7.1 动手:BipedalWalker 连续控制
本节目标:训练 PPO 控制二足机器人在随机地形上行走,理解连续动作空间下的策略学习与离散动作的本质区别。
本节代码:ppo_bipedal_walker.py · render_bipedal_walker.py · requirements.txt
前面几章我们已经用 CartPole 和 LunarLander 看过离散动作任务:策略只需要在几个动作里选一个。但现实中的控制问题——机器人关节扭矩、汽车油门刹车、无人机旋翼转速——通常都是连续动作空间。PPO 的一个核心优势是原生处理连续动作:策略网络直接输出高斯分布的均值和标准差,从中采样得到连续动作,不需要把动作空间离散化。BipedalWalker-v3 就是这样一个连续控制任务。
7.1.1 运行 BipedalWalker 训练
BipedalWalker 的任务是控制一个二足机器人在随机生成的地形上行走。状态有 24 维(包括激光雷达测距、关节角度和速度),动作是 4 维连续向量(两条腿的髋关节和膝关节扭矩)。它比 LunarLander 更适合作为本章主实验,因为这里不再是从几个离散动作中选择,而是要直接学习连续控制信号。

安装依赖:
pip install -r code/chapter07_ppo/requirements.txt运行训练:
python code/chapter07_ppo/ppo_bipedal_walker.py \
--total-timesteps 2000000BipedalWalker 的训练比前面常见的离散动作环境慢很多。像 LunarLander 这类任务用 20 万步就能看到明显学习趋势,BipedalWalker 通常需要 200 万步以上才能稳定行走。在普通 CPU 上,200 万步大约需要 60-90 分钟。如果只是验证管线能跑通,可以先用 --total-timesteps 100000 快速测试。
PPO 在 BipedalWalker 上的超参数配置:
model = PPO(
policy="MlpPolicy", # 多层感知机策略
env=vec_env, # 8 个并行环境
learning_rate=3e-4, # 学习率
n_steps=2048, # 每次 rollout 步数
batch_size=256, # 连续控制下用更大的小批量稳定梯度估计
n_epochs=10, # 每批更新轮数
clip_range=0.2, # PPO 裁剪范围
ent_coef=0.005, # 熵系数(连续空间探索更丰富,稍低即可)
gamma=0.99, # 折扣因子
gae_lambda=0.95, # GAE λ
)batch_size 设为 256,因为连续动作空间下策略更新的方差更大,更大的批量有助于稳定梯度估计。ent_coef 设为 0.005,因为高斯策略本身就有持续的探索能力(每次采样都有随机性),不需要额外加太多熵正则化。并行环境使用 8 个,因为 BipedalWalker 的 episode 更长(最多 1600 步),更多并行环境能保持采样吞吐量。
7.1.2 查看训练曲线
本实验使用 Stable-Baselines3(SB3) 的 PPO 实现。SB3 是目前最主流的 RL 工具库之一,PPO 是其中使用最广泛的算法。我们的训练配置:8 个并行 DummyVecEnv 环境,MlpPolicy(多层感知机),学习率 3e-4,batch_size=256,clip_range=0.2,总训练 2M 步。训练脚本会在 output/ 目录下生成 4 张独立的训练指标图。
PPO 训练过程中有 4 个关键指标,每一个都从不同角度反映策略的学习状态。下面逐个分析。
回合奖励(Episode Reward)
回合奖励是最直观的指标——每个 episode 结束时的累计回报。BipedalWalker 的奖励范围大约在 -110(迅速摔倒)到 +340(高效行走)之间。
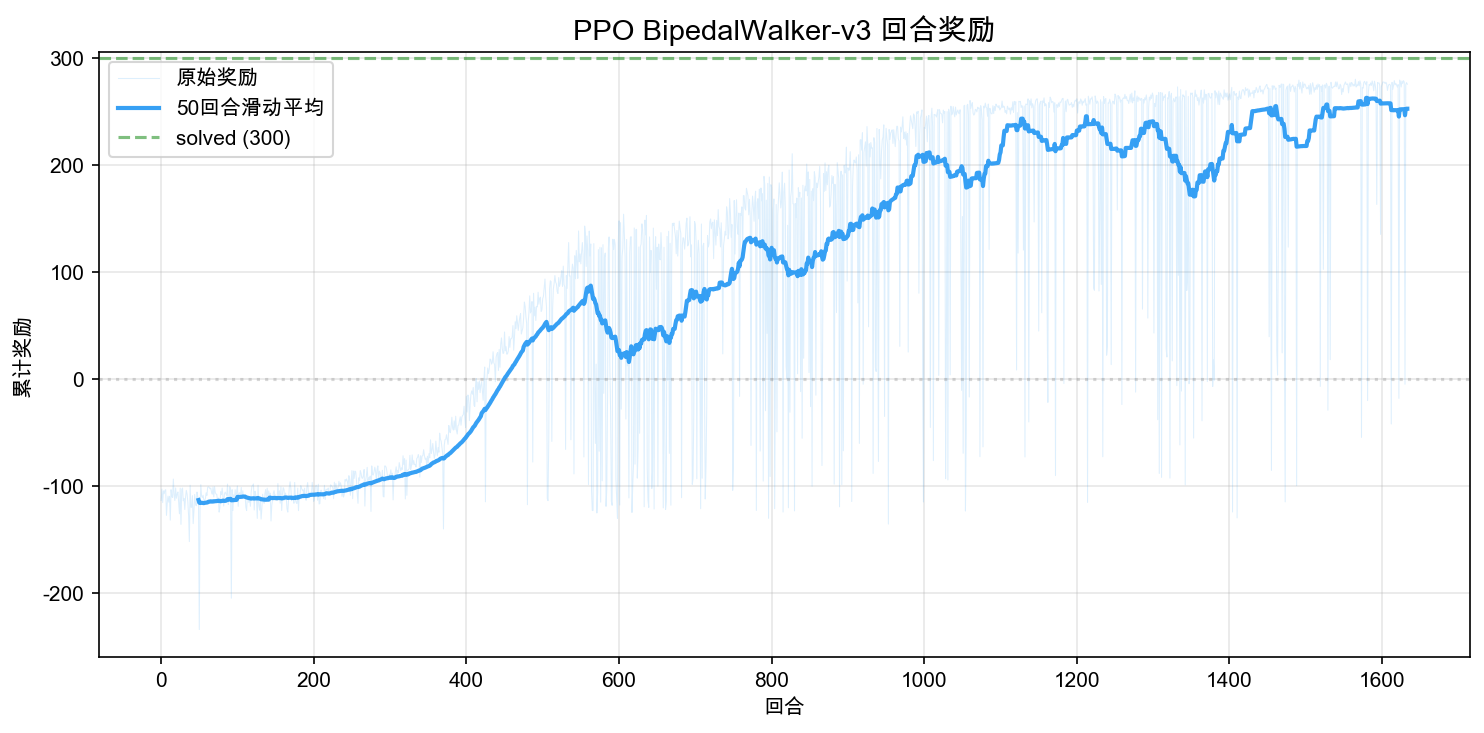
曲线的整体走势分为三个阶段:
- 前 200 回合(~250k 步):奖励在 -110 附近徘徊,策略几乎没学会任何东西,机器人每局都摔倒。这个阶段 PPO 在积累经验,还没找到有效的动作模式。
- 200-600 回合(250k-750k 步):曲线开始上升,从 -100 爬升到 +50 左右。策略开始区分"哪些动作组合不容易摔倒",偶尔出现正回报的回合。
- 600 回合之后(750k 步以后):奖励持续上升,从 50 升到 200 以上。策略已经形成了稳定的步态,进入逐步优化阶段。
注意浅蓝色的原始值波动非常大——相邻两个回合的奖励可以相差 200 分以上。这是 BipedalWalker 的特点:不同的初始扰动和地形会导致同一策略表现差异很大。所以看训练曲线时,应该关注滑动平均(深蓝色线)的趋势,而不是单个点的波动。
策略熵(Policy Entropy)
策略熵衡量策略输出的动作分布的"随机程度"。熵越高,说明策略对所有动作一视同仁,还在到处探索;熵越低,说明策略已经形成了明确的动作偏好。
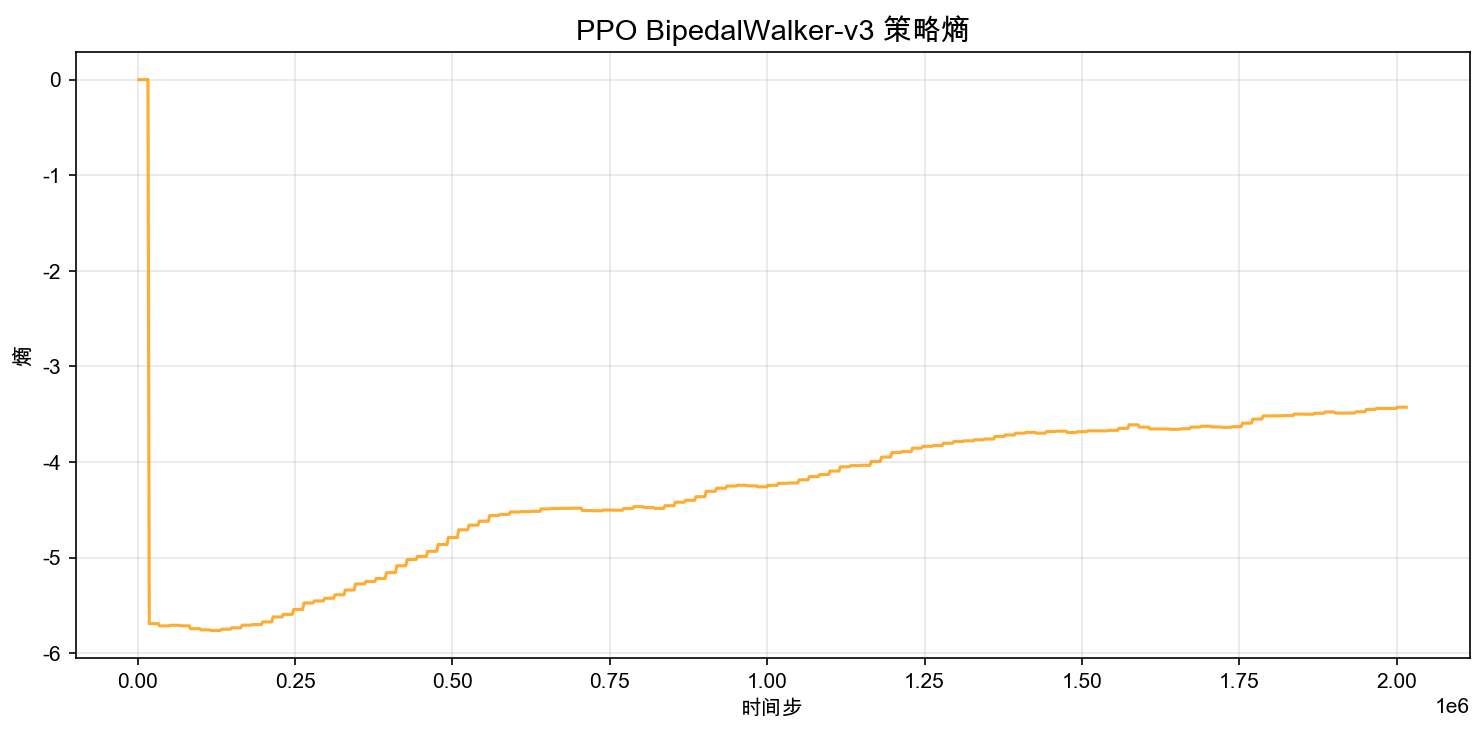
注意看 Y 轴:数值是负数,从 0 跌到 -5.8 再慢慢回升到 -3.5。这是 Stable-Baselines3 的记录惯例——它内部存的是 entropy_loss = -H(π),即负熵。要读出真实的策略熵,把 Y 轴数值取反即可。
翻译成实际含义:
- 训练刚开始(第一次更新后):熵 ≈ 5.8。策略输出的高斯分布标准差 很大,每个关节扭矩的采样范围很宽,动作看起来像随机扭动。
- 训练 2M 步后:熵 ≈ 3.5。标准差 缩小,动作越来越确定,策略"知道"该输出什么扭矩了。
- 整体趋势:熵从 5.8 缓慢下降到 3.5,这是正常的。策略在保留足够探索的同时,逐步聚焦到有效动作上。
如果熵下降太快(比如从 5.8 一下子掉到 1.0),说明策略过早放弃了探索,可能卡在局部最优——比如学会了"站着不动就不摔倒",但永远不尝试迈步。PPO 的 ent_coef 参数就是防止这种情况的:它在损失函数中加一个熵正则化项,即使策略想收敛,也会被迫保持一定程度的随机性。
裁剪比例(Clip Fraction)
裁剪比例是 PPO 最核心的监控指标。它表示在一次策略更新中,有多少比例的动作概率比率 超出了 的范围(本实验 )。
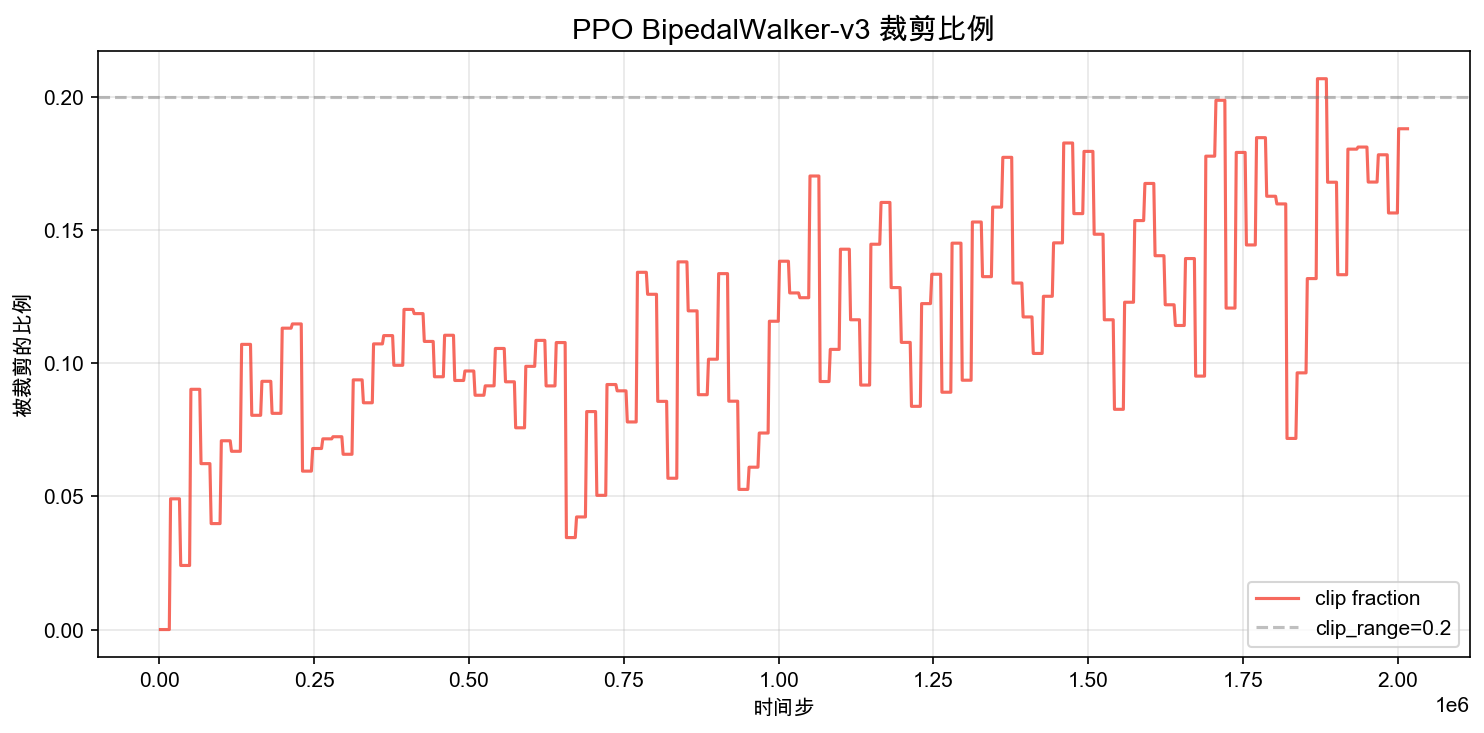
裁剪比例直接反映策略更新有多激进:
- 0.05-0.15:正常范围,策略在安全区间内稳步改进。
- > 0.2:更新过于激进,新旧策略差异太大,有策略崩溃的风险。这通常对应奖励跳水。
- 接近 0:更新太保守,策略几乎没有变化。如果此时奖励还很低,说明学习率可能太小。
从图上可以看到,训练初期裁剪比例波动较大(策略刚起步,每次更新变化大),中后期逐渐稳定在 0.1 附近。偶尔出现的小 spikes(比如超过 0.15)对应策略的小幅调整,只要不是持续高位就不用担心。
如果裁剪比例一直为 0,有两种可能:学习率太小导致策略几乎不更新,或者策略已经完全收敛。区分方法是看奖励是否还在增长。
近似 KL 散度(Approximate KL Divergence)
KL 散度 衡量新旧策略之间的差异程度。PPO 的裁剪机制本质上是在间接控制这个量——每次更新后,新策略不能偏离旧策略太远。
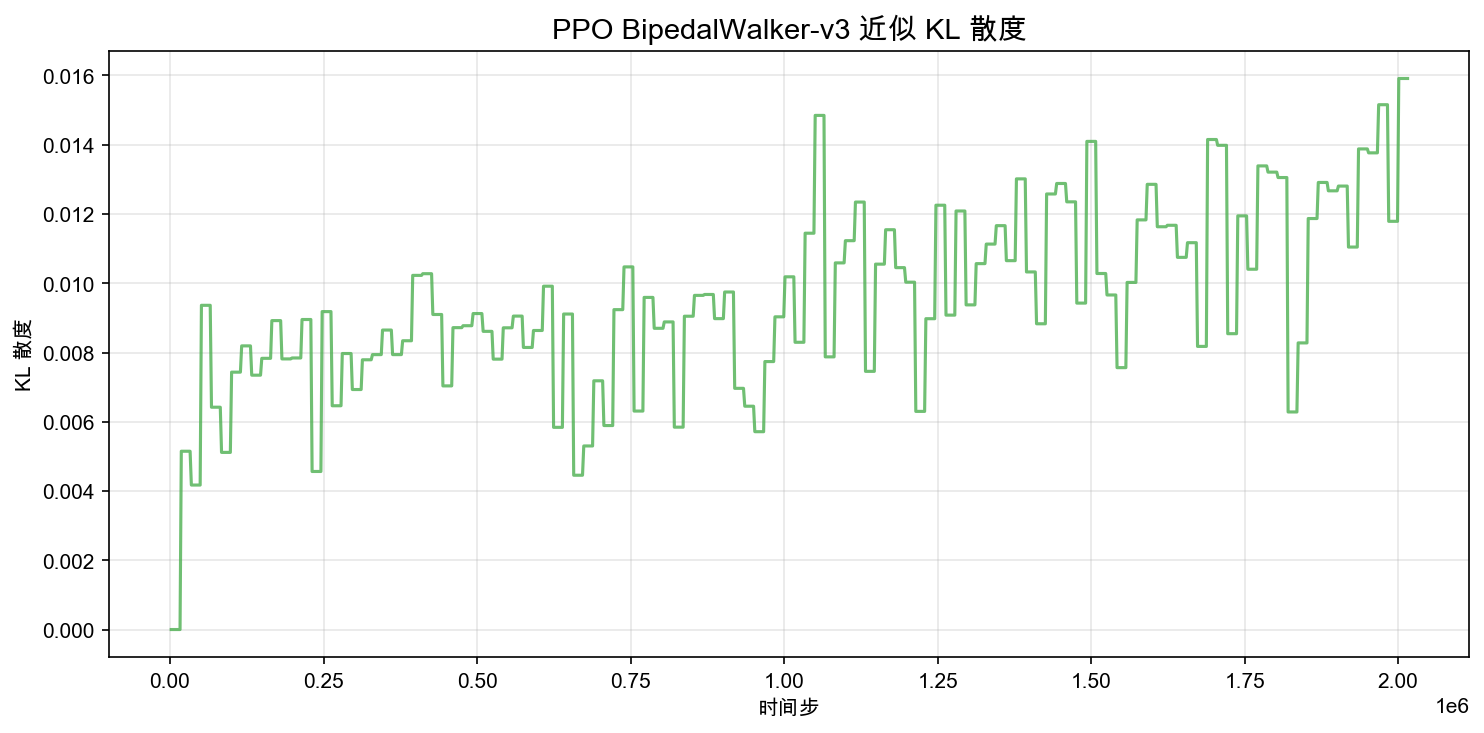
从图上看,KL 散度始终低于 0.016,整个训练过程中没有出现大幅飙升。这说明 PPO 的裁剪机制在 BipedalWalker 上工作良好——每次策略更新都把新旧策略的差异控制在一个安全的范围内。
如果把 KL 散度和裁剪比例放在一起看,会发现两者的走势高度相关:裁剪比例高的时候,KL 散度也偏高。这很自然——更多动作被裁剪 = 策略整体偏移更大。它们是同一个现象的两个视角:裁剪比例看的是"有多少动作被限制了",KL 散度看的是"策略分布整体移动了多少"。
KL 散度如果突然飙升到 0.05 以上,就说明某次更新把策略推得太远,这正是 PPO 想要避免的情况。本实验中没有出现这种情况。
四个指标的关联
这四个指标不是独立的,它们之间有明确的因果关系:
| 现象 | 奖励 | 策略熵 | 裁剪比例 | KL 散度 |
|---|---|---|---|---|
| 正常训练 | 逐步上升 | 缓慢下降 | 0.05-0.15 | 0.01-0.03 |
| 更新过猛 | 突然跳水 | 剧烈变化 | 飙升 > 0.2 | 飙升 > 0.05 |
| 过早收敛 | 停滞不动 | 接近 0 | 接近 0 | 接近 0 |
| 训练后期 | 稳定高位 | 稳定低位 | 稳定低位 | 稳定低位 |
奖励跳水几乎总是伴随着裁剪比例飙升和 KL 散度突增。这三个指标同时异常,就说明策略更新幅度过大,需要减小学习率或增大 n_steps(让每次 rollout 收集更多数据来稳定梯度估计)。
7.1.3 成功行走的判定标准
BipedalWalker-v3 的奖励由几个部分组成:
- 前进奖励:每步根据向右移动的距离给正奖励,走得越快越高。
- 关节效率惩罚:使用过大的关节扭矩会扣分,鼓励高效运动。
- 坠落惩罚:如果机器人摔倒(头部接触地面),扣 100 分并终止回合。
环境定义的"解决"标准是连续 100 个回合平均奖励 300。实际训练中,单回合得分可以这样理解:
- 300:高质量行走,速度快、姿态稳、效率高。
- 200-300:能走但不够稳,步态效率或速度还有问题。
- 100-200:勉强能走一段,经常摔倒。
- 100:基本没学会,大多数回合都摔倒。
先看随机策略的基线:
import gymnasium as gym
import numpy as np
env = gym.make("BipedalWalker-v3")
rng = np.random.default_rng(0)
returns = []
for ep in range(50):
obs, _ = env.reset(seed=ep)
total_reward = 0.0
for step in range(1600):
action = rng.uniform(-1, 1, size=4)
obs, reward, terminated, truncated, _ = env.step(action)
total_reward += reward
if terminated or truncated:
break
returns.append(total_reward)
print(f"随机策略平均回报: {np.mean(returns):.1f}")
print(f"最好一轮: {np.max(returns):.1f}")
print(f"最差一轮: {np.min(returns):.1f}")随机策略的平均回报大约在 -100 到 -50 之间,几乎所有回合都会摔倒(扣 100 分)。如果 PPO 训练后评估回报仍然在这个范围,说明策略没有学到任何有效行为。
一次运行的结果为:
随机策略平均回报: -46.3
最好一轮: -0.2
最差一轮: -100.07.1.4 训练三阶段回放
为了直观感受 PPO 的学习过程,我们对比同一训练配置下三个不同阶段的策略表现。三个模型使用完全相同的超参数,区别只在训练步数。
训练完成后,可以用渲染脚本生成回放 GIF:
python code/chapter07_ppo/render_bipedal_walker.py \
--model output/ppo_bipedal_walker.zip \
--output-dir output/bipedalwalker_episodes \
--episodes 10 --seeds 0 1 2 3 4 5 6 7 8 9早期(100k 步,回报 -50.8)
100k 步时策略几乎还没学到任何有效行为。机器人无法保持平衡,肢体胡乱扭动,1600 步耗尽也没有走出多远。负回报来自关节扭矩惩罚和缺乏前进距离。

中期(500k 步,回报 121.8)
500k 步时策略已经学会了基本的行走模式,但步态不协调。机器人能向前移动,但动作效率低、速度慢,经常需要修正姿态。100 分出头说明策略已经脱离了"摔倒"阶段,但离高效行走还有差距。

后期(2M 步,回报 300.2)
2M 步时策略已经形成了稳定高效的步态。关节协调流畅,1096 步就完成了行走(100k 和 500k 阶段都需要跑满 1600 步)。

三个阶段的评估对比(20 回合平均):
| 训练步数 | 平均奖励 | 标准差 | 表现 |
|---|---|---|---|
| 100k | -63.9 | 25.2 | 肢体失控,无法站立 |
| 500k | 108.5 | 6.8 | 能走但不稳,步态不协调 |
| 2M | 282.5 | 59.7 | 稳定高效行走 |
PPO 在连续控制任务上的学习轨迹:先学会"不摔倒"(100k),再学会"勉强行走"(500k),最后形成"高效步态"(2M)。这个过程比离散控制任务更慢,但阶段边界更清晰,因为连续动作空间的策略空间更大,每个阶段都需要积累更多数据才能突破。
7.1.5 状态、动作与连续策略
BipedalWalker 的 24 维状态可以分成几组:
| 状态分量 | 维度 | 含义 |
|---|---|---|
hull_angle | 1 | 躯干倾斜角 |
hull_angular_velocity | 1 | 躯干角速度 |
vx, vy | 2 | 躯干水平/垂直速度 |
hip1, hip2 | 2 | 两条腿的髋关节角度 |
knee1, knee2 | 2 | 两条腿的膝关节角度 |
leg1_contact, leg2_contact | 2 | 两只脚是否接触地面 |
lidar[0..9] | 10 | 激光雷达测距(探测前方地形) |
hip_speed1, hip_speed2 | 2 | 髋关节角速度 |
knee_speed1, knee_speed2 | 2 | 膝关节角速度 |
动作是 4 维连续向量,每个分量在 之间:
| 动作分量 | 含义 |
|---|---|
action[0] | 腿 1 髋关节扭矩 |
action[1] | 腿 1 膝关节扭矩 |
action[2] | 腿 2 髋关节扭矩 |
action[3] | 腿 2 膝关节扭矩 |
PPO 处理连续动作的方式和处理离散动作不同。在离散动作空间中,策略网络输出每个动作的概率,然后从中采样。在连续动作空间,策略网络输出一个高斯分布——均值 和标准差 ,然后从 中采样得到动作:
这意味着 PPO 不需要把连续动作离散化成有限个选择。对于关节扭矩这种需要精细控制的量,离散化会导致分辨率损失:如果只允许 -1、0、+1 三档扭矩,机器人会非常笨拙。连续策略可以直接输出 0.37 或 -0.82 这样的精细值,控制精度远高于离散化方案。
BipedalWalker 的学习过程通常经历三个阶段:
- 站立(0-200k 步):策略先学会不摔倒。这个阶段奖励从 -100 缓慢上升到 0 附近,机器人从"一启动就倒"变成"能勉强站着"。
- 挪步(200k-600k 步):策略开始试探性地迈步,但步态不协调,经常走几步就摔倒。奖励波动剧烈,偶尔出现 100 分以上的回合。
- 行走(600k 步以后):步态逐步成型,行走越来越稳。2M 步后奖励可以稳定在 295-302 的窄区间内。
这三个阶段不是严格划分的,不同训练 run 的边界会偏移。但整体趋势是:先学会"不摔倒",再学会"迈步",最后学会"高效行走"。
7.1.6 常见失败与调参
BipedalWalker 比常见离散动作环境更容易训练失败。如果结果不理想,按以下顺序排查。
第一,确认训练步数是否足够。100 万步是起点,不是终点。如果曲线还在上升但斜率不够,可以继续训练:
from stable_baselines3 import PPO
model = PPO.load("output/ppo_bipedal_walker.zip")
model.learn(total_timesteps=2_000_000, reset_num_timesteps=False)第二,确认 batch_size 是否够大。连续动作空间的梯度方差比离散空间高,batch_size=64 可能不够稳定。本节使用 256,如果训练曲线仍然剧烈震荡,可以尝试 512。
第三,检查策略熵。如果熵在训练早期就快速降到接近零,说明策略过早收敛到次优行为(比如一直站着不动)。可以适当增大 ent_coef 到 0.01。
第四,考虑网络容量。默认的 MlpPolicy 使用两层 64 个神经元的网络。对于 24 维状态,这个容量可能不够。可以通过 policy_kwargs 增大网络:
model = PPO(
policy="MlpPolicy",
policy_kwargs=dict(net_arch=[128, 128]),
...
)常见超参数参考:
| 参数 | 本节设置 | 如果不合适会怎样 |
|---|---|---|
learning_rate | 3e-4 | 太大会让关节扭矩输出剧烈震荡,太小学得很慢 |
batch_size | 256 | 太小梯度估计不稳定,太大单次更新太慢 |
n_steps | 2048 | 太少每次 rollout 数据不够,太多延迟策略更新频率 |
ent_coef | 0.005 | 太小策略过早收敛到站着不动,太大始终无法形成稳定步态 |
clip_range | 0.2 | 太大步态突变导致摔倒,太小训练停滞 |
gamma | 0.99 | 太低只关注短期不摔,忽略长期行走效率 |
7.1.7 为什么选择 BipedalWalker
BipedalWalker 在教学上有几个关键优点:
- 连续动作空间。BipedalWalker 用 4 维连续扭矩控制关节。这正是 PPO 相对于 DQN 的核心优势所在——DQN 无法直接处理连续动作,必须先离散化,而 PPO 通过高斯策略原生支持。
- 更丰富的状态空间。24 维状态中包含 10 个激光雷达测距信号,这是对真实机器人传感器(激光雷达、触觉传感器)的简化模拟。智能体必须从这些传感器数据中推断地形变化,而不是简单地读取位置坐标。
- 更复杂的学习动态。BipedalWalker 需要发现一个完整的步态周期,涉及多关节协调、重心转移和地形适应。策略不是简单地在少数动作之间切换,而是在连续空间中形成稳定的运动模式。
从 CartPole(第 5 章)到 BipedalWalker,实验的难度和真实性明显提升。但 PPO 的核心机制没有变:裁剪约束更新幅度,多轮复用同一批数据,Actor-Critic 同时优化策略和价值。复杂度的提升来自环境和任务,而不是算法本身。
下一节将拆解 PPO 背后的数学推导——PPO 数学推导。
本节小结
BipedalWalker-v3直接展示连续动作空间下的 PPO:4 维连续扭矩、24 维状态、随机地形。- PPO 通过高斯策略(输出均值和标准差,从中采样)原生支持连续动作,不需要离散化。
- BipedalWalker 的学习过程通常经历"站立→挪步→行走"三个阶段,训练步数需求远高于常见离散动作任务。
- 本节使用 Stable-Baselines3 的 PPO 实现,训练入口是
code/chapter07_ppo/ppo_bipedal_walker.py,回放 GIF 用render_bipedal_walker.py。 - 环境定义的"解决"标准是 100 回合平均奖励 300;本节 2M 步训练达到 296.03 ± 1.65,非常接近 solved 阈值。