use one new experience to correct one old number."
First, construct the TD target:
Then subtract the old estimate:
Finally, move a step of size toward the target. This is important: we do not overwrite the old estimate completely, because a single transition can be noisy.
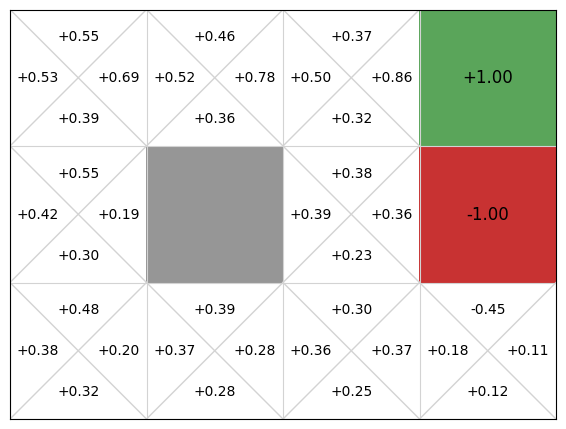
At the start, the whole table can be zeros. The agent walks, and each step updates exactly one cell. Over time, values near the goal become accurate earlier; via the term, those values propagate backward. In the end, the policy is not hand-written. It emerges from the table: take the action with the largest at each state.
This works because of an assumption we rarely say out loud:
the table must be able to hold all state-action pairs.
In a tiny GridWorld, that's just dozens of numbers. Once the state space is large or continuous, the story changes.
Where Q-Tables Break
A Q-table is both the memory of Q-Learning and its limit. As long as all states can be listed as a finite set of rows, "look up, update, and take a max" are straightforward. Once states cannot be enumerated, the implementation collapses.
Let's look at discrete states first. A coin flip has 2 states, so the table is tiny. Tic-tac-toe has about board configurations, still feasible. Chess has about legal positions; Go has about . These numbers are not just big. They are astronomically beyond any storage.
But these are still discrete spaces. In principle, you could "name" every state. The real boundary appears with continuous states.
In LunarLander, the state is an 8D vector: position, velocity, angle, angular velocity, and two leg-contact indicators. The first 6 dimensions are continuous real values. As soon as one dimension can take infinitely many values (say ), the full state set becomes infinite.
You can force discretization, but it explodes. If you split each of 6 continuous dimensions into 50 bins, you get states. Multiply by a small action set and you are already at tens of billions of table entries, for a low-dimensional control task.
If you move to Atari, it becomes even more obvious. A state is an image. A single pixel difference is a different state. A table is hopeless.
So we need a different representation.
Replacing the Table With a Neural Network
The natural replacement is function approximation: use a neural network to represent the action-value function.
Instead of storing in a table, we train a network . It takes a state as input and outputs a vector of Q-values, one per action.
This turns a table of unrelated numbers into a set of shared parameters . Similar states no longer have to be learned from scratch: they can share structure through the network.
This idea is older than DQN. What made DQN a turning point is: it made this idea trainable and stable enough to work at scale (notably on Atari).
Why the Naive Replacement Still Fails
At this point we have solved only the "the table does not fit" problem. A tempting next step is:
Replace every table lookup in Q-Learning with network outputs, and train by gradient descent.
This is the starting point, but not the full answer. Two training issues appear immediately:
- samples are highly correlated along trajectories
- the TD target moves because it depends on the network itself
Correlated samples
In Atari, adjacent frames are extremely similar. If you train on the last 32 steps as a batch, you do not have 32 independent situations. You have one situation with tiny consecutive changes. That makes the gradient direction dominated by the most recent experience segment.
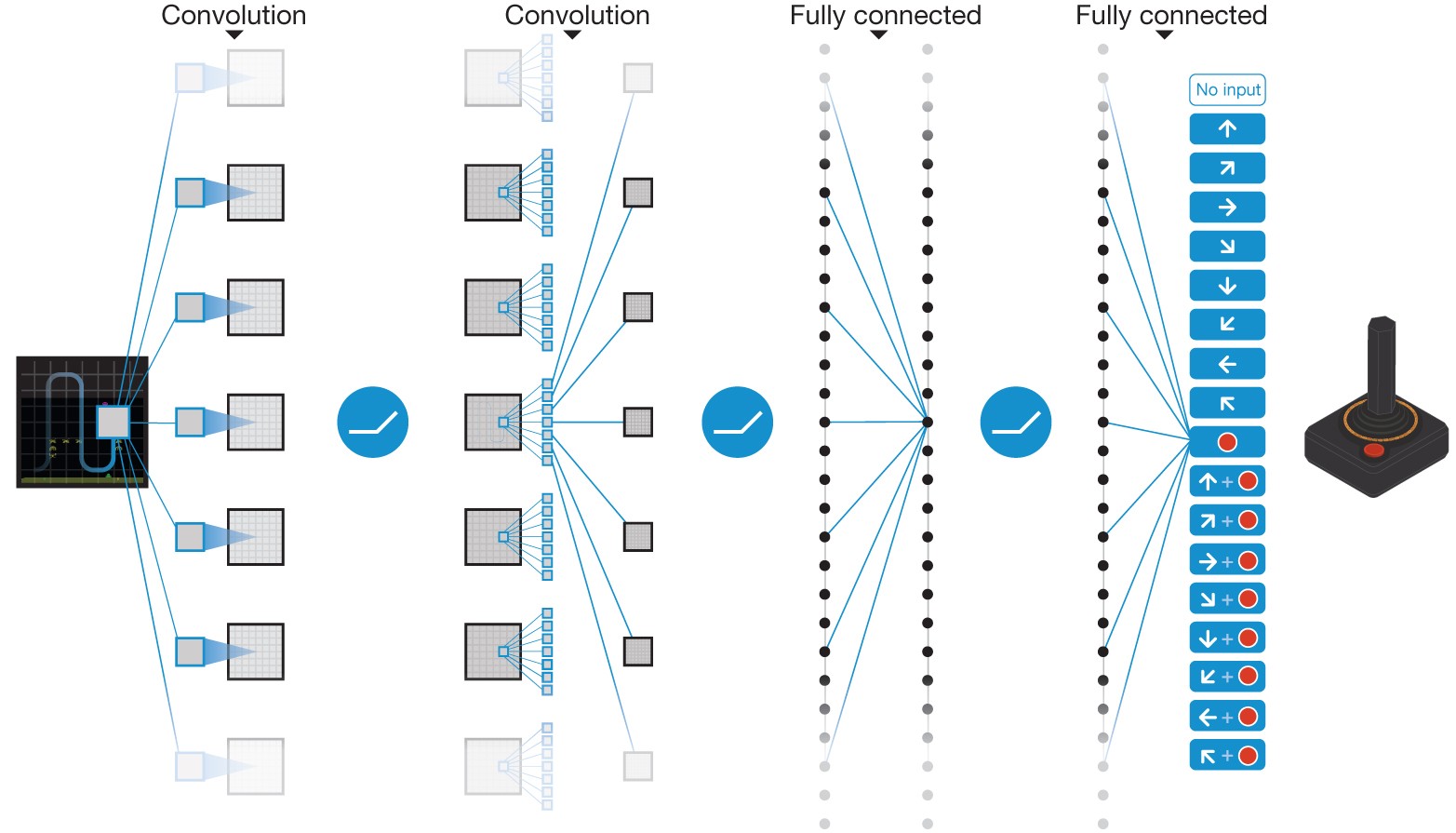
This points to the first stabilization component: do not train only on the most recent steps. Train on random samples drawn from a larger set of past experience.
Moving targets
Q-Learning uses the TD target:
In a table, updating changes one entry; it does not directly change the values used for elsewhere. In a neural network, all Q-values come from the same parameters . A gradient update that changes can also change . The target depends on the network, so the network is chasing a target that moves as it learns.
Here is a minimal example. Suppose there are 2 states and 2 actions, , and the current network outputs:
Now we observe transition . The TD target is:
So the update pushes toward 8.92. After a parameter update, other values may also change:
Notice : it dropped from 8.0 to 6.3. Next time we compute a target from , the "label" has shifted. This feedback loop can cause oscillation or divergence.
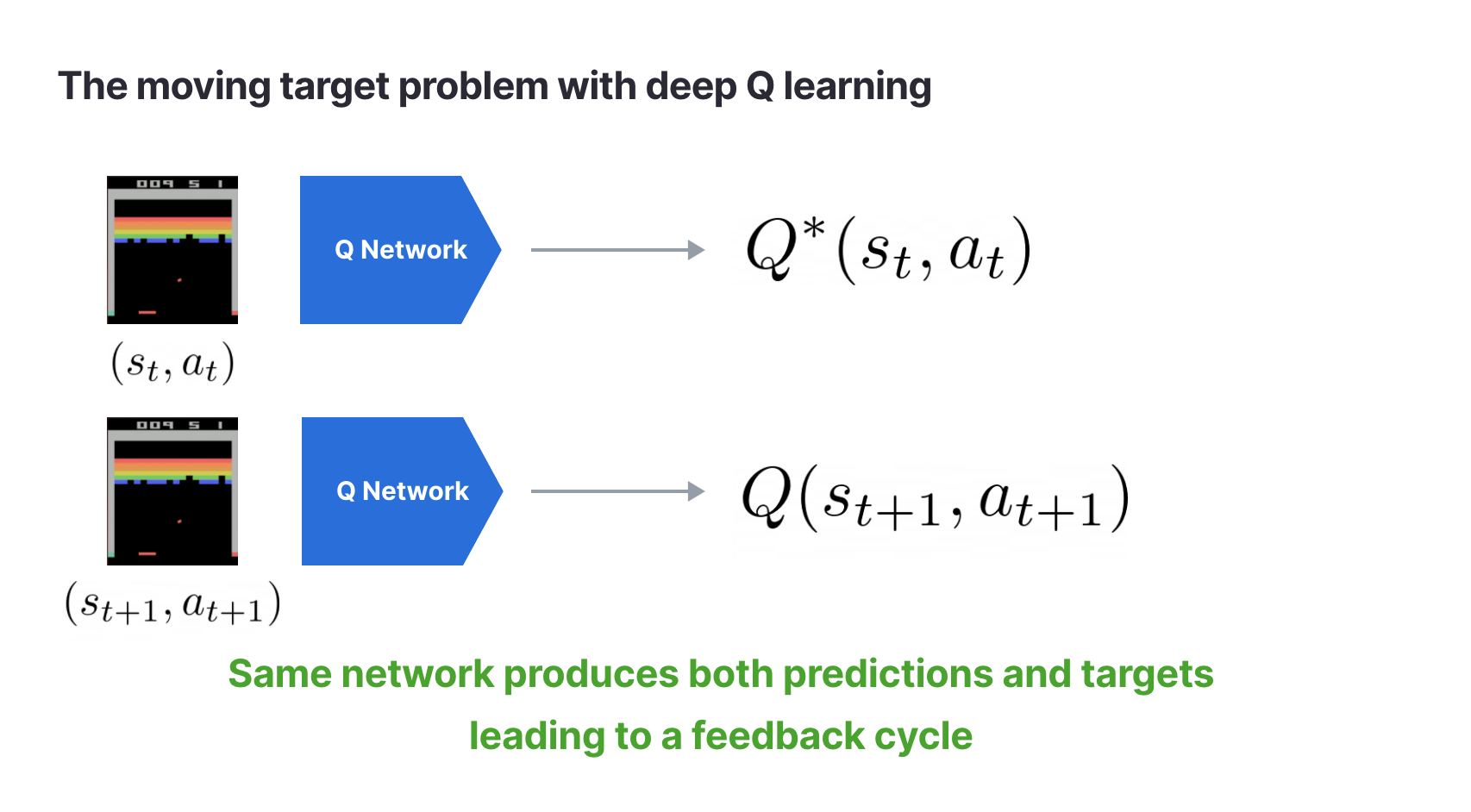
So the naive neural-network Q-Learning inherits at least two instability sources:
- correlated training data along trajectories
- bootstrapped targets that move with the network
This is why DQN is not "just replace table with a network". DQN organizes the idea into three components:
- Q-network: represents
- experience replay: breaks sample correlation and improves data reuse
- target network: slows down target drift by using a delayed copy for the TD target
In other words: this section explains why we need DQN. Next section explains how DQN actually builds these components into a trainable algorithm.
Next: DQN architecture: Q-network, replay buffer, target network.