11.3 VLM RL Frameworks and Frontiers: The Bridge from Experiments to Applications
In the previous two sections we ran VLM GRPO experiments and analyzed the unique challenges of VLM RL. Those discussions focused mainly on the "problem" level — how to do reward attribution, how to prevent visual hallucination, whether to update the visual encoder. This section looks at "solutions" — what frameworks are currently addressing these problems systematically, and where VLM RL may be headed.
11.3.1 VisPlay: Co-Evolution of Questioner and Reasoner
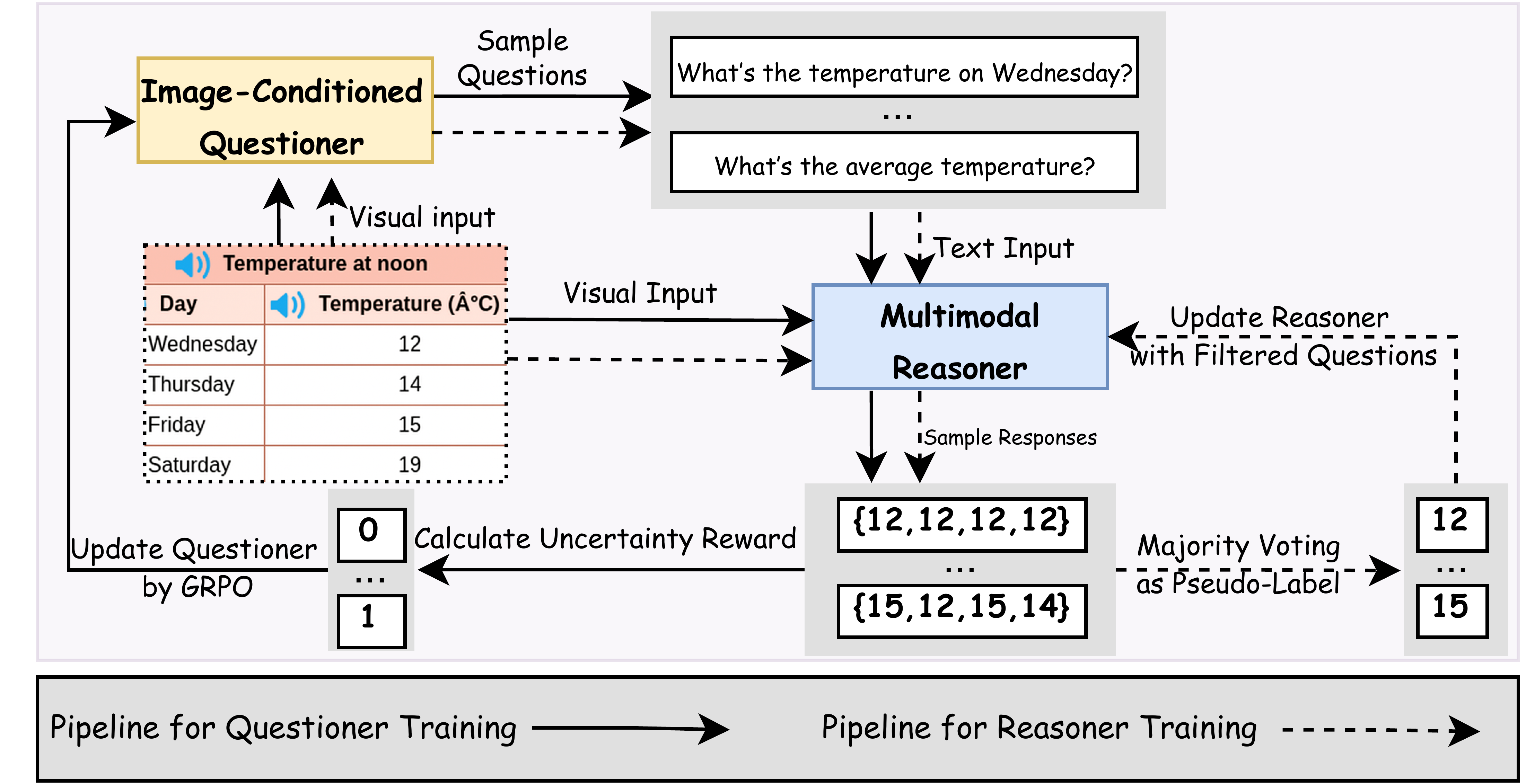
VisPlay is a creative VLM RL framework whose core idea is to let two models play against each other and co-evolve through RL — one generates questions (Questioner), the other answers them (Reasoner). This follows the Self-Play idea discussed in Chapter 8, but is specifically designed for visual scenarios.
Dual-Model Architecture
The Questioner's task is to generate challenging visual questions. Its input is an image, and its output is a question about the image's content. Good questions must satisfy two conditions: the current Reasoner cannot yet answer them well (they are challenging), and the answer can be determined from the image alone (there is an objective standard).
The Reasoner's task is to answer the Questioner's questions. Its input is an image plus a question, and its output is an answer. As in the VLM GRPO experiments from the previous section, the Reasoner is optimized through RL for answer quality.
The co-evolution of the two models forms a positive feedback loop: the Questioner generates increasingly difficult questions → the Reasoner is forced to improve to answer them → the Questioner must produce even trickier questions to "stump" the Reasoner → the Reasoner continues improving. This loop is structurally identical to AlphaGo's self-play (recall Chapter 5) — driving evolution by continuously raising the opponent's strength.
VisPlay's reward design is also interesting. The Questioner's reward depends on the Reasoner's performance — if the Reasoner answers correctly, the question was too easy, and the Questioner gets a negative reward; if the Reasoner answers incorrectly, the question was challenging, and the Questioner gets a positive reward. But there is a balance issue: if the Questioner asks an unanswerable question (e.g., about details that do not exist in the image), the Reasoner's failure should not count as the Questioner's success. So the Questioner's reward also needs an "answerability" constraint — the question must be about something that genuinely exists in the image.
The Reasoner's reward is similar to the previous section — answer correctness, reasoning quality, format compliance — with one additional dimension: response speed (inference efficiency). In deployment, VLM inference latency directly affects user experience, so the model is encouraged to generate concise and efficient responses.
11.3.2 VISTA-Gym: A Tool-Integrated Visual RL Environment
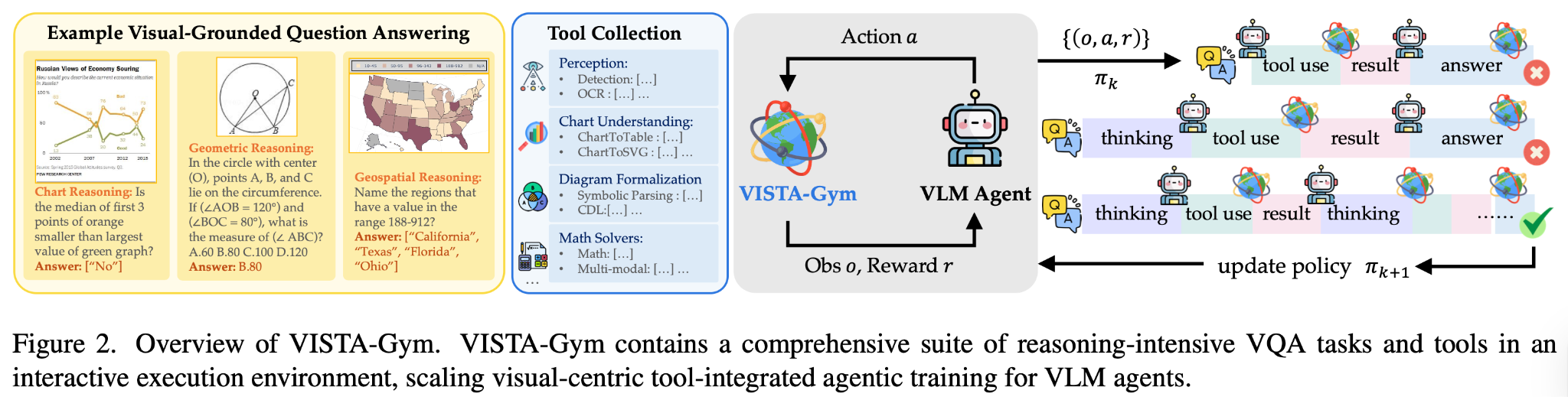
VISTA-Gym's design philosophy is "let VLMs not just look and talk, but also act." It incorporates a Python interpreter, search engine, image annotation tools, and more into the VLM's action space — the model can not only generate text answers but also call tools to verify and improve its reasoning.
Tool-Augmented Reasoning Chains
Imagine a scenario: show the model an image and ask "What architectural style is the building in this image?" A traditional VLM outputs an answer directly — "This is Gothic architecture." But with tool augmentation, the model can reason more deeply:
- Describe the image: "I see a stone building with spires and flying buttresses"
- Call image annotation tool: Have the tool mark key visual features
- Search and verify: Call a search engine to look up "spires + flying buttresses" and the corresponding architectural style
- Synthesize the answer: "Based on the spires and flying buttresses, combined with search results, this is likely Gothic architecture"
VISTA-Gym's reward design must simultaneously evaluate "answer quality" and "tool-use efficiency." If the model called 10 tools to arrive at the answer, the efficiency is clearly worse than a solution that only called 2 tools. So the reward function typically includes a tool-call count penalty term:
where is the number of tool calls and is the efficiency weight.
Combining with GRPO
VISTA-Gym combines naturally with GRPO. For the same image-question pair, the model generates multiple reasoning chains (each containing a different tool-call sequence), evaluates each group's quality with rule-based rewards, computes within-group relative advantages, and updates the policy. This is exactly the same as GRPO from Chapter 8 — except the generated "answers" go from pure text to "tool-call sequences + final answers."
11.3.3 Framework Comparison
Putting VisPlay, VISTA-Gym, and the VLM GRPO experiment from the previous section side by side:
| VLM GRPO (Basic) | VisPlay | VISTA-Gym | |
|---|---|---|---|
| Core idea | Use GRPO to optimize VLM answer quality | Questioner + Reasoner co-evolution | Tool-augmented reasoning chains |
| Data source | Human-constructed static dataset | Model auto-generates questions and answers | Images + tool-call environment |
| Reward type | Rule rewards (correctness + reasoning + format) | Inter-model game win/loss signal | Rule rewards + tool-efficiency penalty |
| Strengths | Simple, easy to reproduce | Automatic data generation, continuous evolution | More reliable reasoning, verifiable |
| Weaknesses | Static data, limited ceiling | Two-model joint training, complex engineering | High tool-environment setup cost |
| Best fit | Quick validation, teaching experiments | Long-term continuous optimization | High-reliability scenarios |
These three frameworks are not substitutes for each other; they solve problems at different levels. VLM GRPO is "basic training" — build foundations with a fixed dataset and rule rewards. VisPlay is "continuous evolution" — break through static data limits through self-play. VISTA-Gym is "reliability enhancement" — verify reasoning through tool calls. In practice, they can be used sequentially: first GRPO for foundations, then VisPlay for ongoing optimization, and finally VISTA-Gym for reliability verification.
11.3.4 Frontiers of VLM RL
VLM RL is a rapidly evolving field. Several directions are worth watching:
Video Understanding
Moving from image understanding to video understanding is a natural evolution. Video contains not just spatial information (what is in the picture) but also temporal information (how things change). VLM RL challenges in video understanding include: how to design temporal rewards (does the model understand the order of events), how to handle the computational cost of long videos (a 1-minute video may contain thousands of frames), and how to evaluate video understanding accuracy ("understood a video" is harder to quantify than "correctly counted several circles").
3D Scene Understanding
Moving from 2D images to 3D scenes, VLMs need to understand depth, occlusion, and spatial relationships. This is critical in robotic navigation and augmented reality. A unique challenge in 3D scene understanding is viewpoint invariance — the same object from different angles should be recognized as the same object. RL can train this invariance by switching between different viewpoints.
Robotic VLM-RL
VLM-RL has the broadest application prospects in robotics. Robots need to understand the environment from camera input, then make manipulation decisions. Unlike the continuous control discussed in Section 12.1 on embodied intelligence, the core of VLM-RL is "using visual understanding to guide actions" — not directly from pixels to torques, but first understanding "what object is in front" and then deciding "how to manipulate it."
| Approach | How Input Enters Policy | Strengths | Risks |
|---|---|---|---|
| End-to-end pixel RL | Image features map directly to actions | Low latency, short control chain | Weak interpretability, high transfer cost |
| VLM-RL | Form semantic understanding first, then assist decision-making | Interpretable, connects to natural language and tools | Higher inference latency, more complex cross-modal attribution |
| Hierarchical | VLM handles high-level goals, low-level controller executes | Closer to engineering deployment | High-low interface needs strict validation |
This "understand → decide" paradigm has several key advantages: interpretability — you can see why the model made a decision (because it said "there is an obstacle ahead, so detour"); generalization — a model that understands the concept of "cup" can transfer the "grasp cup" skill to cups of different shapes; and human-robot collaboration — humans can give robots instructions in natural language, and the VLM understands them and guides execution.
Robotic VLM-RL Training Flow
Robotic VLM-RL training typically follows a "sim pretraining → sim fine-tuning → real-world transfer" three-step process:
In the sim pretraining phase, RL trains the VLM's visual understanding and decision-making across many simulated scenarios. Simulation environments can quickly generate large amounts of training data (including various edge cases), and the training process is absolutely safe.
In the sim fine-tuning phase, targeted fine-tuning is done for the target robot's specific scenarios. This step introduces domain randomization (recall Section 12.1 on embodied intelligence) — randomizing lighting, textures, object positions, and other parameters so the policy works across varied conditions.
In the real-world transfer phase, the simulation-trained model is deployed on a real robot and fine-tuned with small amounts of real data. This step is the hardest — because there is always an unavoidable gap between simulation and reality (imprecise physical parameters, sensor noise, control latency, etc.).
# ==========================================
# Simplified robotic VLM-RL training flow
# ==========================================
def robot_vlm_rl_train(vlm, simulator, num_episodes=10000):
"""Robotic VLM-RL training flow"""
optimizer = setup_optimizer_with_lr_decay(vlm)
best_reward = -float('inf')
for episode in range(num_episodes):
# 1. Generate scene in simulation
scene = simulator.reset()
image = simulator.render_camera() # Get camera image
# 2. VLM understands scene and generates decisions
scene_desc = vlm.describe(image)
action_plan = vlm.plan_action(scene_desc)
# 3. Execute actions and collect rewards
total_reward = 0
for action in action_plan:
obs, reward, done, info = simulator.step(action)
total_reward += reward
# Safety check (hard constraint)
if info.get('collision', False):
total_reward -= 10.0
break
# 4. Update policy with GRPO or PPO
loss = compute_policy_gradient_loss(vlm, episode_data)
loss.backward()
torch.nn.utils.clip_grad_norm_(vlm.parameters(), max_norm=1.0)
optimizer.step()
# 5. Periodically evaluate and save best model
if total_reward > best_reward:
best_reward = total_reward
save_model(vlm, 'best_vlm_robot.pt')
if (episode + 1) % 1000 == 0:
eval_reward = evaluate(vlm, simulator, num_episodes=50)
print(f"Episode {episode+1} | "
f"Train reward: {total_reward:.1f} | "
f"Eval reward: {eval_reward:.1f}")11.3.5 From Text RL to Multimodal RL: Review and Outlook
Reviewing the full learning path across chapters, we see RL develop from the simplest tabular methods to complex multimodal scenarios:
| Chapter | Input | Action Space | Reward Source | Core Algorithm |
|---|---|---|---|---|
| Ch 4: DQN | State vectors / pixels | Discrete | Built-in environment | DQN |
| Ch 5: Policy Gradient | State vectors | Discrete/continuous | Built-in environment | REINFORCE |
| Ch 6: PPO | Token sequence | Discrete (tokens) | RM scoring | PPO |
| Ch 8: GRPO | Token sequence | Discrete (tokens) | Rule verification | GRPO |
| Ch 10: Agentic RL | Text + tool trajectories | Tool calls / tokens | Outcome + process rewards | PPO/GRPO |
| Ch 11: VLM RL | Image + tokens | Discrete (tokens) | Rules + model + grounding | GRPO |
The core ideas remain the same throughout — the policy gradient theorem (Chapter 5), Actor-Critic architecture (Chapter 5), PPO's clipping stability (Chapter 6), GRPO's within-group advantage (Chapter 8). What changes is the input modality, the action space, and the reward source. This is why earlier chapters spent considerable time building theoretical foundations — these foundations apply fully in multimodal settings.
Exercise: If you replaced the VLM's input from static images to video streams, which parts of GRPO code would need to change?
The core GRPO algorithm code (within-group relative advantage computation, policy gradient loss) does not need to change at all. What needs to change is the model's input processing layer: from a ViT that processes single frames to a temporal model that handles video sequences (such as TimeSformer or ViViT). Visual tokens are no longer "features of one image" but "spatiotemporal features of a video clip."
The reward function also needs corresponding adjustment — video understanding rewards should not only check "is the final answer correct" but also whether the model understood the temporal order and causal relationships of events. For example, asking "did the cat knock over the cup before or after jumping?" requires the model to understand the sequence of two events, not just identify "cat" and "cup."
VLM RL is one of the most active research directions today. From GPT-4V to Gemini, from LLaVA to Qwen-VL, every multimodal large model release comes with improvements in RL training methods. This field still has too many unsolved problems — visual hallucination, reward attribution, safety-efficiency tradeoffs, sim-to-real transfer — solving each one may spawn new application scenarios.
11.3.6 From VLM RL to Multimodal Agents
VLM RL produces "models that can understand images." But in real scenarios, users often need "agents that can both understand images and take action" — such as screenshot understanding + automated operation (GUI Agent), chart analysis + data querying (Data Agent). This is the leap from VLM RL to multimodal Agents: visual understanding + tool calling.
Typical Scenarios for Multimodal Agents
| Scenario | Input | Required Tools | Can Text-Only Agent Do It |
|---|---|---|---|
| Financial chart analysis | 📊 Image | Calculator, database query | ❌ Cannot read charts |
| Bug fixing from screenshots | 📸 Screenshot | Code editor, terminal | ❌ Cannot see UI |
| E-commerce comparison shopping | 🖼️ Product image | Browser, search API | ❌ Cannot understand images |
| Medical imaging diagnosis | 🏥 CT/MRI | Medical knowledge base, diagnostic tools | ❌ Cannot process images |
Special Challenges in Multimodal Agent RL
Combining this chapter's VLM RL with Chapter 10's Agent RL introduces three additional challenges:
1. Error misattribution. When a multimodal Agent produces wrong results, the error may come from visual understanding ("misread" a value in the chart) or tool calling ("made a mistake" passing wrong parameters). These two types of errors require completely different fixes — the former needs more VLM RL training (this chapter's methods), the latter needs more Agent RL training. In practice, staged verification is needed: first check if visual understanding is correct, then check if tool calls are reasonable.
2. Cross-modal reward design. A text-only Agent's reward only considers text quality, while a multimodal Agent's reward must cover both visual understanding accuracy and tool-use correctness:
def multimodal_agent_reward(trajectory, task):
"""Multimodal Agent composite reward"""
visual_reward = evaluate_visual_understanding(task.image, trajectory.visual_description)
tool_reward = evaluate_tool_usage(task.required_tools, trajectory.tool_calls)
outcome_reward = task.verify_final_result(trajectory.final_output)
return 0.2 * visual_reward + 0.3 * tool_reward + 0.5 * outcome_reward3. Cross-modal credit assignment. In a 10-turn trajectory, a visual understanding error at turn 2 may cause a tool-call failure at turn 5. This is harder than credit assignment in text-only Agents, because the cross-modal error propagation chain is longer and more subtle. The ORM vs PRM tradeoff discussed in Chapter 10 is even more prominent here.
Representative Work
GUI Agents. Training models through RL to understand UI elements (buttons, input fields) in screenshots and perform clicks, typing, scrolling, and other operations. Representative work includes CRAFT-GUI (desktop GUI operations) and MobileRL (mobile touch-screen operations). GUI Agents have a natural RLVR advantage — whether an operation succeeded is objectively verifiable.
Multimodal Deep Research. Tongyi DeepResearch already supports multimodal input, analyzing charts and images in search results and extracting chart data from PDF papers. This is a frontier direction integrating VLM RL and Agent RL.
Creative Agents. Receive user requirements and reference images, then call image generation/editing tools to create. The challenge lies in the subjectivity of reward — "how good is a style transfer" has no objective standard and requires LLM-as-Judge evaluation.
Training Path
If you want to train multimodal Agents, the recommended path is:
- Train visual understanding first: Use this chapter's VLM GRPO to build basic visual ability.
- Then train tool use: Use Chapter 10's tool-use RL to establish basic tool-use patterns.
- Finally, joint training: Do end-to-end RL on multimodal Agent tasks, with reward design following the composite reward function above.
Key principle: verify that visual understanding and tool use each meet baseline independently before attempting end-to-end joint training. If the underlying components have problems, joint training will not rescue them.
The next section shifts perspective from "visual understanding" to "visual generation" — looking at how Diffusion and video generation models can improve text alignment, visual quality, and instruction following through RL post-training.
References
- VisPlay Project Page — demonstrates the joint training framework for the Image-Conditioned Questioner and Multimodal Reasoner.
- VISTA-Gym / VISTA-R1 Blog — showcases the tool-augmented visual QA environment, VISTA-R1 main results, and ablation analysis.