6.4 Actor-Critic 的前沿大规模应用
前面的实验都在 CartPole、LunarLander 这样的教学环境中完成——几十维状态、几维动作,CPU 上几分钟就能训完。但 Actor-Critic 架构的真正价值在于:它可以从这些玩具任务扩展到工业级规模。本节介绍三个里程碑式的大规模 Actor-Critic 应用,覆盖三个领域:游戏 AI、真实机器人、工业仿真平台。
| 应用 | 机构 | 领域 | 规模 |
|---|---|---|---|
| AlphaStar | DeepMind | 星际争霸 II | Grandmaster 级别,Top 0.2% 人类玩家 |
| SAC 真实机器人 | DeepMind / BAIR | 物理机器人抓取与灵巧操控 | 直接部署在真实机械臂上 |
| NVIDIA Isaac Lab | NVIDIA | 机器人仿真训练平台 | GPU 加速,支持数千并行环境 |
AlphaStar:用 Actor-Critic 打败星际争霸 Grandmaster
星际争霸 II(StarCraft II)是暴雪娱乐于 2010 年发行的实时策略游戏(RTS)。游戏中两名玩家各自选择一个种族——Terran(人类)、Protoss(星灵)或 Zerg(异虫),在一张地图上同时采集资源(矿物和瓦斯)、建造建筑、生产军队、升级科技,最终目标是消灭对手。与回合制棋类游戏不同,星际争霸是实时进行的:双方同时操作,没有"等对方走完再走"的回合,每秒钟需要做出多个决策——选兵、移动、进攻、撤退、建造、侦察,职业选手的有效 APM(每分钟操作数)可达 300-500。
为什么星际争霸比围棋更难
AlphaGo 在 2016 年击败李世石,但星际争霸 II 对 AI 来说比围棋难得多。围棋是完全信息博弈:棋盘上所有信息对双方可见,状态可以用 19×19 的网格表示,每步在 361 个交叉点中选一个。星际争霸 II 则是不完全信息博弈:战争迷雾遮蔽了对手的行动,状态包含几百个单位的位置、血量、资源,动作需要先选择单位、再选择能力、再指定目标——组合后的动作空间约 种。一局游戏持续约 10,000 步,远超围棋的 ~250 步。

2019 年,DeepMind 的 AlphaStar 成为第一个在星际争霸 II 中达到 Grandmaster 级别的 AI,在官方 Battle.net 排名中位居所有人类玩家的前 0.2% [1]。
AlphaStar 的网络架构
AlphaStar 的核心就是一个大规模 Actor-Critic 系统。网络输入是游戏的原始特征(单位列表、小地图、建造队列、资源等),经过 Transformer torso 处理变长的实体集合,再通过 LSTM core 积累时序记忆,最后分两路输出。
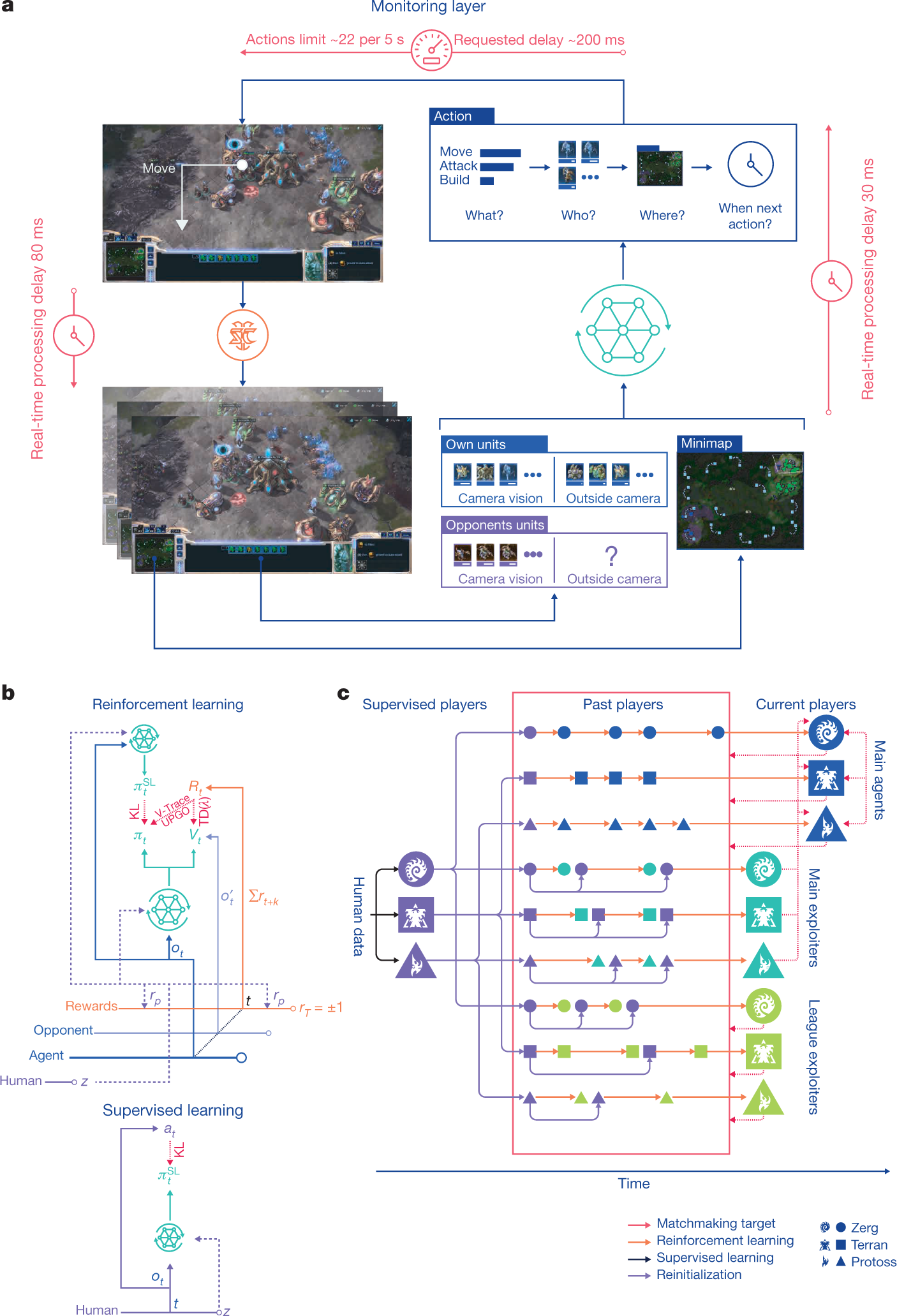
Actor(策略网络)输出结构化的动作序列。由于星际争霸的动作不是简单的"左/右",Actor 使用自回归策略头(autoregressive policy head):先选动作类型(move、attack、build...),再选执行单位,再选目标位置,每一步的条件概率串联起来形成完整的动作。
**Critic(价值网络)**输出一个标量 ,评估当前局面的胜率。和本章学的 Critic 完全一样——只是输入从 4 维 CartPole 状态变成了几百维的游戏特征,网络参数量从几千增长到约 2 亿。
训练算法:V-trace Actor-Critic
AlphaStar 使用的训练算法是 V-trace,一种 off-policy 的 Actor-Critic 方法 [2]。
回顾本章的基本 Actor-Critic 更新:
其中优势 用 TD Error 估计:。
V-trace 的关键改进是处理 off-policy 数据。在星际争霸中,AlphaStar 同时维护一个联盟中的多个智能体,每个智能体用不同的策略风格对战。训练时,当前 Actor 可以从其他智能体(不同策略)产生的经验中学习。但不同策略产生的数据分布不同——V-trace 通过重要性采样截断来修正这个偏差:
其中 是截断的重要性采样比, 是截断的自举权重。直觉上:V-trace 允许 Actor 从"别人"的经验中学习,但通过截断确保不会被与自己策略差异太大的数据带偏。
多智能体联盟训练
AlphaStar 最独特的创新是联盟训练(League Training)。联盟中维护了三类智能体:
- Main Agent:主智能体,目标是击败联盟中的所有对手
- Main Exploiter:专门找主智能体的弱点,迫使它补漏洞
- League Exploiter:在整个联盟中寻找无人能对付的策略盲区
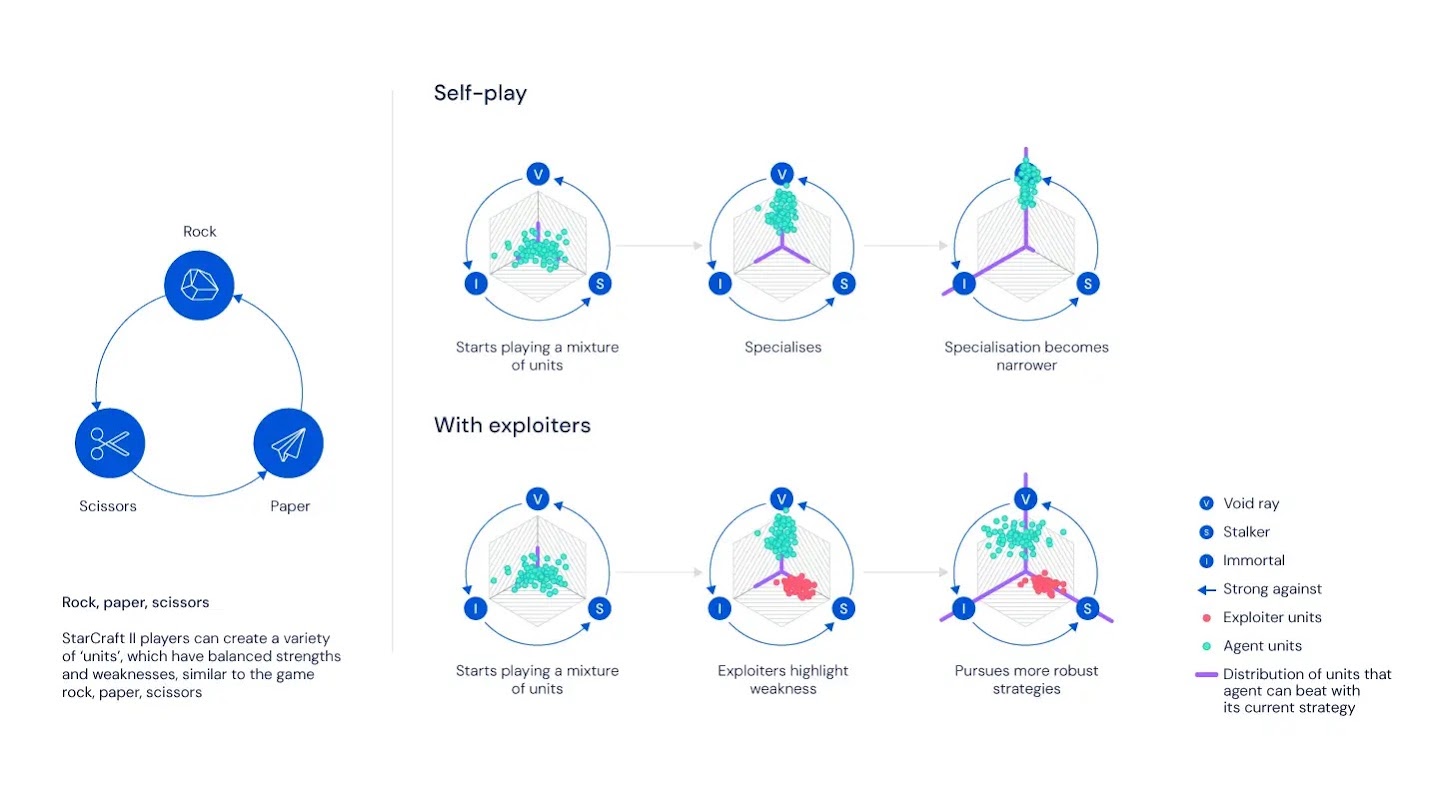
每个智能体都是一个独立的 Actor-Critic 网络。联盟中总共维护了约数百个不同的策略,累计进行了数亿局对战。这种训练方式让 AlphaStar 不会过度拟合某一种打法——它的策略必须是鲁棒的。
训练规模与关键结果
整个训练过程持续约 44 天,期间数百万局对战同时并行进行,累计进行了数亿局 self-play 对局。每个智能体的网络包含约 2 亿参数,消耗的 TPU 算力相当于 12,000 年的游戏时间。
AlphaStar 与本章概念的对应
Actor = 策略网络(自回归策略头输出结构化动作),Critic = 价值网络(输出胜率 ),优势估计 = V-trace TD Error,联盟训练 = 多个 Actor-Critic 实例互相博弈。整个系统就是本章学的 Actor-Critic 架构在大规模游戏 AI 中的工业级实现。
论文:Vinyals, O., et al. (2019). Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature, 575, 350-354. DOI
代码:google-deepmind/alphastar — DeepMind 官方 AlphaStar 训练框架(PyTorch + JAX)
后续工作:AlphaStar Unplugged (2023) 将 AlphaStar 扩展到离线 RL,建立了星际争霸 II 的离线 RL 基准 [3]。
SAC:Actor-Critic 从仿真走向真实机器人
为什么需要 SAC
本章学的 A2C 在 CartPole 上表现不错,但在真实机器人上会遇到两个问题:探索不足(确定性策略容易陷入局部最优)和样本效率低(真实机器人试错成本极高)。SAC(Soft Actor-Critic) [4] 由 Tuomas Haarnoja 在 UC Berkeley 的 BAIR 实验室提出,核心思想是在 Actor-Critic 的目标函数中加入熵正则项:
其中 是环境奖励, 是策略的熵(衡量策略有多"随机"), 是温度参数,控制"尽量拿高分"和"尽量多探索"的权衡。
SAC 不仅想让机器人拿到高奖励,还想让策略保持一定的随机性。这种随机性让机器人在遇到未知情况时不会卡死,而是能灵活应对——这对 sim-to-real 迁移至关重要。
SAC 的双 Critic 架构
和本章学的 A2C 不同,SAC 使用两个独立的 Critic 网络(Twin Q-Networks)来估计动作价值 ,Actor 输出高斯分布的参数。
取两个 Critic 的最小值 是为了防止 Q 值过高估计——过高估计会导致 Actor 过度自信,做出危险动作。
Actor 更新:最大化熵正则化的期望回报:
Critic 更新:最小化 Bellman 误差(目标包含熵项):
真实机器人上的成功案例
SAC 已经直接部署在物理机器人上,覆盖了多种任务:

| 任务 | 机器人 | 关键挑战 | 结果 |
|---|---|---|---|
| 灵巧手旋转笔 | Shadow Hand | 24 个自由度,极度精密 | 成功学会旋转,无需人类示范 |
| 机械臂抓取 | Sawyer | 7 自由度,稀疏奖励 | 从随机策略到 90%+ 抓取成功率 |
| 四足行走 | ANYmal | 12 个关节,动态平衡 | 学会多种步态,适应不同地形 |
| 门把手转动 | Franka Emika | 接触力控制,精细操作 | 学会自适应抓握和转动 |
这些任务的共同特点是:在仿真中用 SAC 训练,然后直接迁移到物理机器人上。SAC 的熵正则化让策略在仿真中覆盖了足够多的动作变体,使得 sim-to-real 迁移时策略对现实世界的噪声和不确定性有更好的鲁棒性。
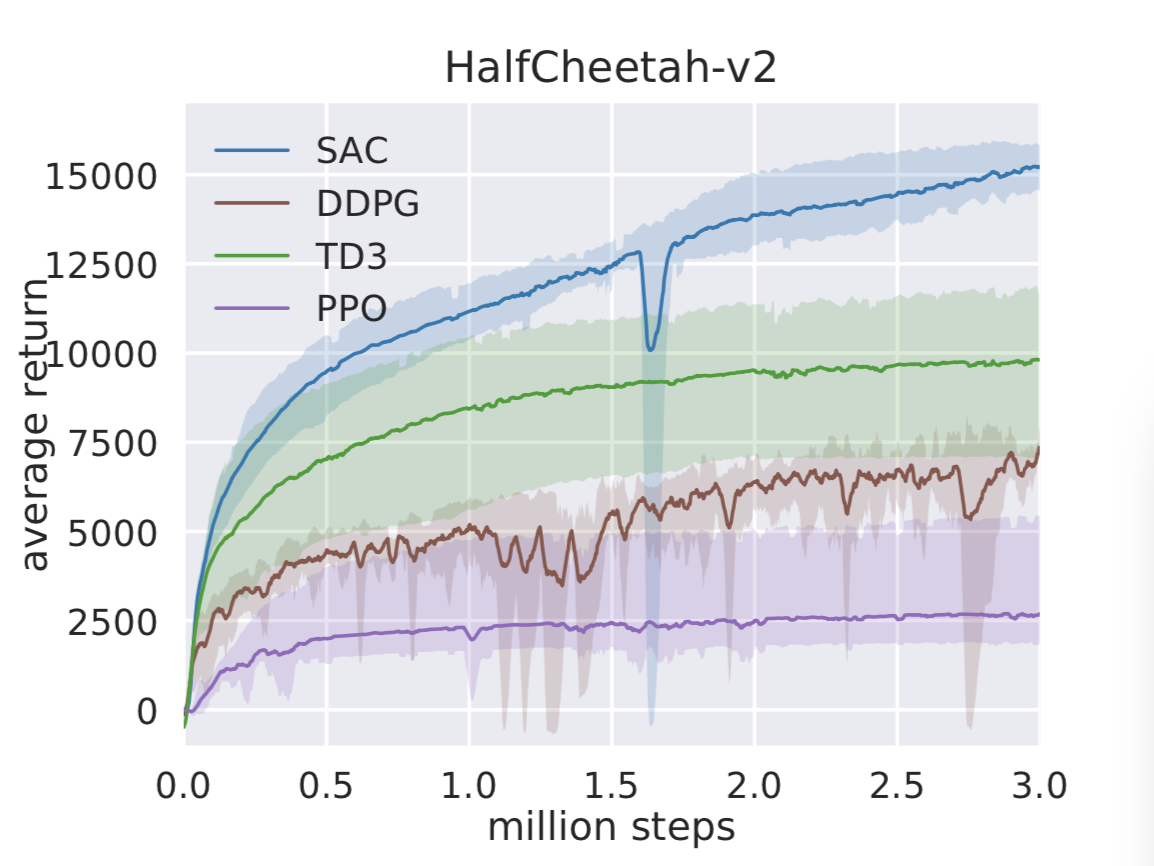
SAC 的 Benchmark 对比
BAIR 博客提供了 SAC 与 DDPG、TD3、PPO 在 MuJoCo 连续控制任务上的训练曲线对比。在 HalfCheetah 和 Humanoid 两个高维连续控制任务上,SAC(蓝色)在最终性能、样本效率和最差情况表现上均优于其他方法:
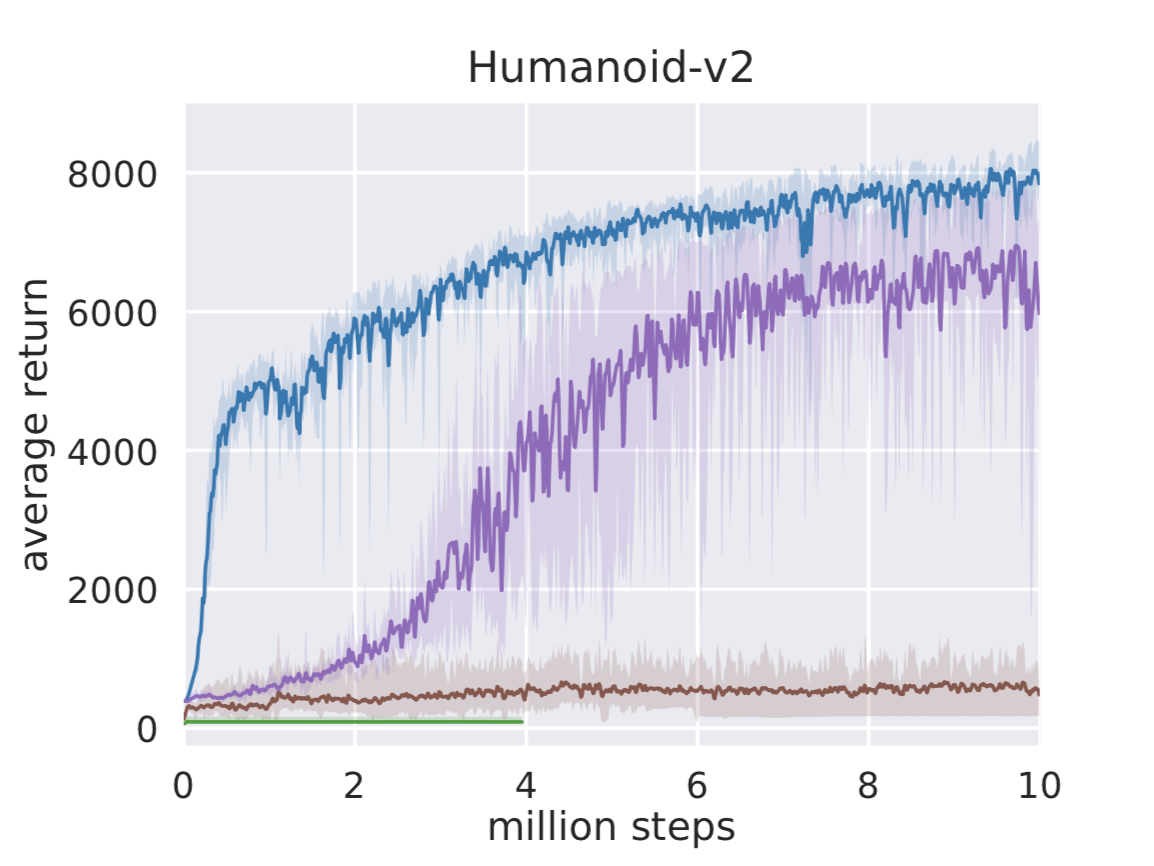
SAC 与本章概念的对应
Actor = 高斯策略网络(输出 和 ),Critic = 双 Q 网络(),优势估计 = 中的 由 Critic 提供,熵正则化 = 强制保持探索。SAC 就是把本章学的 Actor-Critic 加上了熵正则化和双 Critic 两个工程改进。
论文:
- Haarnoja, T., et al. (2018). Soft Actor-Critic: Off-Policy Maximum Entropy Deep RL with a Stochastic Actor. ICML. arXiv
- Haarnoja, T., et al. (2018). Soft Actor-Critic Algorithms and Applications. arXiv
代码:rail-berkeley/softlearning — SAC 官方实现
博客:Soft Actor-Critic: Deep RL with Real-World Robots — BAIR 官方博文
NVIDIA Isaac Lab:工业级 Actor-Critic 训练平台
从单机实验到工业流水线
前几章的实验都是单个环境、单个策略网络、CPU 上跑。工业级机器人训练的需求完全不同:
| 需求 | 教学实验 | 工业级 |
|---|---|---|
| 并行环境数 | 1 | 数千到数万 |
| 物理仿真 | Gymnasium(简化物理) | GPU 加速刚体/柔体仿真 |
| 场景多样性 | 固定参数 | 域随机化(颜色、光照、摩擦力、质量...) |
| 训练速度 | 几分钟 | 几小时到几天 |
| 部署目标 | 看曲线 | 真实机器人 |
NVIDIA Isaac Lab(原名 Isaac Orbit)就是为这个需求设计的。它是一个基于 Isaac Sim 的开源机器人学习框架。Isaac Lab 与 Actor-Critic 的关系非常直接:平台内置的 RL 算法(PPO、SAC、TD3 等)全部是 Actor-Critic 变体——每个并行环境里跑着一个 Actor(策略网络)输出动作,同时一个 Critic(价值网络)估计当前状态的价值,Learner 利用数千环境并行收集的 rollout 数据批量更新 Actor 和 Critic 的参数。Isaac Lab 做的是把本章学的"一个 Actor 做决策、一个 Critic 做评估"这套架构从单机 CartPole 扩展到了 GPU 并行训练的工业级规模 [5]。

支持的机器人与算法
Isaac Lab 内置了多种机器人模型,覆盖从机械臂到四足到双足的全系列:

| 机器人 | 类型 | 应用场景 |
|---|---|---|
| Franka Emika Panda | 7 自由度机械臂 | 抓取、装配、精细操作 |
| ANYmal | 四足机器人 | 地形行走、搜救 |
| Unitree Go1/H1 | 四足/双足 | 动态运动、平衡 |
| Shadow Hand | 灵巧手 | 精密操作(笔旋转、物体操纵) |
算法方面,Isaac Lab 集成了多个 RL 框架(rl_games、skrl、rlrig 等),支持 PPO、SAC、DDPG、TD3、A2C 等主流 Actor-Critic 算法。
域随机化:Sim-to-Real 的关键
仿真环境和真实世界之间总有差距——物理参数不准、传感器有噪声、光照会变化。Isaac Lab 通过域随机化来解决这个问题:在每次训练 episode 中随机化大量参数。
域随机化的核心逻辑是:如果策略在训练时已经见识过各种"变体"环境,那它在真实世界的差异面前就不会手足无措。OpenAI 在 2019 年的灵巧手魔方项目中证明了这一点——通过大规模域随机化训练的策略可以直接从仿真迁移到真实 Shadow Hand。
训练规模与速度
| 指标 | 数值 |
|---|---|
| 并行环境数 | 单 GPU 上 2,000~16,000 个 |
| 物理步频率 | ~100,000 steps/秒(单 GPU) |
| 典型训练时间 | 1-8 小时(取决于任务复杂度) |
| GPU 支持 | NVIDIA RTX 3090 / A100 / H100 |
Isaac Lab 与本章概念的对应
它是把本章学的 Actor-Critic 从"单机 CartPole"扩展到"工业级机器人训练"的工程化平台。算法本身没有变(PPO、SAC 都是 AC),变的是训练规模、物理仿真精度和部署流程。Actor-Critic 的"一个网络做决策,一个网络做评估"这个分工,在 GPU 并行训练数千个环境时同样有效。
代码:isaac-sim/IsaacLab — NVIDIA 官方开源项目(MIT License)
论文:Mittal, M., et al. (2023). Orbit: A Unified Simulation Framework for Interactive Robot Learning Environments. IEEE RA-L. arXiv
三个应用的对比
| AlphaStar | SAC 机器人 | Isaac Lab | |
|---|---|---|---|
| 领域 | 游戏 AI | 物理机器人 | 仿真训练平台 |
| AC 变体 | V-trace off-policy AC | 最大熵 AC(双 Q 网络) | PPO / SAC / TD3 等多种 |
| Actor 输出 | 结构化动作序列(自回归) | 高斯分布(均值+标准差) | 取决于算法和任务 |
| Critic 输出 | (胜率) | (双 Q) | 或 |
| 训练规模 | 数亿局,44 天 | 数百万步,数小时 | 数十亿步,数小时 |
| 关键创新 | 多智能体联盟 + V-trace | 熵正则化 + 双 Critic | GPU 并行 + 域随机化 |
| 成果 | Grandmaster 级别 | 真实机器人部署 | 工业级 sim-to-real 流水线 |
这三者的共同点是:核心都是 Actor + Critic 的架构。变化的是训练算法的细节(V-trace vs 熵正则化 vs 标准 PPO)、训练规模(单机 vs 数千 GPU 并行)和部署目标(游戏 vs 真实机器人)。Actor-Critic 架构之所以能从 CartPole 扩展到这些工业级应用,正是因为"一个网络做决策,一个网络做评估"这个分工会随规模增长而越来越有效。
下一节,让我们亲手在 Pendulum 上跑一个 Actor-Critic 实验:动手:Pendulum 摆杆平衡。
Vinyals, O., et al. (2019). Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature, 575, 350-354. DOI ↩︎
Espeholt, L., et al. (2018). IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures. ICML. arXiv ↩︎
AlphaStar Unplugged: Large-Scale Offline Reinforcement Learning. (2023). arXiv ↩︎
Haarnoja, T., et al. (2018). Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. ICML. arXiv ↩︎
Mittal, M., et al. (2023). Orbit: A Unified Simulation Framework for Interactive Robot Learning Environments. IEEE RA-L. arXiv ↩︎