6.5 Hands-On: BipedalWalker
Goal: Train
BipedalWalker-v3with A2C, observe how Actor-Critic handles high-dimensional continuous control — and understand why the next chapter needs PPO.
Code: actor_critic_bipedalwalker.py · render_bipedalwalker.py · requirements.txt
The previous section's Pendulum had just 1 continuous action and a 3-dimensional state. BipedalWalker raises the complexity by an order of magnitude: a 24-dimensional state (joint angles, angular velocities, ground-contact sensors, etc.) and 4 continuous actions (two hip joints and two knee joints). The goal is to teach a bipedal robot to walk.
6.6.1 Environment: BipedalWalker-v3
O ← head
/|\
/ | \ ← torso
/ | \
🔶 🔶 ← hip joints
| | ← thighs
🔷 🔷 ← knee joints
| | ← shins
___ ___ ← feet| Property | Value |
|---|---|
| State dim | 24 (torso angle, angular velocity, joint states, 10 lidar distance readings) |
| Action dim | 4 (torques at left hip, left knee, right hip, right knee; continuous ) |
| Reward | forward progress + survival penalty - energy cost |
| Termination | falling (head touches ground) or reaching the goal |
| "Solved" bar | average return > 300 |
The core challenge of BipedalWalker is coordination: all four joints must apply force correctly and simultaneously. A single joint moving out of sync can cause a fall.
The real difficulty going from Pendulum to BipedalWalker is not just the state dimension growing from 3 to 24 or the action dimension from 1 to 4. What makes it genuinely harder is that the policy must discover temporal coordination across four joints — lifting the left foot, shifting the center of mass, bringing the right foot through. This is not simply "output the correct torque at each joint"; it is an entire gait cycle.
| Pendulum | BipedalWalker | |
|---|---|---|
| State dim | 3 | 24 |
| Action dim | 1 | 4 |
| Training | minutes | tens of minutes |
| Difficulty | single joint | multi-joint coordination + balance |
6.6.2 Running Training
Install dependencies:
pip install -r code/chapter06_actor_critic/requirements.txtQuick smoke test:
python code/chapter06_actor_critic/actor_critic_bipedalwalker.py \
--total-timesteps 100000This section uses Stable-Baselines3's A2C implementation — the same algorithm as the Pendulum experiment, but adjusted for BipedalWalker's complexity: 16 parallel environments and a larger [128, 128] network. Run the full training:
python code/chapter06_actor_critic/actor_critic_bipedalwalker.py \
--total-timesteps 3000000BipedalWalker is far harder than Pendulum. A2C typically needs 3 million steps before an effective gait begins to emerge, which takes roughly 8–10 minutes on a typical CPU. To simply verify the pipeline works, use --total-timesteps 100000 for a quick test.
The A2C hyperparameter configuration for BipedalWalker:
model = A2C(
policy="MlpPolicy", # MLP policy
env=vec_env, # 16 parallel environments
learning_rate=7e-4, # learning rate
n_steps=32, # rollout steps per update
gamma=0.99, # discount factor
gae_lambda=0.95, # GAE λ
ent_coef=0.0, # entropy coefficient
vf_coef=0.5, # value function loss coefficient
max_grad_norm=0.5, # gradient clipping
policy_kwargs=dict(net_arch=[128, 128]), # two layers of 128 units
)Compared to the Pendulum configuration, the main changes are increasing parallel environments from 8 to 16 (BipedalWalker episodes are longer, so more parallelism is needed for throughput) and enlarging the network from the default [64, 64] to [128, 128] (the 24-dimensional state demands more representational capacity).
The training script saves models, checkpoints, and training curves to the output/ directory:
| File | Description |
|---|---|
actor_critic_bipedalwalker.zip | trained A2C model |
actor_critic_bipedalwalker_500k.zip | 500k-step checkpoint |
actor_critic_bipedalwalker_1000k.zip | 1M-step checkpoint |
actor_critic_bipedalwalker_2000k.zip | 2M-step checkpoint |
actor_critic_bipedalwalker_reward.png | episode reward curve |
actor_critic_bipedalwalker_entropy.png | policy entropy loss curve |
actor_critic_bipedalwalker_loss.png | Actor/Critic loss curves |
6.6.3 Training Results: Standing First, Then Struggling to Walk
Results from a single 3M-timestep training run are shown below. A2C's training curve is noisier and more unstable than PPO's — a typical signature of Actor-Critic without clipping.
Episode Reward
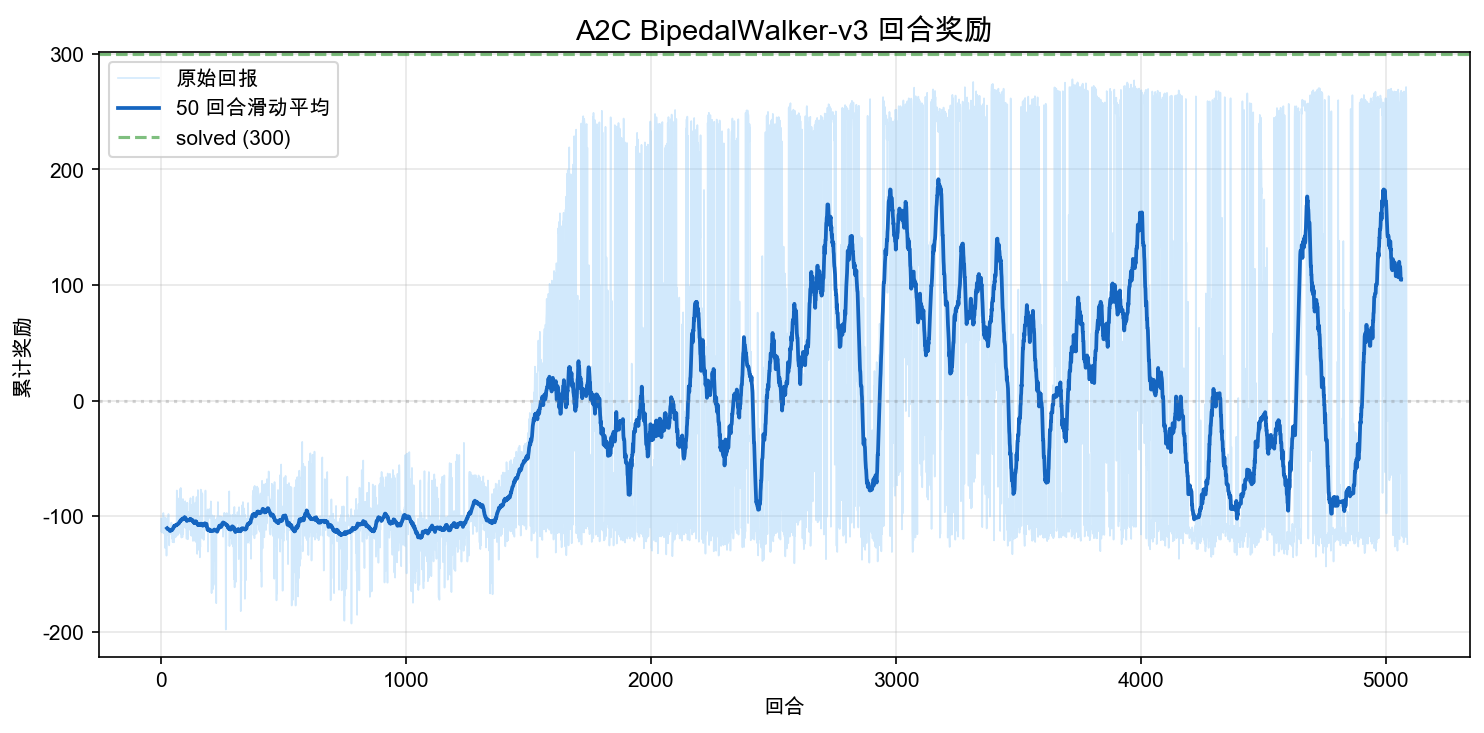
The curve breaks down into three phases:
- 0–1M steps: Reward climbs slowly from around -110 to approximately -40. The robot transitions from "falling immediately" to "standing but not walking." As with PPO, balance is the first skill the policy acquires.
- 1M–2M steps: Reward oscillates violently. The policy starts attempting steps, but is extremely unstable — some episodes score 200+, others still fall and return -120. The moving average swings between 0 and 100. This is A2C's most distinctive characteristic: without a clipping mechanism to constrain policy updates, each update can push the policy into an entirely different regime.
- 2M–3M steps: The policy gradually converges to "walking most of the time." The moving average settles around 100–150, but raw values still swing wildly (from -80 to +200).
Compared to the Pendulum reward curve from the previous section, BipedalWalker's fluctuations are far more severe. Pendulum's moving average trends relatively smoothly, whereas BipedalWalker's curve is a roller coaster — a direct consequence of unconstrained policy updates in high-dimensional continuous control.
Policy Entropy
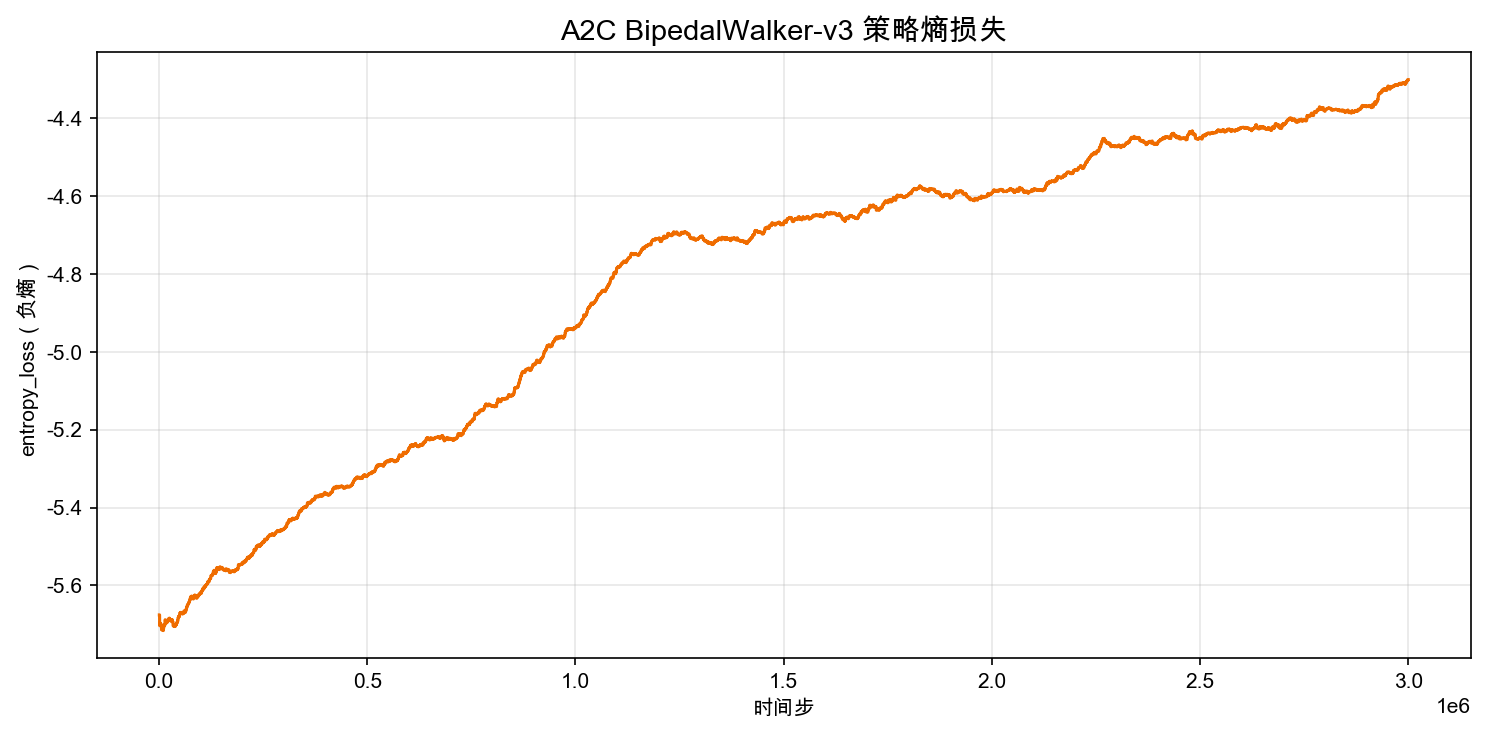
Policy entropy drops from 5.37 to 4.38 — a much smaller decrease than on Pendulum. This indicates that on BipedalWalker, A2C's policy converges more slowly; coordinating four joints requires more exploration before effective patterns emerge.
Note that the entropy curve is more jagged than Pendulum's. Because A2C updates from freshly collected data at every step (on-policy), fluctuations in data quality directly affect the update direction. If a rollout happens to capture several falling episodes, the policy gets pushed in a more conservative direction; conversely, a few successful gaits push it toward more aggressive exploration.
Loss Curves
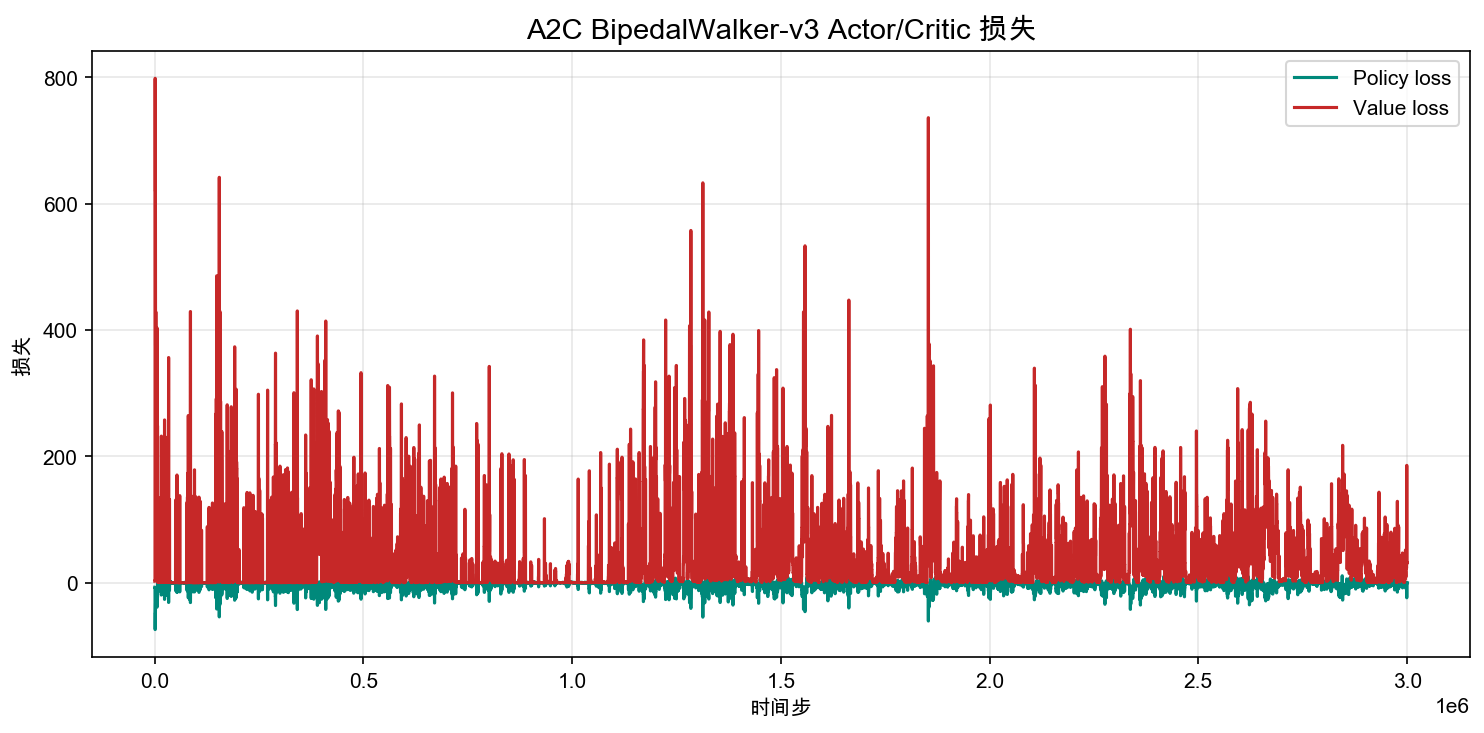
A key feature of the loss curves is periodic sharp spikes. Value loss (red) periodically surges to 100–200, meaning the Critic's estimates suddenly become very inaccurate. This typically occurs after a large policy update — the new policy generates trajectory data that differs completely from what the Critic was trained on, and the Critic has not yet adapted.
These spikes correspond closely with the violent fluctuations on the reward curve: large policy update → Critic becomes inaccurate → the next Actor update uses bad advantage signals → the policy gets disrupted again. This is the core problem of vanilla Actor-Critic on complex tasks.
6.6.4 Three-Phase Replay
To get an intuitive feel for A2C's learning process, we compare the policy at three different training stages. All three models use identical hyperparameters, differing only in the number of training steps.
After training, use the rendering script to generate replay GIFs:
python code/chapter06_actor_critic/render_bipedalwalker.py \
--model output/actor_critic_bipedalwalker.zip \
--output-dir output/bipedalwalker_a2c_episodes \
--episodes 3 --seeds 0 1 2Early Phase (500k steps, return -52.9)
At 500k steps the policy has learned to stand without falling. The robot can last the full 1600 steps per episode, but barely moves forward — the limbs maintain balance in place. Compared to PPO reaching the same "standing" stage at 100k steps, A2C needs many more steps.

Mid Phase (2M steps, return 263.8)
At 2M steps the policy is attempting to walk, but is extremely unstable. Across 20 evaluation episodes, only about 15% score above 100 points; the rest still end in falls. The episode shown here is a rare success — the policy happened to find a coordinated gait. The same model might fall immediately in the next episode.

Late Phase (3M steps, return 274.2)
At 3M steps the policy has developed a relatively stable gait. Most episodes score 271–276, but about 10–15% still end in falls (-47 to -59 points). This is A2C's typical performance: it can learn to walk, but cannot match PPO's consistency.

Evaluation comparison across the three phases (20-episode average):
| Training Steps | Mean Reward | Std | Behavior |
|---|---|---|---|
| 500k | -50.0 | 5.7 | Stands but does not walk; every episode runs 1600 steps |
| 2M | -66.4 | 97.0 | Highly unstable: ~15% of episodes walk, rest fall |
| 3M | 221.8 | 107.6 | Most episodes score 270+, but 10–15% still fall |
6.6.5 A2C vs PPO: Same Task, Different Stability
This section and Section 7.1 of Chapter 7 use the identical environment (BipedalWalker-v3), but train with A2C and PPO respectively. Comparing the two experiments:
| Metric | A2C (this section) | PPO (Section 7.1) |
|---|---|---|
| Training steps | 3M | 2M |
| 20-episode mean reward | 221.8 | 282.5 |
| Std | 107.6 | 59.7 |
| Typical success | 271–276 | 293–299 |
| Fall rate | ~15% | ~5% |
| Training curve noise | severe oscillation | relatively smooth |
The two algorithms share the same core architecture: both are Actor-Critic, with the Actor outputting a Gaussian distribution and the Critic estimating . The key difference is the constraint mechanism on policy updates:
- A2C: Collects data with the current policy and directly computes advantages for a gradient update. The update magnitude is controlled only by the learning rate, with no additional constraint on how far the policy moves.
- PPO: Adds a clipping mechanism on top of A2C, ensuring the new policy does not deviate too far from the old one after each update. It also reuses the same batch of data for multiple update epochs, improving data efficiency.
This difference is barely noticeable on Pendulum (the task is too simple), but becomes starkly clear on BipedalWalker:
- Training stability: A2C's reward curve oscillates violently, with the policy frequently jumping between "walking" and "falling." PPO's curve rises relatively smoothly.
- Final performance: A2C's best episodes reach only 276, while PPO consistently scores 295+. The gap is not in the policy's ceiling but in consistency.
- Data efficiency: A2C used 3M steps yet fell short of PPO's results at 2M steps. PPO's data-reuse mechanism (multi-epoch updates) gives it a clear advantage on complex tasks.
6.6.6 Common Failures and Tuning
BipedalWalker is more prone to training failures than typical discrete-action environments. If results are unsatisfactory, investigate in the following order.
First, confirm the training duration is sufficient. 3 million steps is the starting point for A2C, not the finish line. If the curve is still climbing but the slope is too gentle, continue training. A2C does not support resuming directly from a checkpoint, but you can rerun with a larger --total-timesteps.
Second, confirm the number of parallel environments. 16 is the configuration used in this section. A2C relies on many parallel environments to stabilize gradient estimates — using only 4 environments will make training very unstable.
Third, check whether the policy has prematurely converged to "standing still." If the reward stays around -50 without improving, the policy has learned that "not falling avoids penalties" but has no incentive to move forward. Try increasing ent_coef to 0.01 to encourage exploration.
Fourth, consider increasing network capacity. The default [128, 128] may not be enough for a 24-dimensional state. Try [256, 256]:
model = A2C(
policy="MlpPolicy",
policy_kwargs=dict(net_arch=[256, 256]),
...
)Common tuning reference:
| Parameter | This section | What happens if it's off |
|---|---|---|
learning_rate | 7e-4 | Too large → violent oscillation; too small → slow learning |
n_steps | 32 | Too short → noisy advantages; too long → infrequent updates |
num_envs | 16 | Too few → unstable gradients; too many → overhead on a single machine |
net_arch | [128, 128] | Too small → can't express complex gaits; too large → slower training |
gamma | 0.99 | Too low → only focuses on short-term survival, ignores long-term walking efficiency |
Section Summary
This chapter started from REINFORCE's high-variance problem and introduced the Actor-Critic architecture: a Critic network estimates to provide a low-variance advantage signal, while the Actor network makes decisions. From CartPole (discrete) to Pendulum (1D continuous) to BipedalWalker (4D continuous), we saw that Actor-Critic remains effective as task complexity grows.
But the BipedalWalker experiment also exposed the core weakness of vanilla Actor-Critic: training instability. Without constraints on the magnitude of policy updates, A2C's reward curve oscillates violently on complex tasks, and both final performance and consistency fall short of PPO.
The next chapter addresses this problem with PPO: Chapter 7: PPO.